目标检测SSD网络在Caffe下的实现——基于VOC0712数据集
Caffe下实现SSD的流程步骤
- caffe-ssd在Ubuntu下的编译
- caffe-ssd代码下载
- caffe-ssd安装编译
- 数据和模型准备
- VOC数据集下载
- VGG-16预训练模型下载
- LMDB数据集制作
- 生成trainval.txt和test.txt
- 生成LDMB数据集
- SSD网络模型训练
- 代码修改
- 实验结果
- 网络模型测试
- score_ssd_pascal.py
- ssd_detect.py
本篇博客主要讲解ssd目标检测网络在caffe下的安装、编译,VOC数据集下载、VGG预训练模型下载、LMDB数据集制作、ssd_pascal的代码修改、针对VOC0712数据集的网络训练、通过pycaffe进行网络模型测试输出等内容。
数据来源:VOC2007,VOC2012
模型:VGG-16
系统平台:Ubuntu-GPU
caffe-ssd在Ubuntu下的编译
包括caffe-ssd代码下载、安装、编译
caffe-ssd代码下载
我使用的是weiliu89的ssd代码,链接如下:caffe-ssd Github链接
下载下来传到服务器中,或者在ubuntu terminal下直接git:git clone https://github.com/weiliu89/caffe.git
caffe-ssd安装编译
修改根目录下的Makefile.config文件,主要是关于使用GPU还是CPU,Cuda路径、cudnn路径、python路径以及matlab路径的设置。
在这里我不讲解怎么具体去修改该文件,一般来说我默认你在linux系统中已经编译好了原始的caffe,所以直接将caffe-ssd下的Makefile.config文件替换为编译好的caffe下的Makefile.config文件即可。
接着,按照以下步骤即可完成:
make all
make test
make runtest
如果想编译更快一点,还可以在后面加 -j4 或者 -j8:
make all -j8
make test -j8
make runtest -j8
编译成功后的caffe-ssd根目录下应该有一个build软链接。
build下内容如图所示
至此我们已经编译好了caffe-ssd,接下来就是如何跑通该程序了。
数据和模型准备
在跑通程序前,我们先要准备目标检测框架需要的包含类别和位置信息的数据集。
我使用的是VOC数据集
模型使用的是官方使用的VGGNet
VOC数据集下载
VOC2007 VOC2012数据集下载
只需要下载如图所示的三个文件即可。
分别为:
- VOC2012trainval
VOC2007trainval
VOC2007test

或者也可以用wget直接进行下载,使用tar -xvf进行解压使用。
#### Download the data.
cd $DATAPATH/data
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2012/VOCtrainval_11-May-2012.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
# Extract the data.
tar -xvf VOCtrainval_11-May-2012.tar
tar -xvf VOCtrainval_06-Nov-2007.tar
tar -xvf VOCtest_06-Nov-2007.tar
数据准备好后,在caffe_ssd/data有一文件夹VOC0712,将解压后的VOC数据集放该文件夹下。
(数据集名字我均进行了修改)

三个文件夹内目录均如下图:

我们主要使用Annotations、JPEGImages和ImageSets/Main三个文件夹的数据。
- Annotations:XML文件
- JPEGImages:JPG文件
- ImageSets/Main:XML和JPG名字(去除后缀)
其中ImageSets/Main里有多个文件,对应为: - VOC2007test —— test.txt
- VOC2007trainval——trainval.txt
- VOC2012trainval——trainval.txt
VGG-16预训练模型下载
VGG-16预训练模型下载

也可以Github上这个链接进行下载:VGG-16预训练模型
下载完成后,在caffe_ssd/models下新建文件夹VGGNet/VOC0712,将预训练模型放到其中。

LMDB数据集制作
制作LMDB数据集需要用到在***VOC数据集下载***中讲到的三个文件夹。
需要的用到的脚本命令是create_list.sh和create_data.sh,放在caffe_ssd/data/VOC0712目录下。
我们主要是为了生成包含VOC2007和VOC2012训练图片的trainval.txt和包含VOC2007测试图片的test.txt
生成trainval.txt和test.txt
create_list.sh,对其进行修改,主要是路径和名字修改。
#!/bin/bash
root_dir=/home1/xxx/caffe_ssd/data/VOC0712/ # VOC数据集所在路径
sub_dir=ImageSets/Main # trainval.txt和test.txt所在路径
bash_dir=/home1/xxx/caffe_ssd/data/VOC0712 && pwd
for dataset in trainval test
do
dst_file=$bash_dir/$dataset.txt
echo "dst_file $dst_file"
if [ -f $dst_file ]
then
rm -f $dst_file
fi
for name in VOC2007 VOC2012 # 修改为VOC2007 和 VOC2012
do
if [[ $dataset == "test" && $name == "VOC2012" ]] # 如果为VOC2012test,则跳出
then
continue
fi
echo "Create list for $name $dataset..."
dataset_file=$root_dir$name$dataset/$sub_dir/$dataset.txt
echo "dataset_file $dataset_file"
img_file=$bash_dir/$name$dataset/$dataset"_img.txt"
echo "img_file $img_file"
cp $dataset_file $img_file
echo "dataset_file_change $dataset_file"
echo "img_file_change $img_file"
sed -i "s/^/$name$dataset\/JPEGImages\//g" $img_file
echo "img_file $img_file"
sed -i "s/$/.jpg/g" $img_file
label_file=$bash_dir/$name$dataset/$dataset"_label.txt"
cp $dataset_file $label_file
sed -i "s/^/$name$dataset\/Annotations\//g" $label_file
sed -i "s/$/.xml/g" $label_file
#combine two file to one file tow cols
paste -d' ' $img_file $label_file >> $dst_file
#rm -f $label_file
#rm -f $img_file
done
# Generate image name and size infomation.
if [ $dataset == "test" ]
then
/home1/xxx/caffe_ssd/build/tools/get_image_size $root_dir $dst_file $bash_dir/$dataset"_name_size.txt" # 生成测试图片信息
echo "$root_dir $dst_file $bash_dir/$dataset _name_size.txt"
fi
# Shuffle trainval file.
if [ $dataset == "trainval" ]
then
rand_file=$dst_file.random
cat $dst_file | perl -MList::Util=shuffle -e 'print shuffle();' > $rand_file
mv $rand_file $dst_file
fi
done
在Ubuntu Terminal中运行:
sudo sh create_list.sh
在相应的VOC2007test、VOC2007trainval、VOC2012trainval文件夹下会有两个文本文件生成。

这两个文件分别保存image和label信息,不过我们用不到这两个文件了。
文本文件内容如下面两图所示,image和label信息一一对应。
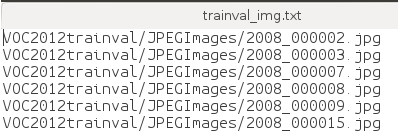
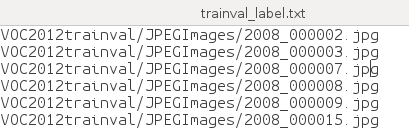
我们真正需要的是
在data/VOC0712路径下生成的三个文件:

打乱后的trainval.txt文件和没打乱的test.txt文件
一列是image路径,一列是label路径
(注意中间有空格)
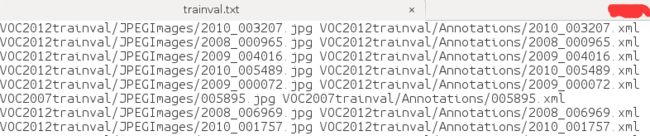
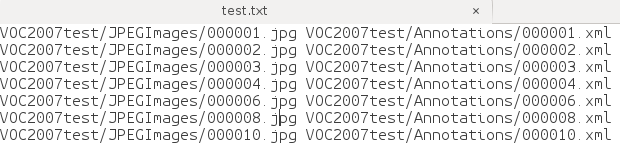
test_name_size.txt则存储了测试图片的名称和尺寸信息

除了trainval.txt和test.txt,还需要labelmap_voc.prototxt文件,这个在data/VOC0712路径下可以找到,定义了VOC的类别,一共21类,背景被认为是一个类别。
item {
name: "none_of_the_above"
label: 0
display_name: "background"
}
item {
name: "aeroplane"
label: 1
display_name: "aeroplane"
}
item {
name: "bicycle"
label: 2
display_name: "bicycle"
}
item {
name: "bird"
label: 3
display_name: "bird"
}
item {
name: "boat"
label: 4
display_name: "boat"
}
item {
name: "bottle"
label: 5
display_name: "bottle"
}
item {
name: "bus"
label: 6
display_name: "bus"
}
item {
name: "car"
label: 7
display_name: "car"
}
item {
name: "cat"
label: 8
display_name: "cat"
}
item {
name: "chair"
label: 9
display_name: "chair"
}
item {
name: "cow"
label: 10
display_name: "cow"
}
item {
name: "diningtable"
label: 11
display_name: "diningtable"
}
item {
name: "dog"
label: 12
display_name: "dog"
}
item {
name: "horse"
label: 13
display_name: "horse"
}
item {
name: "motorbike"
label: 14
display_name: "motorbike"
}
item {
name: "person"
label: 15
display_name: "person"
}
item {
name: "pottedplant"
label: 16
display_name: "pottedplant"
}
item {
name: "sheep"
label: 17
display_name: "sheep"
}
item {
name: "sofa"
label: 18
display_name: "sofa"
}
item {
name: "train"
label: 19
display_name: "train"
}
item {
name: "tvmonitor"
label: 20
display_name: "tvmonitor"
}
生成LDMB数据集
create_data.sh,对其进行修改,主要也是名称和路径修改,这里需要用到pycaffe接口,这个要提前确保编译正确
执行该脚本命令主要用到trainval.txt、test.txt、labelmap_voc.prototxt以及create_annoset.py(该文件存在于caffe-ssd/scripts下)
cur_dir=$(cd $( dirname ${BASH_SOURCE[0]} ) && pwd )
#root_dir=$cur_dir/../..
root_dir="/home1/xxx/caffe_ssd/data/VOC0712" #根路径
cd $root_dir
echo $root_dir
redo=1
data_root_dir="/home1/xxx/caffe_ssd/data/"
dataset_name="VOC0712"
mapfile="$root_dir/labelmap_voc.prototxt"
anno_type="detection"
db="lmdb"
min_dim=0
max_dim=3
width=300
height=300
extra_cmd="--encode-type=jpg --encoded"
if [ $redo ]
then
extra_cmd="$extra_cmd --redo"
fi
for subset in test trainval
do
python2 /home1/xxx/caffe_ssd/scripts/create_annoset.py --anno-type=$anno_type --label-map-file=$mapfile --min-dim=$min_dim --max-dim=$max_dim --resize-width=$width --resize-height=$height --check-label $extra_cmd $data_root_dir$dataset_name $root_dir/$subset.txt $data_root_dir/$dataset_name/lmdb3/$dataset_name"_"$subset"_"$db examples2/$dataset_name
done
如果遇到,import caffe出错问题,请在上方添加一行代码
import sys
sys.path.insert(0,'/home1/xxx/caffe_ssd/python')
然后:
sudo sh create_data.sh
成功后会生成两个文件夹,这两个就是我们需要的LMDB格式数据集

但是对该LMDB数据集使用compute_image_mean求均值时,发现如下问题:
猜想可能是原本的caffe计算均值时没有考虑到目标检测数据集样式,如果有其他大佬明白其中缘由,还望不吝赐教。
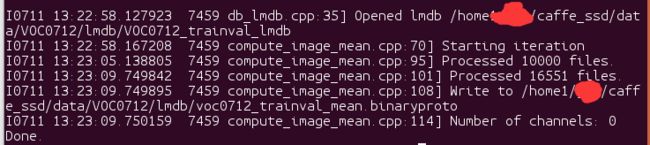
所以,我采用了一个笨方法,先生成分类形式的LMDb数据集,再求均值【104,117,123】
SSD网络模型训练
针对VOC数据集,主要用到

代码修改
网络训练部分,使用ssd_pascal.py
需要对其代码进行一定修改:
85-88行那里(具体行号可能会有出入,但大体是在那里)
修改为自己的LMDB数据所在路径
# The database file for training data. Created by data/VOC0712/create_data.sh
train_data = "/home1/xxx/caffe_ssd/data/VOC0712/lmdb300x300/VOC0712_trainval_lmdb/"
# The database file for testing data. Created by data/VOC0712/create_data.sh
test_data = "/home1/xxx/caffe_ssd/data/VOC0712/lmdb300x300/VOC0712_test_lmdb/"
240行至250行那里,也需要对路径进行一定修改,这里主要修改的是模型以及结果保存路径:
# Directory which stores the model .prototxt file.
save_dir = "/home1/xxx/caffe_ssd/models/VGGNet/VOC0712/{}".format(job_name)
print("save_dir",save_dir)
# Directory which stores the snapshot of models.
snapshot_dir = "/home1/xxx/caffe_ssd/models/VGGNet/VOC0712/{}".format(job_name)
# Directory which stores the job script and log file.
job_dir = "/home1/xxx/caffe_ssd/models/VGGNet/VOC0712/jobs/{}".format(job_name)
# Directory which stores the detection results.
output_result_dir = "/home1/xxx/caffe_ssd/models/VGGNet/VOC0712/results/VOC2007/{}/Main".format(job_name)
260行至270行那里,需要设置预训练模型、类别信息以及测试图片尺寸信息路径:
# Stores the test image names and sizes. Created by data/VOC0712/create_list.sh
name_size_file = "/home1/xxx/caffe_ssd/data/VOC0712/test_name_size.txt"
# The pretrained model. We use the Fully convolutional reduced (atrous) VGGNet.
pretrain_model = "/home1/xxx/caffe_ssd/models/VGGNet/VOC0712/VGG_ILSVRC_16_layers_fc_reduced.caffemodel"
# Stores LabelMapItem.
label_map_file = "/home1/xxx/caffe_ssd/data/VOC0712/labelmap_voc.prototxt"
330行那里,需要针对自己的GPU对代码进行相应的修改,我直接改成了1
gpus = "1"
gpulist = gpus.split(",")
num_gpus = len(gpulist)
340行、360行那里可能需要对batch_szie进行一定的修改,以确保不会内存溢出。
至此,ssd_pascal.py已经修改完毕。
终端执行:
python2 ssd_pascal.py
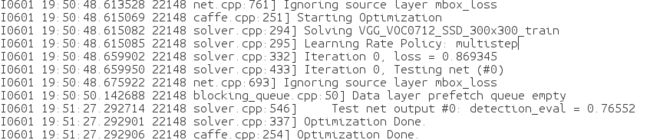
网络训练开始,迭代120000次之后,网络训练结束。
生成jobs、results、SSD_300x300三个文件夹
实验结果
- jobs
日志文件、网络结构等
- results
21个类别的分类信息
- SSD_300x300
模型保存、网络结构等
最终的一个mAP值是0.76552,略小于官方的0.776861,说明本次流程上是不会具有什么问题的。

网络模型测试
score_ssd_pascal.py
首先可以使用score_ssd_pascal.py进行一个测试,会给出模型的一个精度。
对该代码的修改和对ssd_pascal.py的修改差不多,就不再赘述。
python2 score_ssd_pascal.py
执行完毕,生成jobs_score、SSD_300x300_score两个文件夹。
- jobs_score

- SSD_300x300_score

打开日志文件:
可以看到结果基本一致。
ssd_detect.py
该文件会对测试图片进行类别预测和位置预测,并在图片上进行标注和绘制矩形框。
主要是对代码里的parse_args函数进行一些路径和名称修改。
def parse_args():
'''parse args'''
parser = argparse.ArgumentParser()
parser.add_argument('--gpu_id', type=int, default=0, help='gpu id')
parser.add_argument('--labelmap_file',
default='data/VOC0712/labelmap_voc.prototxt')
parser.add_argument('--model_def',
default='models/VGGNet/VOC0712/SSD_300x300/deploy.prototxt')
parser.add_argument('--image_resize', default=300, type=int)
parser.add_argument('--model_weights',
default='models/VGGNet/VOC0712/SSD_300x300/'
'VGG_VOC0712_SSD_300x300_iter_120000.caffemodel')
parser.add_argument('--image_file', default='examples/images/fish-bike.jpg')
return parser.parse_args()
测试图片结果:





根据测试结果我们可以看到,类别判断和定位的准确性还可以。
至此,我们已经完成SSD在Caffe下的从ssd安装编译、数据集制作到网络模型训练再到网络模型测试的所有过程。
希望能帮到大家,谢谢。
2019.7.10