MetaAnchor: Learning to Detect Objects with Customized Anchors
Abstract
本文提出了一种灵活有效的anchor生成机制用于目标检测框架,我们取名为MetaAnchor,不同于之前的检测框架中,使用预先设定的Anchor,MetaAnchor可以从任意的自定义的预设box中动态生成。MetaAnchor可以适用于任何的基于anchor的目标检测框架,如RetinaNet。与之前的anchor预先定义的机制相比,我们发现MetaAnchor在anchor设定以及box分布上更加鲁棒。同时,在迁移学习任务上也更有潜力。我们在COCO检测数据集上的实验结果表明:MetaAnchor在多种场景下都有更优的表现。
1 Introduction
基于anchor的检测机制在目前顶级的检测框架中普遍应用。简单来说,基于anchor的方法就是将box space(包括位置,尺寸,类别等)分解为离散的bins,然后使用定义在对应bin中的anchor function生成每一个目标框。令x表示从输入图像中提取的feature,则针对第i个bin的anchor function可以表示为如下:
![]()
![]()
其中![]() 表示先验的anchor box,它表示的是第i个bin中的目标框的共有属性(如平均位置,尺寸,类别标签等),
表示先验的anchor box,它表示的是第i个bin中的目标框的共有属性(如平均位置,尺寸,类别标签等),![]() 用于判断i-th bin中是否包含有目标框,
用于判断i-th bin中是否包含有目标框,![]() 用于回归该目标框(如果有的话)相对于prior anchor
用于回归该目标框(如果有的话)相对于prior anchor ![]() 的位置,
的位置,![]() 表示anchor function中的参数。
表示anchor function中的参数。
为建立深度神经网络中这些anchor模型,通常使用的方式就是枚举。首先预先设定的anchor ![]() 通过人工选定或者聚类统计的方法来确定。然后对于每个
通过人工选定或者聚类统计的方法来确定。然后对于每个![]() ,对应的anchor function通常使用一个或一些神经网络层来实现。不同anchor function对应的weights是独立或部分共享的。显然这种anchor策略在训练和检测时都是固定的。且可使用的anchor数量被限制在预定的
,对应的anchor function通常使用一个或一些神经网络层来实现。不同anchor function对应的weights是独立或部分共享的。显然这种anchor策略在训练和检测时都是固定的。且可使用的anchor数量被限制在预定的 ![]() 中。
中。
本文提出了一种灵活的替代策略来对anchor进行建模,不再对每一个可能出现的先验bounding box ![]() 进行枚举和分别建立对应的anchor function,而是从
进行枚举和分别建立对应的anchor function,而是从 ![]() 中动态生成。我们通过引入如下的MetaAnchor模型来实现:
中动态生成。我们通过引入如下的MetaAnchor模型来实现:
![]()
与传统的predifined anchor策略相比,我们提出的MetaAnchor有如下优点:
- MetaAnchor在anchor设定以及box分布上更加鲁棒。
- MetaAnchor有助于填补不同数据集之间的bounding box分布差别。
2 Related Work
Anchor methodology in object detection. 传统的基于anchor的方法有如下两个缺点:
- anchor boxes需要精心设计,如通过聚类的方式;
- predifined anchor function需要的参数太多。很多方法尝试使用共享权重参数的方式解决该问题
本文提出的方法不存在上述两个问题。
Weight predition.权值预测是用另一种结构来预测,而不是直接学习得到权值的一种机制,主要的应用领域有:learning to learn[9,1,40], few/zero-shot leaning,以及迁移学习。对于目标检测来说只有少数的相关工作,如[14]提出使用box weight预测mask weights。本文的工作与[14]主要有两个不同点:
- 在我们的MetaAnchor中,weight prediction用于生成anchor functions,而[14]中weight prediction用于domain adaption(从目标框到分割掩膜)
- 在我们的工作中,权重几乎是从零开始生成的,而[14]是从learned box weights开始的
3 Approach
3.1 Anchor Function Generator
anchor function generator ![]() 用于将
用于将![]() 映射到相应的anchor function
映射到相应的anchor function ![]() 。受到[14,9]的启发,我们假设对于不同的
。受到[14,9]的启发,我们假设对于不同的![]() ,,anchor function
,,anchor function ![]() 都有相同的形式
都有相同的形式![]() ,但是拥有不同的参数,也就是:
,但是拥有不同的参数,也就是:
![]() (3)
(3)
由于每个anchor function是由其参数![]() 决定,因此anchor function generator可以使用如下形式表示:
决定,因此anchor function generator可以使用如下形式表示:
![]() (4)
(4)
其中![]() 表示共享参数(与
表示共享参数(与![]() 无关,也是可学习的参数。但是这里比较好奇,这个参数是怎么设置的呢?),
无关,也是可学习的参数。但是这里比较好奇,这个参数是怎么设置的呢?),![]() 是残差部分,依赖于anchor box
是残差部分,依赖于anchor box ![]() .在本文中,我们使用一个简单的two-layer-network来实现
.在本文中,我们使用一个简单的two-layer-network来实现![]() :
:
![]() (5)
(5)
这里![]() 是可学习的参数,
是可学习的参数,![]() 是激活函数(本文中使用的是RELU)。隐节点的数量计作
是激活函数(本文中使用的是RELU)。隐节点的数量计作![]() 。在实践中,
。在实践中,![]() 通常要比
通常要比![]() 的维度小很多,这导致
的维度小很多,这导致![]() 预测的权值在一个维度显著降低的low-rank子空间。这也是为什么我们使用公式(4)中带残差的形式而不是直接使用
预测的权值在一个维度显著降低的low-rank子空间。这也是为什么我们使用公式(4)中带残差的形式而不是直接使用![]() 来表示
来表示![]() 的原因。我们也尝试使用更加复杂的形式来表达
的原因。我们也尝试使用更加复杂的形式来表达![]() ,但是比较下来效果相差不大。
,但是比较下来效果相差不大。
在此基础上,我们也引入了data-dependent的anchor function generator变体形式,讲输入的特征x加入公式中:
![]() (6)
(6)
其中![]() 用于减少feature x的维度;在实践总,我们发现对于卷积特征x,
用于减少feature x的维度;在实践总,我们发现对于卷积特征x,![]() 使用global average pooling操作通常可以取得不错的效果。
使用global average pooling操作通常可以取得不错的效果。
3.2 Architecture Details
理论上讲,metaAnchor在现有的anchor-based目标检测框架中都能够使用。但是我们观察到two-stage检测框架(如faster-rcnn)使用metaAnchor能够提高box proposal的检测,但是对最终的检测效果提升不大,我们相信two-stage检测框架的检测性能主要还是取决于第二阶段的网络(RCNN部分)。因此,本文主要研究应用于one-stage detector。
我们选用one-stage检测器RetinaNet来应用metaAnchor。下图是RetinaNet的结构图。在每个level上的feature,后面都接一个名为“detction head”的子网络,用于产生检测结果。Anchor functions在每一个detHead的尾部定义。参考文献[21],使用3*3卷积实现anchor function;对于每一个detection head,都会预定义3*3*80个anchor boxes(3scales,3aspect ratios,80class)。因此对于分类项来讲有720个filter,对于回归项来讲,有36(3*3*4,对于回归来讲是class-agnostic的)个filter。
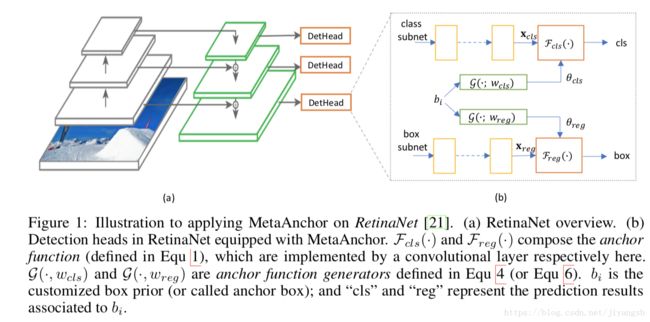
为了应用metaAnchor,我们首先考虑如何编码![]() .根据第一部分的内容,
.根据第一部分的内容,![]() 应该包含位置,尺寸,类别信息,由于卷积神经网络中的卷积结构使得特征图上的坐标已经编码了位置信息,因此位置信息不需要再包含在
应该包含位置,尺寸,类别信息,由于卷积神经网络中的卷积结构使得特征图上的坐标已经编码了位置信息,因此位置信息不需要再包含在![]() 中了。至于类别信息的表示有两种方式:A)直接编码进
中了。至于类别信息的表示有两种方式:A)直接编码进![]() ;B)使用
;B)使用![]() 为每个类别预测weights;我们发现使用B方案更容易优化,且比A有更好的效果。所以在本文中
为每个类别预测weights;我们发现使用B方案更容易优化,且比A有更好的效果。所以在本文中![]() 只跟尺寸有关。
只跟尺寸有关。![]() 使用如下方式编码:
使用如下方式编码:
![]()
![]() 是相应的anchor高度和宽度;
是相应的anchor高度和宽度;![]() 是"standard anchor box"的高度和宽度,用于归一化操作。我们也尝试过使用其他的方法来表示,如使用长宽比,scale表示anchor box的尺寸,但是这跟使用上述公式表示的效果相差不大。
是"standard anchor box"的高度和宽度,用于归一化操作。我们也尝试过使用其他的方法来表示,如使用长宽比,scale表示anchor box的尺寸,但是这跟使用上述公式表示的效果相差不大。
由于在RetinaNet中,分类和目标框回归的anchor function分别作用于两个分离的feature map![]() ,所以我们在使用metaAnchor时,也将使用两个独立的function generator
,所以我们在使用metaAnchor时,也将使用两个独立的function generator ![]() 来分别预测他们的权值。anchor function generator使用公式(4)或(6)实现,隐节点数量
来分别预测他们的权值。anchor function generator使用公式(4)或(6)实现,隐节点数量![]() 设为128,再次说明,metaAnchor的anchor functions是从
设为128,再次说明,metaAnchor的anchor functions是从![]() 动态生成的,而不会使用预先定义的anchors。所以用于
动态生成的,而不会使用预先定义的anchors。所以用于![]() 的filters数量为80(如果有80个类别的话),用于
的filters数量为80(如果有80个类别的话),用于![]() 的filter数量为4。
的filter数量为4。
4 Experiment
本文提出的MetaAnchor算法应用于COCO目标检测数据集,使用的网络结构为RetinaNet,其基础网络为ResNet-50,除非特殊说明,我们使用的是anchor function generator为data-independent variant(如公式(4)所示)。训练时与主干网络一起训练,我们没有使用BN操作。
数据集在训练时分别使用COCO-all(包含COCO-mini)和COCO-mini(约20000张)训练了模型。测试时均使用minival set(包含5000张图像)。性能评测主要使用COCO的标准评价指标,如mmAP.
训练和评测时的设置:为了对比的公平性,我们在所有实验中使用了[21]中的设置(图像尺寸,学习率等),但是在以下所述部分有所不同:[21]中在每个level的detection head上预定义3×3个anchor boxes(3种尺度3种宽高比),[21]中在一些实验中使用了更多的anchor boxes。Table 1展示的是feature level P3上的anchor boxes设置,其中3×3 case与[21]中的设置相同。对于其他feature level上的anchor boxes设置可以参考3.2节推导。而MetaAnchor不需要预定义的anchors,我们建议使用如下策略。在训练过程中,我们首先从Table 1中选取1套anchor box(比如5×5),然后根据Equ. 7生成25个![]() ;每次迭代时,我们在
;每次迭代时,我们在![]() 内随机增强每个
内随机增强每个![]() ,计算对应的的ground truth并使用它们进行优化。我们把这中方法称为“training with 5×5 anchors”。测试时,这些
,计算对应的的ground truth并使用它们进行优化。我们把这中方法称为“training with 5×5 anchors”。测试时,这些![]() 也使用某个不带扰动的anchor box configuration来设置(可以与训练时使用的anchor box configuration不同)。
也使用某个不带扰动的anchor box configuration来设置(可以与训练时使用的anchor box configuration不同)。
下面的章节我们首先在COCO-mini数据集上进行一系列的控制变量实验,然后再展示fully-equipped results on COCO-full数据集(所有因素都使用上的结果)。
存在的几个疑问:
- 论文中提到的使用的predefined anchor,是怎么定义的?还是手动选取的吗?若是这样的话还是使用手动选择的方式,只不过在此基础上又通过学习的方式动态生成了一些可变的anchor。感觉描述不是很细致
- 论文中提到的anchor function genrator表示形式分成了两部分,其中第一部分共用部分地具体设置是什么样子的?