Python爬虫从入门到精通——请求库requests的使用(二):高级用法
分类目录:《Python爬虫从入门到精通》总目录
请求库requests的使用(一):基本用法
请求库requests的使用(二):高级用法
在《请求库requests的使用(一):基本用法》中,我们了解了requests的基本用法,如基本的GET、POST请求以及Response对象。在本文中,我们来了解下requests的一些高级用法,如文件上传、Cookies设置、代理设置等。
文件上传
我们知道requests可以模拟提交一些数据。假如有的网站需要上传文件,我们也可以用它来实现,这非常简单,示例如下:
import requests
files = {'file': open('sample.txt', 'rb')}
response = requests.post('http://httpbin.org/post', files=files)
Cookies
在《基本库Urllib的使用(一):发送请求》中我们使用urllib处理过Cookies,写法比较复杂,而有了requests,获取和设置Cookies只需一步即可完成。
import requests
response = requests.get('https://www.baidu.com')
for k, v in response.cookies.items():
print(k + '=' + v)
这里我们首先调用cookies属性即可成功得到Cookies,它是RequestCookie]ar类型。然后用items()方法将其转化为元组组成的列表,遍历输出每一个Cookie的名称和值,实现Cookie的遍历解析。当然,我们也可以直接用Cookie来维持登录状态,下面以知乎为例来说明。首先登录知乎,将Headers中的Cookie内容复制下来。
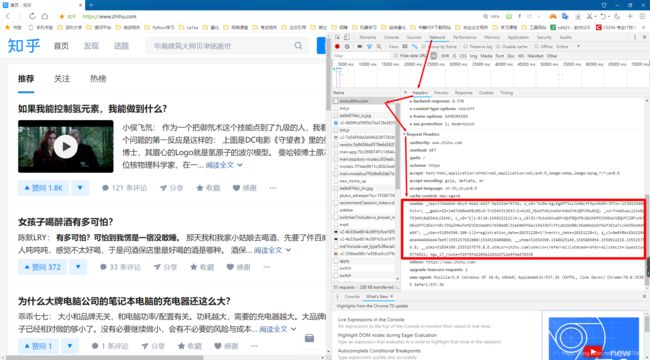
这里可以替换成你自己的Cookie,将其设置到Headers里面,然后发送请求。
import requests
headers = {
'Cookie': '_zap=374dd6b6-8bc9-46a2-bb57-5a515de79736; d_c0="ALBm-KgyEg6PTtxLCW90yfF9ps9kB5rJPTo=|1534519408"; tst=r; __gads=ID=1a67d60ea98c05c0:T=1545313633:S=ALNI_MbotFAXykatWrk6W2YmzQPh3Nu01Q; _xsrf=Wa5uaL12iWGpnN79jmVL0qES4dLCEkHC; z_c0="2|1:0|10:1548221511|4:z_c0|92:Mi4xWXAxbEFnQUFBQUFBc0diNHFESVNEaVlBQUFCZ0FsVk5SMG8xWFFCdEdvYnRLY3hpZHNwTkM2VC0zbmdMcTA5RmdB|31e6045f6ac1543367cffcdbd1600c36e06bbb5f42f361a7cc4d35bb4d52ca96"; __utmv=51854390.100-1|2=registration_date=20151220=1^3=entry_date=20151220=1; q_c1=0e8f0bc816224fa9a6e44a666ee47be9|1555257581000|1534519408000; __utma=51854390.1548625149.1545805056.1550922216.1555257579.8; __utmz=51854390.1555257579.8.8.utmcsr=zhihu.com|utmccn=(referral)|utmcmd=referral|utmcct=/question/29776821; tgw_l7_route=f2979fdd289e2265b2f12e4f4a478330',
'Host': 'www.zhihu.com',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safri/537.36'
}
response = requests.get('https://www.zhihu.com', headers=headers)
print(response.text)
结果中包含了登录后的结果,说明登陆成功。当然,也可以通过cookies参数来设置,不过这样就需要构造Requestscookie]ar对象,而且需要分割一下cookies。首先,新建了一个RequestCookieJar对象,然后将复制下来的cookies利用split()方法分割,接着利用set()方法设置好每个Cookie的key和value,然后通过调用requests的get()方法并传递给cookies参数即可。当然,由于知乎本身的限制,headers参数也不能少,只不过不需要在原来的headers参数里面设置cookie字段了,本文就不在以代码演示上述过程。
会话维持
在requests中,如果直接利用get()或post()等方法的确可以做到模拟网页的请求,但是这实际上是相当于不同的会话,也就是说相当于你用了两个浏览器打开了不同的页面。设想这样一个场景,第一个请求利用post()方法登录了某个网站,第二次想获取成功登录后的自己的个人信息,你又用了一次get()方法去请求个人信息页面。实际上,这相当于打开了两个浏览器,是两个完全不相关的会话,即我们不能成功获取个人信息。
import requests
requests.get('http://httpbin.org/cookies/set/number/123456789')
response = requests.get('http://httpbin.org/cookies')
print(response.text)
这里我们请求了一个测试网址http://httpbin.org/cookies/set/number/123456789。请求这个网址时,可以设置一个cookie,名称叫作number,内容是123456789,随后又请求了http://httpbin.org/cookies,此网址可以获取当前的Cookies,但并没有成功获取到设置的名称叫作number,内容是123456789的Cookies吗。
{
"cookies": {}
}
若我们在两次请求时设置一样的cookies,是可以获取个人信息的,但这样做非常烦琐,我们有更简单的解决方法——会话维持,即相当于打开一个新的浏览器选项卡而不是新开一个浏览器。利用Session对象,我们可以方便地维护一个会话,而且不用担心cookies的问题,它会帮我们自动处理好。
import requests
s = requests.Session()
s.get('http://httpbin.org/cookies/set/number/123456789')
response = s.get('http://httpbin.org/cookies')
print(response.text)
利用Session,可以做到模拟同一个会话而不用担心Cookies的问题。它通常用于模拟登录成功之后再进行下一步的操作。
{
"cookies": {
"number": "123456789"
}
}
Session 在平常用得非常广泛,可以用于模拟在一个浏览器中打开同一站点的不同页面,后面会有专门的文章来讲解这部分内容。
SSL证书验证
此外,requests还提供了证书验证的功能。当发送HTTP请求的时候,它会检查SSL证书,我们可以使用verify参数控制是否检查此证书。其实如果不加verify参数的话,默认是True,会自动验证。如果正如验证不通过,会提示一个错误SSLError,表示证书验证错误。所以,如果请求一个HTTPS且证书验证错误的站点,就可以将verify参数设置为False。
response = requests.get('https://www.12306.cn', verift=False)
代理设置
对于某些网站,在测试的时候请求几次,能正常获取内容。但是一旦开始大规模爬取,对于大规模且频繁的请求,网站可能会弹出验证码,或者跳转到登录认证页面,更甚者可能会直接封禁客户端的IP,导致一定时间段内无法访问。为了防止这种情况发生,我们需要设置代理来解决这个问题,这就需要用到proxies参数。
import requests
proxies = {
'http': 'http://172.169.1.1:3128',
'https': 'https://172.169.1.1:1080'
}
requests.get('https://www.baidu.com', proxies=proxies)
当然,在实际的爬虫任务中,要将proxies设置为可用的代理,以上172.169.1.1仅仅作为例子使用。
若代理需要使用HTTP Basic Auth,可以使用类似http:/user:password@host:port这样的语法来设置代理。
import requests
proxies = {
'http': `http:/user:[email protected]:3128/',
}
requests.get('https://www.baidu.com', proxies=proxies )
超时设置
在本机网络状况不好或者服务器网络响应太慢甚至无响应时,我们可能会等待特别久的时间才可能收到响应,甚至到最后收不到响应而报错。为了防止服务器不能及时响应,应该设置一个超时时间,即超过了这个时间还没有得到响应,那就报错。这需要用到timeout参数。这个时间的计算是发出请求到服务器返回响应的时间。
import requests
response = requests.get('https://www.baidu.com', timeout=1)
print(response.status_code)
通过这样的方式,我们可以将超时时间设置为1秒,如果1秒内没有啊应,那就抛出异常。实际上,请求分为两个阶段,即连接和读取。上面设置的timeout将用作连接和读取这二者的timeout总和。
如果要分别指定,就可以传入一个元组:
response = requests.get('https://www.baidu.com', timeout=(2, 2, 3))
如果想永久等待,可以直接将timeout设置为None,或者不设置直接留空,因为默认是None或者不加入timeout参数。这样的话,如果服务器还在运行,但是响应特别慢,那就慢慢等吧,它永远不会返回超时错误的。
response = requests.get('https://www.baidu.com', timeout=None)
7.身份认证
在访问网站时,我们可能会遇到身份认证的页面,此时可以使用requests自带的身份认证功能。
import requests
from requests import HTTPBasicAuth
response = requests.get('https://www.baidu.com', auth=HTTPBasicAuth('username', 'password'))
当然,如果参数都传一个HTTPBasicAuth类,就显得有点烦琐了,所以requests提供了一个更简单的写法,可以直接传一个元组,它会默认使用HTTPBasicAuth这个类来认证。
import requests
response = requests.get('https://www.baidu.com', auth=('username', 'password'))
本文讲解了requests的一些高级用法,这些用法在后面实战部分会经常用到,需要熟练掌握。更多的用法可以参考requests的官方文档。