TensorFlow实战Google深度学习框架
TensorFlow是谷歌2015年开源的主流深度学习框架。科技届的聚光灯已经从“互联网+”转到了“AI+”;
掌握深度学习需要较强的理论功底,用好TensorFlow又需要足够的实践和解析。TensorFlow的库非常的丰富。
TensorFlow不同版本的示例程序代码库:
http://github.com/caicloud/tensorflow-tutorial
TensorFlow官方文档中文版
http://www.tensorfly.cn/tfdoc/api_docs/python/framework.html
https://www.w3cschool.cn/tensorflow_python/
《Machine Learning》中对机器学习的定义:”如果一个程序可以在任务T上,随着经验E的增加,效果P也可以随之增加,则称这个程序可以从经验中学习。“(逻辑回归算法:训练数据以及数据特征提取)(数据处理:实体数据的表达和特征提取)
人工的方式无法很好地抽取实体中的特征。深度学习解决了这个核心问题:自动的将简单的特征组合成更加复杂的特征,并使用这些组合特征解决问题。
深度学习是机器学习的一个分支,它除了可以学习特征和任务之间的关联,还能自动的一层一层从简单特征中提取更加复杂的特征。学术机构的机器学习领域被分为了:1、自然语言处理;2、计算机视觉;3、语音识别;等等
人工智能是一类非常广泛的问题,机器学习是解决这类问题的一个重要手段,深度学习则是机器学习的一个分支。
在自然语言处理领域,使用深度学习实现智能特征提取的一个非常重要的技术是单词向量(Word embedding)。单词向量是深度学习解决很多上述自然语言处理问题的基础。为了使计算机能更好的理解自然语言所表达的语义,研究人员人工建立了大量的语料库(WordNet、ConceptNet、FrameNet)
在Google内部,TensorFlow已经被成功应用到语音搜索、广告、图片、街景图、翻译、YouTube等众多产品中。基于TensorFlow开发的RankBrain排序算法在谷歌上千排序算法中排第三重要的位置,TensorFlow的活跃度也远远超过大部分其他工具。
TensorFlow环境的搭建:
1、TensorFlow的主要依赖包:Protocol Buffer 和 Bazel 工具包。
Protocol Buffer 是谷歌开发的结构化数据的工具。结构化数据指:拥有多种属性的数据。将这些结构化的数据信息持久化或者进行网络传输时,就需要先将它们序列化(即将结构化的数据变成数据流的格式,即字符串)。将结构化的数据序列化,并从序列化的数据流中还原出原来的结构化数据,称为处理结构化数据,即Protocol Buffer解决的主要问题。除此之外还有XML和JSON两种比较常用的结构化数据处理工具,但有比较大的差别(Protocol Buffer序列化之后的数据不是可读的字符串,而是二进制流。其次XML或JSON格式的数据信息都包含在了序列化之后的数据中,不需要任何其他信息就能还原序列化后的数据。但使用Protocol BUffer时需要先定义数据的格式(schema)。还原一个序列化后的数据将需要使用到这个定义好的数据格式。Protocol Buffer序列化出来的数据要比XML格式的数据小3-10倍,解析时间要快20-100倍。
#XML格式
张三
12345
[email protected]
#JSON格式
{
"name":"张三",
"id":"12345",
"email":"[email protected]",
}
#Protocol Buffer定义数据格式的文件一般保存在.proto文件中。每一个#message代表了一类结构化的数据。
message user{
optional string name = 1 ;
required int32 id = 2 ;
repeated string email = 3 ;
}
"""属性可以是:
必需的(required):message的所有实例都需要有这个属性。
可选的(optional):这个属性的取值可以为空。
可重复的(repeated):这个属性的取值可以是一个列表。
gRPC :分布式TensorFlow的通信协议。以Protocol Buffer为基础。
Bazel:从谷歌开源的自动化构建工具,Google内部绝大部分的应用都是通过它来编译的。在速度、可伸缩性、灵活性以及对不同语言和平台的支持上都要比其他传统的(Makefile、Ant、Maven)出色。
Bazel的编译方式是事先定义好的。其中对Python的支持的编译方式有三种:
py_binary 将Python程序编译为可执行文件。
py_test 编译Python测试程序。
py_library 将Python程序编译成库函数供其他py_binary或py_test调用。
TensorFlow的安装:
1、使用Docker安装:Docker是新一代的虚拟化技术,它可以将TensorFlow以及TensorFlow的所有依赖关系统一封装到Docker镜像中,极大简化了安装过程,支持大部分操作系统。
安装完Docker后,使用命令启动TensorFlow容器。在第一次运行时,Docker会自动下载镜像。
$ docker run -it tensorflow/tensorflow:1.4.0
虽然支持GPU的Docker镜像,但是要运行这些镜像需要安装最新的NVIDIA驱动以及nvidia-docker。在安装运行完成ncidia-docker之后,可以通过命令支持GPU的TensorFlow镜像
$ nvidia-docker run -it tensorflow/tensorflow:1.4.0-gpu
2、通过pip 安装:略
TensorFlow测试样例:
Python 3.6.5rc1 (v3.6.5rc1:f03c5148cf, Mar 14 2018, 03:12:11) [MSC v.1913 64 bit (AMD64)] on win32
Type "copyright", "credits" or "license()" for more information.
>>> import tensorflow as tf #加载TensorFlow,并重命名tf
>>> a = tf.constant([1.0,2.0], name = "a")
>>> b = tf.constant([2.0,3.0], name = "b") #定义两个常向量,a,b
>>> result = a + b #两个向量相加
>>> sess = tf.session()#要输出相加的结果,不能简单的直接输出result
Traceback (most recent call last):
File "", line 1, in
sess = tf.session()#要输出相加的结果,不能简单的直接输出result
AttributeError: module 'tensorflow' has no attribute 'session'
>>> sess = tf.Session()#要输出相加的结果,不能简单的直接输出result
>>> sess.run(result)
array([3., 5.], dtype=float32)
>>> TensorFlow的计算模型、数据模型和运行模型:
TensorFlow ----Tensor 和 Flow,Tensor即张量(多维数组:表明了它的数据结构),Flow即流(体现了它的计算模型,直观的表达了张量之间通过计算相互转化的过程)。TensorFlow是一个通过计算图的形式来表达计算的编程系统,其中的每一个计算都是计算图上的一个节点,而节点之间的边描述了计算之间的依赖关系。
TensorFlow程序一般分为两个阶段:
1、需要定义计算图中所有的计算。
2、执行计算。
张量的使用:第一类用途是对中间计算结果的引用。第二类是当计算图构造完成后,张量可以用来获得计算结果。
TensorFlow的运行模型-会话
TensorFlow中的会话(session)来执行定义好的运算。会话拥有并管理TensorFlow程序运行时的所有资源。所有计算完成之后需要关闭会话来帮助系统回收资源,否则就可能出现资源泄漏的问题。
TensorFlow使用会话的两种模式:
1、需要明确调用tf.Session()会话生成函数和调用Session.close()关闭会话函数,并释放资源。(对于异常退出时资源的释放问题,TensorFlow可以通过Python的上下文管理器来使用会话(即将所有的计算放在“with”的内部,当上下文管理器退出的时候会自动释放所有的资源)
2、TensorFlow不会自动生成默认会话,而是需要手动指定。
with sess.as_default():#第一种设置方式
sess = tf.InteractiveSession()#第二种设置方式https://playground.tensorflow.org/是一个通过网页浏览器就可以训练得简单神经网络并实现了可视化训练过程的工具。

训练神经网络的过程为以下三个步骤:
1、定义神经网络的结构和前向传播的输出结果。
2、定义损失函数以及选择反向传播优化的算法。
3、生成会话(tf.Session)并且在训练数据上反复运行反向传播优化算法。
深度学习有两个重要的特征——多层和非线性。
在线性模型中,模型的输出为输入的加权和。线性模型的最大特点是任意线性模型的组合仍然还是线性模型。线性模型只能通过直线来划分平面,如果一个问题可以通过直线来划分,那么可以用线性模型来解决这个线性可分问题。
激活函数实现去线性化:如果将每一个神经元的输出通过一个非线性函数,那么整个神经网络的模型也就不再是线性的,这个非线性函数就是激活函数。
主要做两个变化:1、增加偏置项(bias) 2、在加权和的基础上做非线性变换。
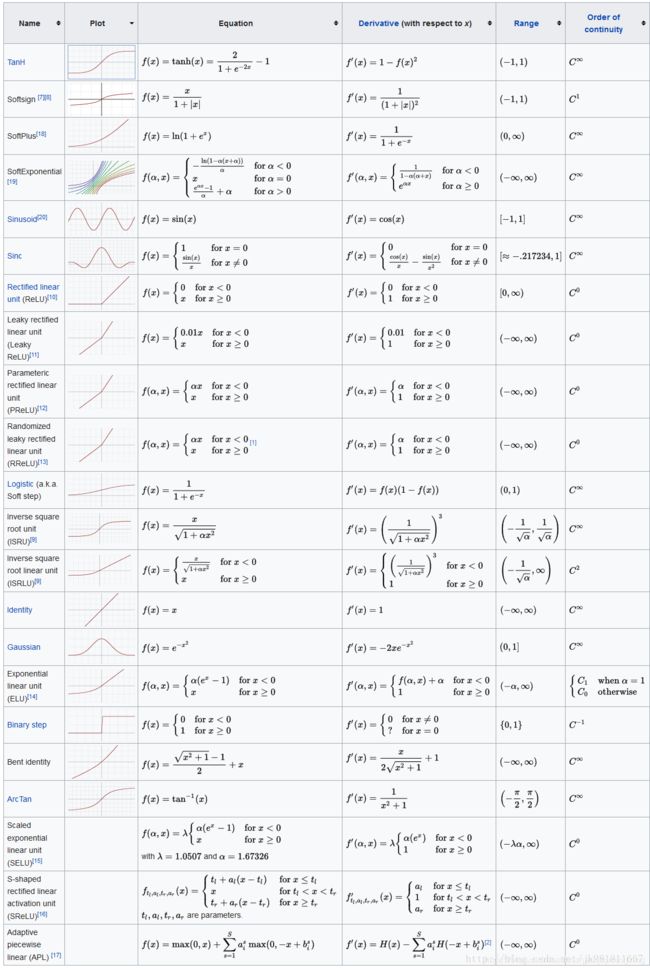
损失函数:
神经网络模型的效果以及优化的目标是通过损失函数来定义的。
监督学习的两大种类:分类问题和回归问题。
交叉熵刻画了两个概率分布之间的距离,它是分类问题中使用比较广的一种损失函数。交叉熵的值越小,两个概率分布越接近。(使用softmax回归之后的交叉熵损失函数)
Softmax回归本身可以作为一个学习算法来优化分类结果,但是在TensorFlow中Softmax回归的参数被去掉了,它只是一层额外的处理层,将神经网络前向传播的输出变成了一个概率分布。
与分类问题不同,回归问题解决的是对具体数值的预测。这些问题需要预测的不是一个事先定义好的类别,而是一个任意实数。(使用均方误差损失函数)
神经网络优化算法:
主要是通过反向传播算法(backpropagation)和梯度下降算法(gradient decent)调整神经网络中的参数的取值。
梯度下降算法主要用于优化单个参数的取值。梯度下降算法会迭代式更新参数θ,不断沿着梯度的反方向让参数朝着总损失更小的方向更新。参数的梯度可以通过求偏导的方式计算。有了梯度还需要定义一个学习率η来定义每次参数更新的幅度。
反向传播算法给出了一个高效的方式在所有参数上使用梯度下降算法。反向传播算法是训练神经网络的核心算法。
神经网络的优化过程可以分两个阶段:
1、第一个阶段先通过前向传播算法计算得到预测值,并将预测值和真实值做对比得出两者之间的差距。
2、第二阶段通过反向传播算法计算损失函数对每一个参数的梯度,再根据梯度和学习率使用梯度下降算法更新每一个参数。
注:在训练神经网络时,参数的初始值会很大程度影响最后得到的结果,只有当损失函数为凸函数时,梯度下降算法才能保证达到全局最优解。另外一个问题是:梯度下降法计算时间较长(计算所有训练数据的损失函数)为了综合梯度下降算法和随机梯度下降算法:在实际应用中,一般采用这两个算法的折中——每次计算一小部分训练数据的损失函数(一个batch)。
学习率的设置方法:
通过指数衰减的方法设置梯度下降算法中的学习率,可以让模型在训练得前期快速接近较优解。
指数衰减法(tf.train.exponential_decay)函数实现,通过该函数,可以先使用较大的学习率快速得到一个比较优解,然后随着迭代的继续逐步减小学习率,使得模型在训练后期更加稳定。(exponential_decay函数会指数级的减小学习率)
滑动平均模型会将每一轮迭代得到的模型综合起来,从而使得最终得到的模型更加健壮(robust)。
模型训练过程中的三种情况:
1、由于模型过于简单,无法刻画问题的趋势。
2、模型比较合理,它既不会过于关注训练数据中的噪音,又能够比较好的刻画问题的整体趋势。
3、模型过拟合,过度拟合训练数据中的随机噪音虽然可以得到非常小的损失函数,但是对于未知数据可能无法做出可靠的判断。为了避免过拟合问题一个非常常用的方法是正则化。正则化的思想是在损失函数中加入刻画模型复杂程度的指标。(L1正则化和L2正则化两种).
MNIST数字识别问题
MNIST是一个非常有名的手写体数字识别数字集。
【在神经网络的结构上,深度学习需要使用激活函数实现神经网络模型的去线性化,需要使用一个或多个隐藏层使得神经网络的结构更深,以解决复杂问题。在训练神经网络时,使用带指数衰减的学习率设置,使用正则化来避免过度拟合,以及使用滑动平均模型来使得最终模型更加健壮。】
使用验证数据集判断模型效果
神经网络程序中需要设置7种不同的参数:初始学习率、学习率衰减率、隐藏层节点数量、迭代轮数等7个不同的参数。在大部分情况下,配置神经网络的这些参数都是通过实验调整的。虽然一个神经网络模型的效果最终是通过测试数据来评判的,但是使用测试数据来选取参数可能会导致神经网络模型过度拟合测试数据,从而失去对未知数据的预测能力。一般会从训练数据中抽取一部分作为验证数据(除了使用验证数据集还可使用交叉验证,但在海量数据中花费时间比较长)
变量管理
当神经网络的结构更加复杂、参数更多时,就需要一个更好的方式来传递和管理神经网络中的参数了,TensorFlow提供了通过变量名称来创建或者获取一个变量的机制(tf.get.variable和tf.variable_scope函数来创建或者获取变量)。
TensorFlow模型持久化
为了让训练得结果可以复用,需要将训练数据得到的模型保存下来方便下次使用,即需要将训练得到的神经网络模型持久化。TensorFlow提供一个API来保存和还原一个神经网络模型(即tf,train.Saver类。后缀名为model.ckpt。路径下会生成三个文件:①model.ckpt.meta,它保存了TensorFlow计算图的结构。②model.ckpt,这个文件中保存了TensorFlow程序中的每一个变量的取值。③checkpoint文件,这个文件保存了一个目录下所有的模型文件列表。)
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init_op)
saver.save(sess,"/path/to/model/model.ckpt") #将模型保存
saver = tf.train.Saver()
with tf.Session() as sess:
saver.restore(sess,"/path/to/model/model.ckpt")#加载已保存的模型【加载模型的代码中没有运行变量的初始化过程,而是将变量的值通过已保存的模型加载进来。如果不希望重复定义图上的运算,也可以直接加载已经持久化的图。】
TensorFlow训练神经网络的最佳实践
①当神经网络的结构变得更加复杂、参数更多时,程序的可读性差。
②需要保存持久化训练好的模型。使得模型可以被重用。
③一般神经网络模型训练得时间都比较长,少则几个小时,多则几天甚至几周。所以在训练得过程中需要每隔一段时间保存一次模型训练的中间结果。
【将训练和测试分成两个独立程序,这可以使得每个组件更加灵活。除了将不同功能模块分开,还将向前传播的过程抽象为一个单独的库函数。】
卷积神经网络:
卷积神经网络主要由以下5种结构组成:
1、输入层:输入层是整个神经网络的输入,在处理图像的卷积神经网络中,它一般代表了一张图片的像素矩阵。(从输入层开始,卷神经网络通过不同的神经网络结构将上一层的三维矩阵转化为下一层的三维矩阵,直到最后的全连接。
2、卷积层:卷积层是卷积神经网络中最为重要的部分。和传统的全连接层不同,卷积层中每一个节点的输入只是上一层神经网络的一小块,这个小块常用大小有3×3或者5×5.。卷积层试图将神经网络中的没一小块进行更加深入的分析,从而得到抽象程度更高的特征。(一般来说,通过卷积层处理过的 节点矩阵会变得更深。)
3、池化层:池化层神经网络不会改变三维矩阵的深度,但是它可以缩小矩阵的大小从而减少全连接层中的参数。(池化操作可以认为是将一张分辨率较高的图片转化为分辨率较低的图片。)
4、全连接层:经过几轮卷积层和池化层的处理之后,可以认为图像中的信息已经被抽象成了信息含量更高的特征。最后通过1到2个全连接层来给出最后的分类结果。(我们可以将卷积层和池化层看成自动图像特征提取的过程,在特征提取完成之后,仍然需要使用全连接层来完成分类任务。)
5、Softmax层:Softmax层主要用于分类问题。通过Softmax层,可以得到当前样例属于不同种类的概率分布情况。
卷积层神经网络中最重要的一个部分是:过滤器(filter)或者内核(kernel):过滤器可以将当前层神经网络上的一个子节点矩阵转化为下一层神经网络上的一个单位节点矩阵。卷积层的参数个数和图片的大小无关,它只和过滤器的尺寸、深度以及当前层节点矩阵的深度有关。
池化层:和卷积层类似,池化层前向传播的过程也是通过移动一个类似过滤器的结构完成的,不过池化层过滤器中的计算不是节点的加权和,而是采用更加简单的最大值或者平均值。使用最大值操作的池化层被称之为最大池化层(这是被使用得最多的池化层结构。)使用平均值操作的池化层被称之为平均值池化层。(【注】池化层主要用于减小矩阵的长和宽,虽然池化层也可以减小矩阵深度,但是实践中一般不会这样使用。有研究指出池化层对模型效果的影响不大,不过目前主流的卷积神经网络模型中都有含有池化层。)
移动方式:卷积层和池化层中的移动方式是相似的,唯一的区别在于卷积层使用的过滤器是横跨整个深度的,而池化层使用的过滤器只能影响一个深度上的节点。所以池化层的 过滤器除了在长和宽两个维度上移动,他还需要在深度这个维度上移动。
经典卷积网络模型:
LeNet-5模型:
①Convolutions②Subsampling③Convolutions④Subsampling⑤Full connection⑥Full connection⑦Gaussion 高斯connection
dropout方法:dropout可以进一步提升模型的可靠性并防止过拟合,dropout过程只在训练时使用。在训练时dropout会随机将部分节点的输出改为0,从而避免过拟合,是模型在测试数据上的效果更好。dropout一般只在全连接层而不是卷积层或池化层使用。.
正则表达式总结了一些经典的用于图片分类问题的卷积神经网络架构:
输入层 ------->(卷积层+ ------>池化层?)+ ----->全连接层+
在以上公式中:
“卷积层+”表示一层或者多层卷积层,大部分卷积神经网络中一般最多连续使用三层卷积层。
“池化层?”表示没有或者一层池化层。池化层虽然可以起到减少参数防止过拟合问题,但是在部分论文中也发现可以直接通过调整卷积层步长来完成。
在多轮卷积层和池化层之后,卷积神经网络在输出之前一般会经过1~2个全连接层。
Inception-v3模型:
在LeNet-5模型中,不同卷积层通过串联的方式连接在一起,而inception-v3模型中inception结构是将不同的卷积层通过并联的方式结合在一起。
类似inception-v3模型这样复杂卷积神经网络,将使用TensorFlow-Slim工具来更加简洁的实现一个卷积层。
卷积神经网络迁移学习:将一个问题上训练好的模型通过简单的调整使其适用于一个新的问题。通过迁移学习,可以使用少量训练数据在短时间内训练出效果还不错的神经网络模型。
瓶颈层:最后这一层全连接层之前的网络层称之为瓶颈层。
图像数据处理:图像的亮度、对比度等属性对图像的影响是非常大的,相同的物体在不同的亮度、对比度下差别非常大。然而在很多图像识别问题中,这些因素都不应该影响最后的识别结果。所以需要对图像进行预处理使得训练得到的神经网络模型尽可能小的被无关因素所影响。但与此同时,复杂的预处理过程可能导致训练效率的下降,为了减小预处理对于训练速度的影响,将使用TensorFlow中利用队列进行多线程处理输入数据。
包括:
图像编码处理tf.image.decode_png和tf.image.decode_jpeg解码函数。
图像大小调整:
第一种是通过算法使得新的图像尽量保存原始图像上的所有信息。封装在tf.image.resize_images函数中
| Method |
图像大小调整算法 |
| 0 |
双线性插值法 |
| 1 |
最近邻居法 |
| 2 |
双三次插值法 |
| 3 |
面积插值法 |
第二种是TensorFlow提供的API对图像进行裁剪或者填充。或通过比例调整图像大小。
图像翻转:图像翻转不会影响识别结果,通过随机翻转训练图像的方式可以零成本的情况下训练得到的模型可识别不同角度的实体。
图像色彩调整:调整图像的亮度、对比度、饱和度和色相。【注】色彩调整的API可能导致像素的实数值超出0.0-1.0的范围,因此输出最终图像钱需要将其值截断在范围区间,否则不仅图像无法正常可视化,以此为输入的神经网络的训练质量也可能受到影响。如果对图像进行多项处理操作,那么这一截断过程应该在所有处理完成后进行。
处理标注框:在很多图像识别的数据集中,图像中需要关注的物体通常会被标注框圈出来。
TFRecord输入数据格式:TensorFlow提供了一种统一的格式来存储数据——TFRecord。
队列与多线程:TensorFlow中提供FIFOQueue(先进先出)和RandomShuffleQueue(随机队列)两种队列。队列不仅仅是一种数据结构,还是异步计算张量取值的一个重要机制。
循环神经网络:主要用途是处理和预测序列数据(最擅长解决与时间序列相关的问题)。从网络结构上,循环神经网络会记忆之前的信息,并利用之前的信息影响后面结点的输出。也就是说,循环神经网络的隐藏层之间的结点是有连接的,隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出。
(循环神经网络中的模块的运算和变量在不同时刻是相同的,因此循环神经网络理论上可以被看做是同一个神经网络结构被无限复制的结果。
用于手写数字分类问题所要用到的(经典)MNIST数据集
http://yann.lecun.com/exdb/mnist/
There are 4 files:
train-images-idx3-ubyte: training set images
train-labels-idx1-ubyte: training set labels
t10k-images-idx3-ubyte: test set images
t10k-labels-idx1-ubyte: test set labels
The training set contains 60000 examples, and the test set 10000 examples.
The first 5000 examples of the test set are taken from the original NIST training set. The last 5000 are taken from the original NIST test set. The first 5000 are cleaner and easier than the last 5000.
强烈推荐网站,第一个是GAN/image/semi-supervised learning等的代码和文章,超级棒!https://github.com/zhangqianhui/AdversarialNetsPapers
第二个是tensorflow的API快速查找,很全。http://docs.w3cub.com/tensorflow~python/
第三个是tensorflow的官方中文文档,入门级。http://www.tensorfly.cn/tfdoc/get_started/introduction.htmlpython
菜鸟基础学习网址,有简单的基础和动态图方便理解。http://www.runoob.com/python/python-tutorial.html