大数据-----大数据-机器学习-人工智能
1.大数据与机器学习的关系:
大数据领域我们做的是数据的存储和简单的统计计算,机器学习在大数据的应用是为了发现数据的规律或模型,用机器学习算法对数据进行计算的到的模型,从而决定我们的预测与决定的因素(比如在大数据用户画像项目里,生成的特殊用户字段)。
2.大数据在机器学习的应用
目前市场实际开发模式中,应该在大数据哪一个阶段层次应用到机器学习的相关技术呢,我们接下来来说明,首先目前大数据的架构模式列举如下几个
2.1数据采集(ftp、socket)---数据存储(hdfs)---数据清洗(MapReduce)----数据分析(hive)---sqoop导入-----存储(mysql、oracle)---web显示
2.2数据采集(ftp、socket)---数据存储(hdfs)---数据清洗(MapReduce)---列式数据库存储(hbase)-----thrift(协处理器)---web显示
2.3数据采集(ftp、socket)---数据存储(hdfs)---数据清洗(MapReduce)----数据分析(hive)----impala(实时数据分析)---jdbc-----web显示
2.4数据采集(ftp、socket)---数据存储(hdfs)---spark计算-----存储(mysql、oracle)---web显示
整体在开发完成后用分布式任务调度系统(azkaban、oozie)对以上架构进行周期运行计算。
而机器学习在大数据的应用阶段为:数据分析(hive)--- 机器学习----sqoop导入、列式数据库存储(hbase)---- 机器学习------thrift(协处理器)
总结在大数据架构中,机器学习处于上层阶段,在大数据进行计算之后向最终储存或者直接web展现的时候需要机器学习来产生一个决策与预测的模型。
3.机器学习
3.1机器学习的理论在1950年就已经提出,但是因为数据量的存储机制落后,算法结合度低下,以及我们对于数据处理速度的低下导致一直不能把技术落地,而在科技高速发展的今天,因为以上技术困境的解除,导致机器学习向阳而生,从而被广泛应用,改变了人们的生活,
3.2 机器学习是多领域交叉学科,涉及概率论、统计学、逼近学、凸分学、算法复杂度理论等多门学科,专门计算机器怎样模拟实现人类的学习行为,获取行的知识和技能,然后重新改变已经有的知识结构来提高完善自身的性能。
3.3 机器学习(ML)与人工智能(AI)的关系:它是人工智能的核心,是使计算机拥有智能的根本途径,它的应用遍布人工智能的各个领域,它主要使用归纳、总和而不是演绎。
3.3 机器学习的学习动作:针对经验E(experience)和一系列任务T(tasks)和一定表现的衡量P,如果经验E的积累,针对定义好的任务T可以提高表现P,就说明有学习能力。
3.4 机器学习的应用:语音识别、自动驾驶、语言翻译、推荐系统、无人机等等
3.5 机器学习与深度学习的关系:深度学习是实现机器学习的一种技术深度学习使得许多机器学习应用得以实现,并拓展了人工智能的整个领域。深度学习一一实现了各种任务,并使得所有的机器辅助变成可能。无人驾驶汽车、电影推荐等,都触手可及或即将成为现实。人工智能就在现在,也在未来。有了深度学习,人工智能可能甚至达到像我们畅想的科幻小说一样效果。
( 更简单理解)人工智能是祖辈,机器学习是父辈,深度学习是儿子辈!
3.6 机器学习的运行方式:我们知道程序处理是由CPU(中央处理器)来计算运行的,但是目前我们开发应用中机器学习的计算大部分(深度学习)是通过GPU(图形处理器)来计算运行的
3.7 机器学习的概念:
3.7.1 基本概念:训练集,测试集,特征值,监督学习,非监督学习,半监督学习,分类,回归
3.7.2 概念学习:人类学习概念(如婴儿):鸟,狗;车,房子;黑匣子和计算机 (怎么认识和区分?)定义:概念学习是指从有关某个布尔函数(是或否)的输入输出训练样例中推断出该布尔函数
3.7.3 数据集:真实数据集
3.7.4 行:样本数据
3.7.5 列:特征或者数据数据
3.7.6 特征向量:每一个样本中的数据组成的向量
3.7.7 属性空间:属性章程的空间
3.7.8 训练集:用于模型训练的数据集
3.7.9 测试集:用于校验模型的优劣程度
3.7.10 训练过程:(学习过程)使用训练数据集+机器学习算法==》模型
3.8 监督学习:
监督(supervised)是指训练数据集中的每个样本均有一个已知的输出项(类标label)
输出变量为连续变量的预测问题称为 回归( regression )问题
回归算法:
• 简单线性回归
• 多元线性回归
• Lasso回归
• Ridge回归
• ElasticNet
输出变量为有限个离散变量的预测问题称为 分类问题
分类算法:
• 简单线性回归
• 多元线性回归
• Lasso回归
• Ridge回归
• ElasticNet
3.9 非监督学习:
人们给机器一大堆没有分类标记的数据,让机器可以对数据分类、检测异常等。
聚类(KMeans)

降维(PCA,LDA)

3.10 半监督学习:
半监督学习就是提供了一条利用“廉价”的未标记样本的途径

3.11 强化学习:
是机器学习的一个重要分支,主要用来解决连续决策的问题。
围棋可以归纳为一个强化学习问题,需要学习在各种局势下如何走出最好的招法。

3.12 迁移学习:
应用场景:
小数据的问题。比方说新开一个网店,卖一种新的糕点,没有任何的数据,就无法建立模型对用户进行推荐。但用户买一个东西会反映到用户可能还会买另外一个东西,所以如果知道用户在另外一个领域,比方说卖饮料,已经有了很多很多的数据,利用这些数据建一个模型,结合用户买饮料的习惯和买糕点的习惯的关联,就可以把饮料的推荐模型给成功地迁移到糕点的领域,这样,在数据不多的情况下可以成功推荐一些用户可能喜欢的糕点。这个例子就说明,有两个领域,一个领域已经有很多的数据,能成功地建一个模型,有一个领域数据不多,但是和前面那个领域是关联的,就可以把那个模型给迁移过来。
个性化的问题。比如每个人都希望自己的手机能够记住一些习惯,这样不用每次都去设定它,怎么才能让手机记住这一点呢?其实可以通过迁移学习把一个通用的用户使用手机的模型迁移到个性化的数据上面。
4.学习机器学习应该具备哪些知识
4.1对概率要有基本了解,
4.2了解微积分和线性代数的基本知识,
4.3 掌握Python编程或者R语言编程(在公司企业开发常用Python来完成机器学习数据挖掘、在学术界用R语言来完成机器学习数据挖掘)
在企业中要求我们要达成的目标是:掌握机器学习算法和应用框架通过分类及回归来解决实际问题。
机器学习对应的职位:数据挖掘(用户画像方向)、NLP(自然语言处理)、推荐系统(推荐算法、排序算法)、计算广告(CTR预估)、计算机视觉(深度学习)、语音识别(HMM,深度学习)注意:这些职位的前提是要有大数据开发相关经验。
5.常用的十个机器学习的算法
5.1机器学习算法通常可以被分为三大类 —— 监督式学习,非监督式学习和强化学习。监督式学习主要用于一部分数据集(训练数据)有某些可以获取的熟悉(标签),但剩余的样本缺失并且需要预测的场景。非监督式学习主要用于从未标注数据集中挖掘相互之间的隐含关系。强化学习介于两者之间 —— 每一步预测或者行为都或多或少有一些反馈信息,但是却没有准确的标签或者错误提示。
5.2决策树:决策树是一种决策支持工具,它使用树状图或者树状模型来表示决策过程以及后续得到的结果,包括概率事件结果等。请观察下图来理解决策树的结构。

从商业决策的角度来看,决策树就是通过尽可能少的是非判断问题来预测决策正确的概率。这种方法可以帮你用一种结构性的、系统性的方法来得出合理的结论。
5.3 朴素贝叶斯分类器:朴素贝叶斯分类器是一类基于贝叶斯理论的简单的概率分类器,它假设特征之前是相互独立的。下图所示的就是公式 —— P(A|B)表示后验概率,P(B|A)是似然值,P(A)是类别的先验概率,P(B)代表预测器的先验概率。
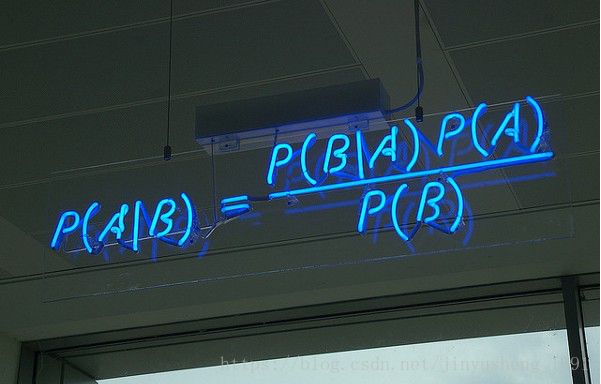
现实场景中的一些例子包括:
- 检测垃圾电子邮件
- 将新闻分为科技、政治、体育等类别
- 判断一段文字表达积极的情绪还是消极的情绪
- 用于人脸检测软件
5.4 随机森林
在源数据中随机选取数据,组成几个子集
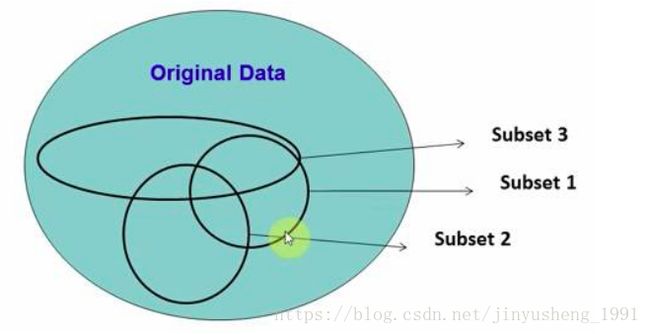
S 矩阵是源数据,有 1-N 条数据,A B C 是feature,最后一列C是类别

由 S 随机生成 M 个子矩阵

这 M 个子集得到 M 个决策树
将新数据投入到这 M 个树中,得到 M 个分类结果,计数看预测成哪一类的数目最多,就将此类别作为最后的预测结果

5.5 逻辑递归
当预测目标是概率这样的,值域需要满足大于等于0,小于等于1的,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出了规定区间。

所以此时需要这样的形状的模型会比较好

那么怎么得到这样的模型呢?
这个模型需要满足两个条件 大于等于0,小于等于1
大于等于0 的模型可以选择 绝对值,平方值,这里用 指数函数,一定大于0
小于等于1 用除法,分子是自己,分母是自身加上1,那一定是小于1的了

再做一下变形,就得到了 logistic regression 模型

通过源数据计算可以得到相应的系数了

最后得到 logistic 的图形

5.6 SVM
support vector machine
要将两类分开,想要得到一个超平面,最优的超平面是到两类的 margin 达到最大,margin就是超平面与离它最近一点的距离,如下图,Z2>Z1,所以绿色的超平面比较好

将这个超平面表示成一个线性方程,在线上方的一类,都大于等于1,另一类小于等于-1

点到面的距离根据图中的公式计算

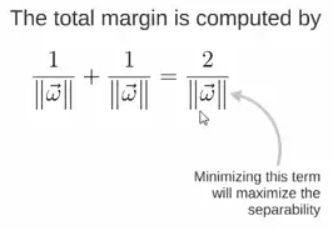
所以得到 total margin 的表达式如下,目标是最大化这个 margin,就需要最小化分母,于是变成了一个优化问题
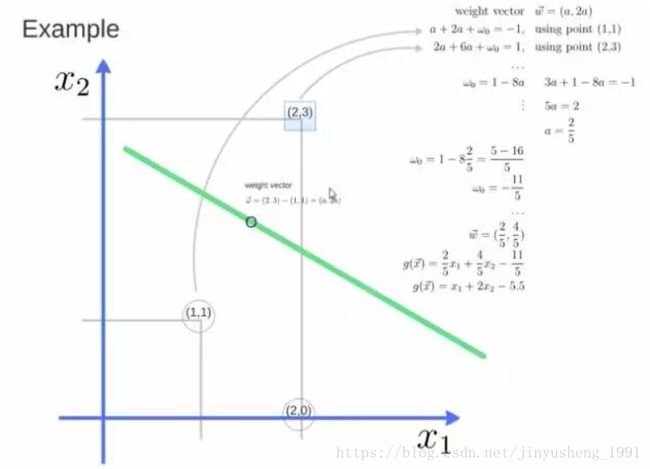
举个栗子,三个点,找到最优的超平面,定义了 weight vector=(2,3)-(1,1)

得到 weight vector 为(a,2a),将两个点代入方程,代入(2,3)另其值=1,代入(1,1)另其值=-1,求解出 a 和 截矩 w0 的值,进而得到超平面的表达式。
a 求出来后,代入(a,2a)得到的就是 support vector
a 和 w0 代入超平面的方程就是 support vector machine
5.7 K最邻近
k nearest neighbours
给一个新的数据时,离它最近的 k 个点中,哪个类别多,这个数据就属于哪一类
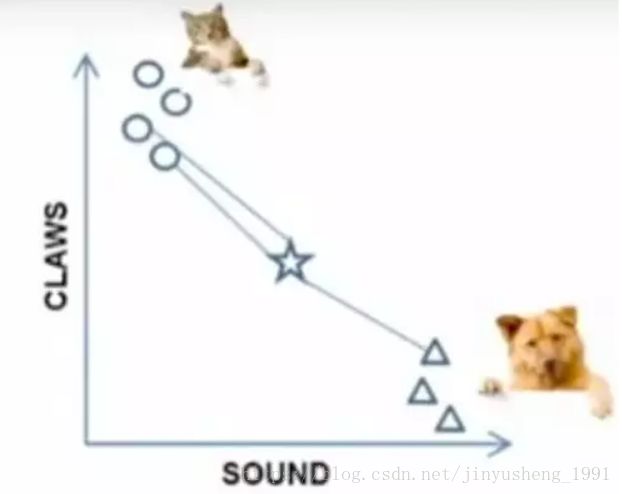
栗子:要区分 猫 和 狗,通过 claws 和 sound 两个feature来判断的话,圆形和三角形是已知分类的了,那么这个 star 代表的是哪一类呢

k=3时,这三条线链接的点就是最近的三个点,那么圆形多一些,所以这个star就是属于猫
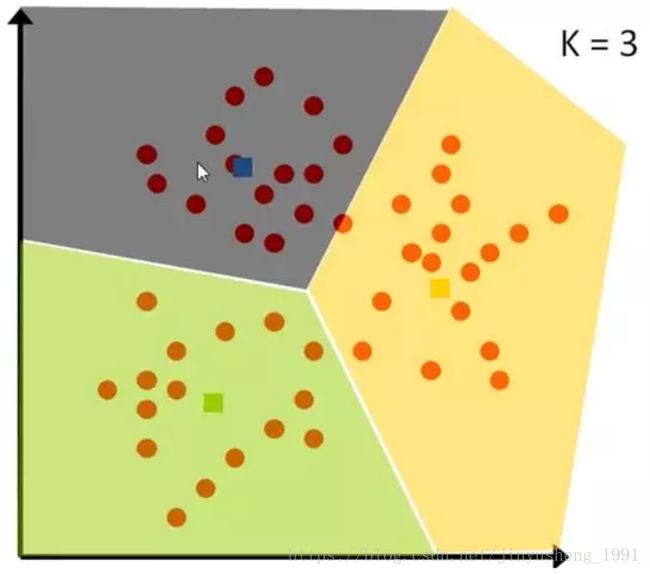
5.8 K均值
想要将一组数据,分为三类,粉色数值大,黄色数值小
最开心先初始化,这里面选了最简单的 3,2,1 作为各类的初始值
剩下的数据里,每个都与三个初始值计算距离,然后归类到离它最近的初始值所在类别

分好类后,计算每一类的平均值,作为新一轮的中心点

几轮之后,分组不再变化了,就可以停止了

5.9 Adaboost
adaboost 是 bosting 的方法之一
bosting就是把若干个分类效果并不好的分类器综合起来考虑,会得到一个效果比较好的分类器。
下图,左右两个决策树,单个看是效果不怎么好的,但是把同样的数据投入进去,把两个结果加起来考虑,就会增加可信度

adaboost 的栗子,手写识别中,在画板上可以抓取到很多 features,例如 始点的方向,始点和终点的距离等等
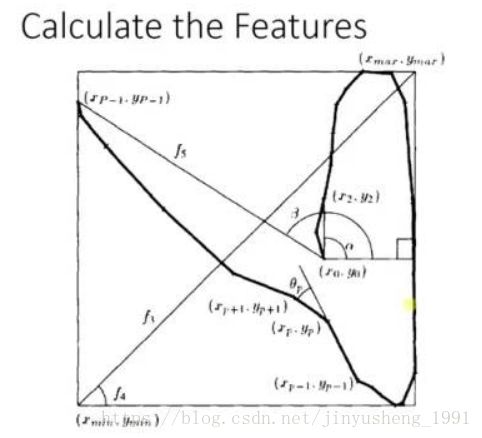
training 的时候,会得到每个 feature 的 weight,例如 2 和 3 的开头部分很像,这个 feature 对分类起到的作用很小,它的权重也就会较小

而这个 alpha 角 就具有很强的识别性,这个 feature 的权重就会较大,最后的预测结果是综合考虑这些 feature 的结果

5.10 神经网络
Neural Networks 适合一个input可能落入至少两个类别里
NN 由若干层神经元,和它们之间的联系组成 第一层是 input 层,最后一层是 output 层
在 hidden 层 和 output 层都有自己的 classifier

input 输入到网络中,被激活,计算的分数被传递到下一层,激活后面的神经层,最后output 层的节点上的分数代表属于各类的分数,下图例子得到分类结果为 class 1
同样的 input 被传输到不同的节点上,之所以会得到不同的结果是因为各自节点有不同的weights 和 bias
这也就是 forward propagation

5.11 马尔可夫
Markov Chains 由 state 和 transitions 组成
栗子,根据这一句话 ‘the quick brown fox jumps over the lazy dog’,要得到 markov chain
步骤,先给每一个单词设定成一个状态,然后计算状态间转换的概率

这是一句话计算出来的概率,当你用大量文本去做统计的时候,会得到更大的状态转移矩阵,例如 the 后面可以连接的单词,及相应的概率
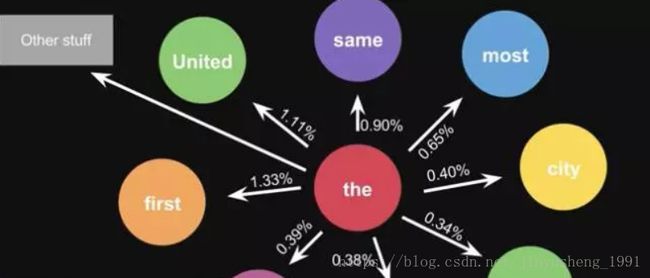
生活中,键盘输入法的备选结果也是一样的原理,模型会更高级

6.人工智能(AI)
6.1经过预测分析,按照目前的人工智能发展速度,在未来十年内我们会有40%的人会被人工智能所取代,有一些行业被取代的比例是很高的,比如:翻译、记者、助理、保安、司机、销售行业、客服、交易员、会计、保姆等等,站在技术角度不考虑社会政策的前提下,那些平时工作性质是简单重复的岗位(这里的简单重复已经不是指工作操作层面而是指工作逻辑层面),是必然会被取代的,甚至医生也在被取代的范围内。
6.2三次浪潮:在1956年就已经提出,是符号主义流派,专家系统占据主导地位。
1980年左右又开始流行,是统计主义流派,用统计模型解决问题
2010年以后,以神经网络、深度学习、大数据的流派开始流行。
6.3 在人工智能的前两次的阶段都是兴起之后又没落了,一些关键技术没有实际的落地,而如今的第三次浪潮已经深深的与我们生活结合了,比如我们打开手机,现在的任何一款APP都几乎涉及了人工智能技术,
7. 数据分析、数据挖掘和机器学习的关系
数据分析是从数据到信息的整理、筛选和加工的过程,数据挖掘是对信息进行价值化的分析。用机器学习的方法进行数据挖掘。机器学习是一种方法;数据挖掘是一件事情;还有一个相似的概念就是模式识别,这也是一件事情。而现在流行的深度学习技术只是机器学习的一种;机器学习和模式识别都是达到人工智能目标的手段之一,对数据挖掘而言,数据库提供数据管理技术,机器学习和统计学提供数据分析技术。