算术运算符
算术运算
- + 加
- - 减
- * 乘
- / 除
- % 取模(相除后的余数)
- ** 取幂(注意 ^ 并不执行该运算,你可能在其他语言中见过这种情形)
- // 相除后向下取整到最接近的整数
备注: 可以使用 科学记数法来定义很大的数字。4.445e8 等于 4.445 * 10 ** 8,也就是 444500000.0。
变量I
mv_population = 74728
mv_population 是变量,负责存储 74728 的值。该表达式将右侧的项目赋值给左侧的名称,实际上和数学等式有所不同,因为74728 不存储 mv_population 的值。
在任何情况下,无论左侧项是什么,在赋值后,都是右侧值的变量名称。一旦将变量值赋值给变量名称,你便可以通过该名称访问这个值。
更改变量
更改变量会如何影响到用该变量定义的另一个变量?我们来看一个示例。
这是关于山景城人口和人口密度的原始数据。
>>> mv_population = 74728
>>> mv_area = 11.995
>>> mv_density = mv_population/mv_area
现在我们重新定义 mv_population 变量:
(注意:后续代码跟在上面三行代码后面,而非重新开始)
>>> mv_population = 75000
思考一下上方的代码,下面的表达式输出会是什么?
>>> print(int(mv_density))
正确答案是 int(mv_density)的值没有变化。它依然是 6229。
因为当变量被赋值时,赋给了右侧的表达式的值,而不是表达式本身。在下面的行中:
>>> mv_density = mv_population/mv_area
Python 实际上计算了右侧表达式 mv_population/mv_area 的结果,然后将变量 mv_density 赋为该表达式的值。它立即忘记该公式,仅将结果保存到变量中。
考虑到 mv_population 的变化,为了更新 mv_density 的值。我们需要再次运行下面这行:
>>> mv_density = mv_population/mv_area
>>> print(int(mv_density))
6252
变量II
以下两个表达式在赋值方面是对等的:
x = 3
y = 4
z = 5
以及
x, y, z = 3, 4, 5
但是,在大多数情况下,上面的表达式并不是很好的赋值方式,因为变量名称应该要能够描述所存储的值。
除了要设定具有描述性的变量名称之外,在 Python 中命名变量时,还需要注意以下几个事项:
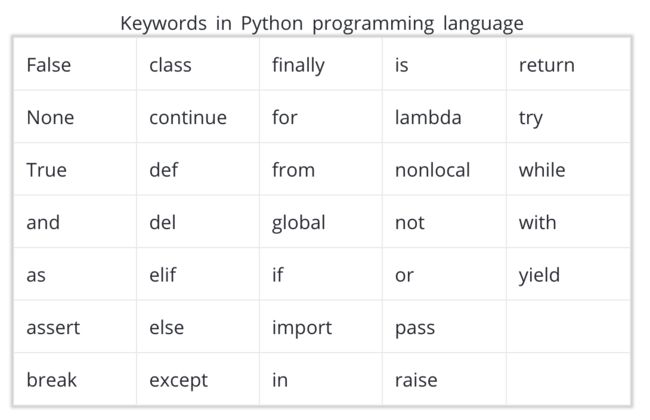
1. 只能在变量名称中使用常规字母、数字和下划线。不能包含空格,并且需要以字母或下划线开头。
2. 不能使用保留字或内置标识符,它们在 Python 中具有重要含义,你将在整个这门课程中学到这些知识。python 保留字列表请参阅此处。创建对值清晰描述的名称可以帮助你避免使用这些保留字。下面是这些保留字的简要表格。
3. 在 python 中,变量名称的命名方式是全部使用小写字母,并用下划线区分单词。
正确
my_height = 58
my_lat = 40
my_long = 105
错误
my height = 58
MYLONG = 40
MyLat = 105
虽然最后两个在 python 中可以运行,但是它们并不是在 python 中命名变量的推荐方式。我们命名变量的方式称之为snake case,因为我们用下划线连接单词。
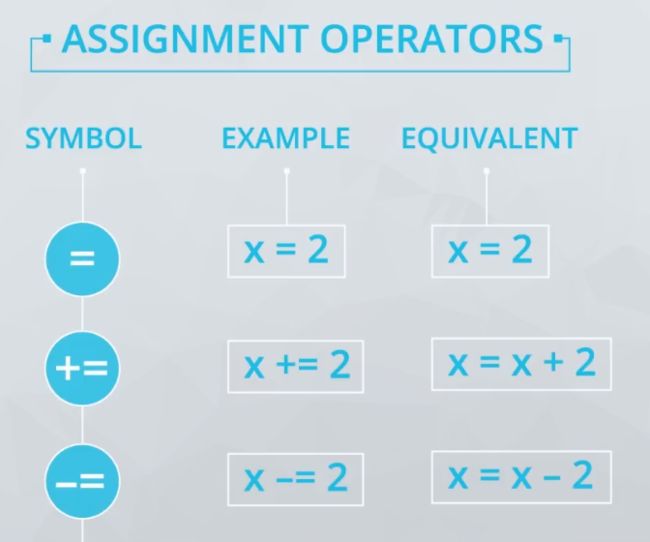
赋值运算符
还可以按照类似的方式使用 *=,但是与下方所示的运算符相比不太常见。
整数和浮点数
数字值可以用到两种 python 数据类型:
- int - 表示整数值
- float - 表示小数或浮点数值
通过以下语法创建具有某个数据类型的值:
x = int(4.7) # x is now an integer 4
y = float(4) # y is now a float of 4.0
使用函数 type 检查数据类型:
>>> print(type(x))
int
>>> print(type(y))
float
因为 0.1 的浮点数(或近似值)实际上比 0.1 稍微大些,当我们将好几个这样的值相加时,可以看出在数学上正确的答案与 Python 生成的答案之间有区别。
>>> print(.1 + .1 + .1 == .3)
False
PEP8 指南
- 示例1:
正确
print(4 + 5)
错误
print( 4 + 5)
- 示例2:
正确
print(3 * 7)
错误
print( 3 * 7 )
- 示例3:
正确
print(3*7 - 1)
错误
print(3 * 7 - 1)
如何遵守标准样式指南使代码更容易阅读,并且在团队内的不同开发者之间保持一致。要了解所有的最佳做法,请参阅 PEP8 指南
异常
异常是代码运行时发生的问题,而语法错误是 Python 在运行代码之前检查代码时发现的问题。要了解详情,请参阅关于错误和异常的 Python 教程页面。
布尔型运算符、比较运算符和逻辑运算符
布尔数据类型存储的是值 True 或 False,通常分别表示为 1 或0。
通常有 6 个比较运算符会获得布尔值:
比较运算符
| 符号使用情况 | 布尔型 | 运算符 |
|---|---|---|
| 5 < 3 | False | 小于 |
| 5 > 3 | True | 大于 |
| 3 <= 3 | True | 小于或等于 |
| 3 >= 5 | False | 大于或等于 |
| 3 == 5 | False | 等于 |
| 3 != 5 | True | 不等于 |
逻辑运算符
| 逻辑使用情况 | 布尔型 | 运算符 |
|---|---|---|
5 < 3 and 5 == 5 |
False | and - 检查提供的所有语句是否都为 True |
5 < 3 or 5 == 5 |
True | or - 检查是否至少有一个语句为 True |
not 5 < 3 |
True | not- 翻转布尔值 |
字符串
定义字符串
在 python 中,字符串的变量类型显示为str。使用双引号"或单引号'定义字符串。如果你要创建的字符串包含其中一种引号,你需要确保代码不会出错。
>>> my_string = 'this is a string!'
>>> my_string2 = "this is also a string!!!"
你还可以在字符串中使用 \,以包含其中一种引号:
>>> this_string = 'Simon\'s skateboard is in the garage.'
>>> print(this_string)
Simon's skateboard is in the garage.
如果不使用 \,注意我们遇到了以下错误:
>>> this_string = 'Simon's skateboard is in the garage.'
File "", line 1
this_string = 'Simon's skateboard is in the garage.'
^
SyntaxError: invalid syntax
字符串连接
>>> first_word = 'Hello'
>>> second_word = 'There'
>>> print(first_word + second_word)
HelloThere
>>> print(first_word + ' ' + second_word)
Hello There
>>> print(first_word * 5)
HelloHelloHelloHelloHello
类型和类型转换
四种数据类型:
1.整型
2.浮点型
3.布尔型
4.字符串
>>> print(type(4))
int
>>> print(type(3.7))
float
>>> print(type('this'))
str
>>> print(type(True))
bool
可以更改变量类型以执行各种不同的操作。例如
# ex1
In [1]: "0" + "5"
Out[1]: '05'
# ex2
In [2]: 0 + 5
Out[2]: 5
# ex3
In [3]: "0" + 5
----> "0" + 5
TypeError: must be str, not int
因此要让ex3正确执行, 需要将字符0转换为整型
#ex3
In [3]: int("0") + 5
Out[3]: 5
同理, 对于数字也可以通过str()进行转换, 来执行字符串操作.
字符串方法
方法就像某些已经见过的函数:
1.len("this")
2.type(12)
3.print("Hello world")
上述三项都是函数。注意,它们使用了小括号并接受一个参数。
type 和print 函数可以接收字符串、浮点型、整型和很多其他数据类型的参数,函数 len 也可以接受多种不同数据类型的参数
下图显示了任何字符串都可以使用的方法。

每个方法都接受字符串本身作为该方法的第一个参数。但是,它们还可以接收其他参数。
>>> my_string = 'rick sanchez'
>>> my_string.islower()
True
>>> my_string.count('a')
1
>>> my_string.find('a')
6
>>> my_string.split()
['rick', 'sanchez']
其他方法
string.replace('old_char','new_char')`
string.capitalize() #一句话中第一个字母大写
要详细了解字符串和字符串方法,请参阅字符串方法文档。
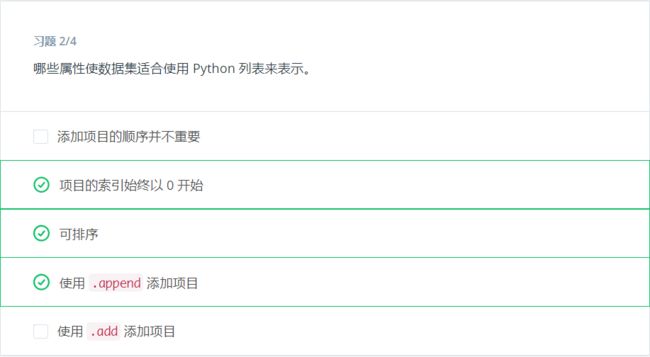
列表
创建列表
使用方括号创建列表。列表可以包含任何数据类型并且可以混合到一起。
lst_of_random_things = [1, 3.4, 'a string', True]
这是一个包含 4 个元素的类别。
获取元素
在 python 中,所有有序容器(例如列表)的起始索引都是 0。因此,要从上述列表中获取第一个值,我们可以编写以下代码:
>>> lst_of_random_things[0]
1
似乎你可以使用以下代码获取最后一个元素,但实际上不可行:
>>> lst_of_random_things[len(lst_of_random_things)]
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
in ()
----> 1 list[len(list)]
IndexError: list index out of range
但是,你可以通过使索引减一获取最后一个元素。因此,你可以执行以下操作:
>>> lst_of_random_things[len(lst_of_random_things) - 1]
True
此外,你可以使用负数从列表的末尾开始编制索引,其中 -1 表示最后一个元素,-2 表示倒数第二个元素,等等。
>>> lst_of_random_things[-1]
True
>>> lst_of_random_things[-2]
a string
列表切片
使用切片功能从列表中提取多个值。在使用切片功能时,务必注意,下限索引包含在内,上限索引排除在外。
因此:
>>> lst_of_random_things = [1, 3.4, 'a string', True]
>>> lst_of_random_things[1:2]
[3.4]
仅返回列表中的 3.4。
注意,这与单个元素索引依然不同,因为你通过这种索引获得了一个列表。冒号表示从冒号左侧的起始值开始,到右侧的元素(不含)结束。
如果你要从列表的开头开始,也可以省略起始值。
>>> lst_of_random_things[:2]
[1, 3.4]
或者你要返回到列表结尾的所有值,可以忽略最后一个元素。
>>> lst_of_random_things[1:]
[3.4, 'a string', True]
这种索引和字符串索引完全一样,返回的值将是字符串。
成员运算符
可以使用 in 和 not in 返回一个布尔值,表示某个元素是否存在于列表中,或者某个字符串是否为另一个字符串的子字符串。
>>> 'this' in 'this is a string'
True
>>> 'in' in 'this is a string'
True
>>> 'isa' in 'this is a string'
False
>>> 5 not in [1, 2, 3, 4, 6]
True
>>> 5 in [1, 2, 3, 4, 6]
False
可变性和顺序
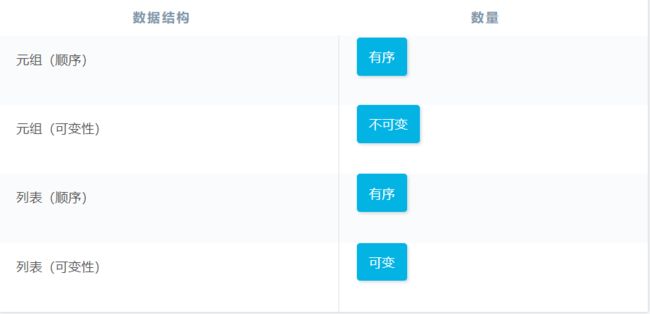
可变性是指对象创建完毕后,是否可以更改该对象。如果对象(例如列表或字符串)可以更改,则是可变的。但是,如果无法更改对象以创建全新的对象(例如字符串),则该对象是不可变的。
>>> my_lst = [1, 2, 3, 4, 5]
>>> my_lst[0] = 'one'
>>> print(my_lst)
['one', 2, 3, 4, 5]
正如上述代码所显示的,你可以将上述列表中的 1 替换为 'one。这是因为,列表是可变的。
但是,以下代码不可行:
>>> greeting = "Hello there"
>>> greeting[0] = 'M'
这是因为,字符串是不可变的。意味着如果要更改该字符串,你需要创建一个全新的字符串。
对于你要使用的每种数据类型,你都需要注意两个事项:
- 可变吗?
- 有序吗?
字符串和列表都是有序的。
列表方法
-
len()返回列表中的元素数量。 -
max()返回列表中的最大元素。最大元素的判断依据是列表中的对象类型。
数字列表中的最大元素是最大的数字。
字符串列表中的最大元素是按照字母顺序排序时排在最后一位的元素。
因为 max() 函数的定义依据是大于比较运算符。如果列表包含不同的无法比较类型的元素,则 max() 的结果是 undefined。 -
min()返回列表中的最小元素。它是 max() 函数的对立面,返回列表中的最小元素。 -
sorted()返回一个从最小到最大排序的列表副本,并使原始列表保持不变。
join 方法
Join 是一个字符串方法,将字符串列表作为参数,并返回一个由列表元素组成并由分隔符字符串分隔的字符串。
new_str = "\n".join(["fore", "aft", "starboard", "port"])
print(new_str)
输出:
fore
aft
starboard
port
在此示例中,我们使用字符串 "\n"作为分隔符,以便每个元素之间都有一个换行符。我们还可以在 .join 中使用其他字符串作为分隔符。以下代码使用的是连字符。
name = "-".join(["García", "O'Kelly"])
print(name)
输出:
García-O'Kelly
请务必注意,用英文逗号 (,) 将要连接的列表中的每项分隔开来。忘记分隔的话,不会触发错误,但是会产生意外的结果。
append 方法
实用方法 append 会将元素添加到列表末尾。
letters = ['a', 'b', 'c', 'd']
letters.append('z')
print(letters)
输出:
['a', 'b', 'c', 'd', 'z']
元组
元组是另一个实用容器。它是一种不可变有序元素数据类型。通常用来存储相关的信息。
定义元组
location = (13.4125, 103.866667)
length, width, height = 52, 40, 100
在定义元组时,小括号是可选的,如果小括号并没有对解释代码有影响,程序员经常会忽略小括号。
元组索引
元组和列表相似,它们都存储一个有序的对象集合,并且可以通过索引访问这些对象。但是与列表不同的是,元组不可变,你无法向元组中添加项目或从中删除项目,或者直接对元组排序。
元组解包
dimensions = 52, 40, 100
length, width, height = dimensions
print("The dimensions are {} x {} x {}".format(length, width, height))
在第二行,我们根据元组 dimensions 的内容为三个变量赋了值。这叫做元组解包。你可以通过元组解包将元组中的信息赋值给多个变量,而不用逐个访问这些信息,并创建多个赋值语句。
如果我们不需要直接使用 dimensions,可以将这两行代码简写为一行,一次性为三个变量赋值!
length, width, height = 52, 40, 100
print("The dimensions are {} x {} x {}".format(length, width, height))
可变性&有序性总结
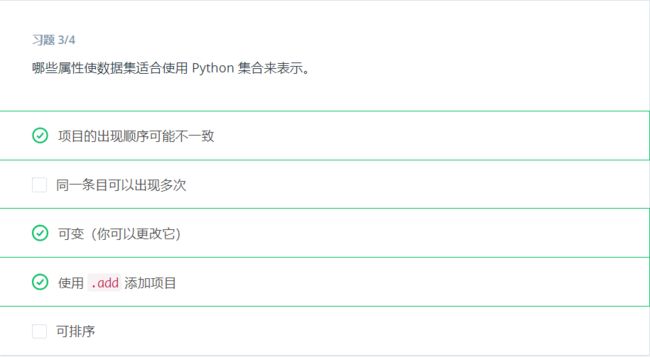
集合
集合是一个包含唯一元素的可变无序集合数据类型。集合的一个用途是快速删除列表中的重复项。
定义集合
#method 1
numbers = [1, 2, 6, 3, 1, 1, 6]
unique_nums = set(numbers)
#method 2
fruit = {"apple", "banana", "orange", "grapefruit"}
集合方法
集合和列表一样支持in 运算符。和列表相似,你可以使用 add 方法将元素添加到集合中,并使用 pop 方法删除元素。但是,当你从集合中拿出元素时,会随机删除一个元素。注意和列表不同,集合是无序的,因此没有“最后一个元素”。
fruit = {"apple", "banana", "orange", "grapefruit"} # define a set
print("watermelon" in fruit) # check for element
fruit.add("watermelon") # add an element
print(fruit)
print(fruit.pop()) # remove a random element
print(fruit)\
输出结果为:
False
{'grapefruit', 'orange', 'watermelon', 'banana', 'apple'}
grapefruit
{'orange', 'watermelon', 'banana', 'apple'}
可以对集合执行的其他操作包括可以对数学集合执行的操作。可以对集合轻松地执行 union、intersection 和 difference 等方法,并且与其他容器相比,速度快了很多。
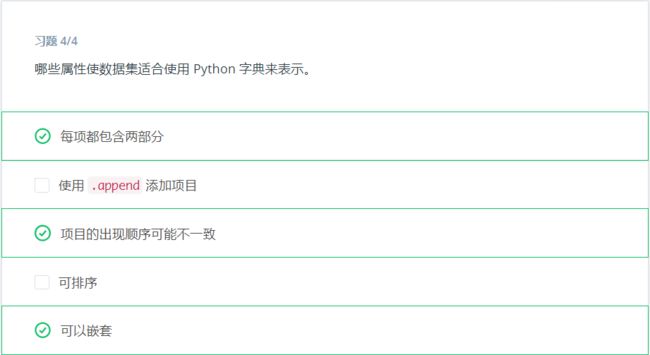
字典
字典是可变数据类型,其中存储的是唯一键到值的映射。下面是存储元素和相应原子序数的字典。
elements = {"hydrogen": 1, "helium": 2, "carbon": 6}
创建字典
字典的键可以是任何不可变类型,例如整数或元组,而不仅仅是字符串。甚至每个键都不一定要是相同的类型!
查询字典
- 使用方括号并在括号里放入键,查询字典中的值或向字典中插入新值。
print(elements["helium"]) # print the value mapped to "helium"
elements["lithium"] = 3 # insert "lithium" with a value of 3 into the dictionary
可以像检查某个值是否在列表或集合中一样,使用关键字
in检查值是否在字典中。get会在字典中查询值,但是和方括号不同,如果没有找到键,get会返回None(或者你所选的默认值)。
print("carbon" in elements)
print(elements.get("dilithium"))
输出结果为:
True
None
Carbon 位于该字典中,因此输出 True。Dilithium 不在字典中,因此 get 返回 None,然后系统输出 None。如果你预计查询有时候会失败,get 可能比普通的方括号查询更合适,因为错误可能会使程序崩溃。
插入新值
使用方括号并在括号里放入键, 对其进行赋值.
week = {}
week['Monday'] = 1
删除值
del(week['Monday'] )
恒等运算符
| 关键字 | 运算符 |
|---|---|
| is | 检查两边是否恒等 |
| is not | 检查两边是否不恒等 |
你可以使用运算符 is 检查某个键是否返回了 None。或者使用 is not 检查是否没有返回 None。
n = elements.get("dilithium")
print(n is None)
print(n is not None)
会输出:
True
False
思考: 以下代码的输出是什么?
a = [1, 2, 3]
b = a
c = [1, 2, 3]
print(a == b)
print(a is b)
print(a == c)
print(a is c)
结果应该为:
True
True
True
False
解析: 列表 a 和列表 b 是对等和相同的。列表 c 等同于 a(因此等同于 b),因为它们具有相同的内容。但是 a 和 c(同样 b 也是)指向两个不同的对象,即它们不是相同的对象。这就是检查是否相等与恒等的区别。
复合数据结构
我们可以在其他容器中包含容器,以创建复合数据结构。例如,下面的字典将键映射到也是字典的值!
elements = {"hydrogen": {"number": 1,
"weight": 1.00794,
"symbol": "H"},
"helium": {"number": 2,
"weight": 4.002602,
"symbol": "He"}}
我们可以如下所示地访问这个嵌套字典中的元素。
helium = elements["helium"] # get the helium dictionary
hydrogen_weight = elements["hydrogen"]["weight"] # get hydrogen's weight
练习