IJCAI18 阿里妈妈广告
比赛的说明,还有比赛的链接IJCAI18
详细代码:github
这里,我们先进行一些数据分析,这里先说下我的设备,CPU内存128G,GPU GTX1080Ti 11G,但是只是工作站,所以图形显示就有点尴尬了。
round1_ijcai_18_train_20180301 :478138 日期:2018-09-18~2018-09-24 round1_ijcai_18_test_a_20180301 :18371 日期:2018-09-25
这里是训练集和测试集,日期是经过转化后的,原始数据经过了脱敏,脱敏方式是平移天为单位。其中,时间的转换代码如下:
def timestamp2datetime(timestamp):
dt = datetime.datetime.utcfromtimestamp(timestamp) + datetime.timedelta(hours=8)
return dt.strftime('%Y-%m-%d %H:%M:%S')此题的metric评价函数:
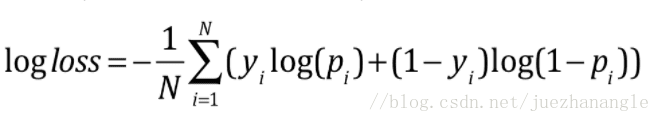
其中实现代码如下:
# 评价函数
def logloss(act, pred):
epsilon = 1e-15
pred = sp.maximum(epsilon, pred)
pred = sp.minimum(1-epsilon, pred)
ll = sum(act*sp.log(pred) + sp.subtract(1, act)*sp.log(sp.subtract(1, pred)))
ll = ll * -1.0/len(act)
return lltrain:
instance_id item_id item_category_list item_property_list item_brand_id item_city_id item_price_level item_sales_level item_collected_level item_pv_level user_id user_gender_id user_age_level user_occupation_id user_star_level context_id context_timestamp context_page_id predict_category_property shop_id shop_review_num_level shop_review_positive_rate shop_star_level shop_score_service shop_score_delivery shop_score_description is_trade
instance_id item_id item_category_list item_property_list item_brand_id item_city_id item_price_level item_sales_level item_collected_level item_pv_level user_id user_gender_id user_age_level user_occupation_id user_star_level context_id context_timestamp context_page_id predict_category_property shop_id shop_review_num_level shop_review_positive_rate shop_star_level shop_score_service shop_score_delivery shop_score_description
上面是训练集,下面是测试集,其中大部分数据都是经过脱敏的,所以都是以等级形式展示的。
然后,我们查看训练集中有多少instance_id,
# 查看train中含有多少不同的instance_id
df = df.drop_duplicates(['instance_id'])
l = df['instance_id'].tolist()
print "train中含有%s不同的instance_id"%len(l) # train中含有478087不同的instance_id在查看test中含有多少instance_id,
# 查看test中含有多少不同的instance_id
df_test = df_test.drop_duplicates(['instance_id'])
ll = df_test['instance_id']
print "test中含有%s个不同的instance_id"%len(ll) # test中含有18371个不同的instance_id查看这两个的交集:
# 查看test中instance_id是否在train中
print "相同的instance_id:", set(l) & set(ll) # 相同的instance_id: set([8860419674042916065, 892803262387109244, 4773277620195885623])然后,我们计算小时,将这个属性放到数据当中,
df['hour'] = [int(datetime.datetime.fromtimestamp(i).strftime('%H')) for i in df.context_timestamp]
# print df.head(2) # 能够添加当天的时间然后计算一下正负样本:
print "正样例",df[df['is_trade'] == 1].count() # 8994
print "负样例",df[df['is_trade'] == 0].count() # 469093我们可以发现,这是一个样本不平衡问题,需要在选用不同模型的时候,要考虑是否需要样本均衡问题。
然后,我们就做一些数据可视化
# 用户的星级和购买之间的关系
df_star = df[['user_age_level', 'is_trade']]
print df_star.head(3)
print "用户星级和购买之间的关系"
print df_star.groupby(['user_age_level']).agg('sum').reset_index()# 用户的星级和购买之间的关系 user_star_level is_trade 0 -1 12 1 3000 370 2 3001 347 3 3002 1236 4 3003 1445 5 3004 1217 6 3005 1260 7 3006 1572 8 3007 1048 9 3008 392 10 3009 90 11 3010 5
# 用户的年龄和购买之间的关系
df_star = df[['user_age_level', 'is_trade']]
print df_star.head(3)
print "用户年龄和购买之间的关系"
print df_star.groupby(['user_age_level']).agg('sum').reset_index()# 用户的年龄和购买之间的关系 user_age_level is_trade 0 -1 12 1 1000 177 2 1001 85 3 1002 1109 4 1003 2995 5 1004 2512 6 1005 1338 7 1006 645 8 1007 121
# 用户的职业和购买之间的关系
df_star = df[['user_occupation_id', 'is_trade']]
print df_star.head(3)
print "用户年龄和购买之间的关系"
print df_star.groupby(['user_occupation_id']).agg('sum').reset_index()# 用户的职业和购买之间的关系 user_occupation_id is_trade 0 -1 12 1 2002 2981 2 2003 86 3 2004 439 4 2005 5476
然后就是计算,一些属性和转化率之间的关系,比如年龄特征的转换率,但是这样会造成过拟合,因为我们使用了Y标签,即是否is_trade,这种特征构造方法,很容易造成过拟合的情况,但是可以线上测试。
# 用户年龄和购买之间的转化率关系
df_star = df[['user_age_level', 'is_trade']]
dd = df_star.groupby(['user_age_level']).agg('sum').reset_index()
# print dd
df_lv = df[['user_age_level']]
df_lv.loc[:, 'trade_sum'] = 1
ff = df_lv.groupby(['user_age_level']).agg('sum').reset_index()
# print ff
fv = dd['is_trade'] / ff['trade_sum']
user_age_trade = pd.concat([dd[['user_age_level']], fv], axis=1)
print user_age_trade另外一种写法,感觉代码复杂程度低一点,也可以参考:
# 不同年龄购买率
clean_train_data = df
user_age_trade = clean_train_data[['instance_id', 'user_age_level', 'is_trade']]
df = pd.get_dummies(clean_train_data['is_trade'], prefix='is_trade')
user_age_trade = pd.concat([user_age_trade[['instance_id', 'user_age_level']], df], axis=1)
user_age_trade = user_age_trade.groupby(['user_age_level'], as_index=False).sum()
user_age_trade['user_age_trade_ratio'] = user_age_trade['is_trade_1']/(user_age_trade['is_trade_1']+user_age_trade['is_trade_0'])
del user_age_trade['instance_id']
del user_age_trade['is_trade_0']
del user_age_trade['is_trade_1']
print user_age_trade我们能够得到不同年龄的购买率:
user_age_level user_age_trade_ratio 0 -1 0.012448 1 1000 0.013661 2 1001 0.013189 3 1002 0.015805 4 1003 0.017677 5 1004 0.019918 6 1005 0.023639 7 1006 0.021367 8 1007 0.023193
接下来,我们分析一下特征中两个比较重要的属性,
item_category_list item_property_list
这两个属性表示了商品的类别和属性的列表,格式形式需要查看赛题的描述,这里就不进行复述了。我们先得到列别和属性中最多含有多少的样本。这样就能够很好的进行处理数据。
df['category_list_sum'] = df.item_category_list.apply(lambda s: (len([d for d in s.split(';')])))
list_cate = df['category_list_sum']
print '类别的最大长度', max(list_cate)
df['item_property_sum'] = df.item_property_list.apply(lambda s: (len([d for d in s.split(';')])))
list_cate = df['item_property_sum']
print '属性的最大长度', max(list_cate)类别的最大长度 3 属性的最大长度 100我们得到这样的结果,对于属性的特征,我们还需要进一步的处理。因为100列的属性太多,很容易造成维度爆炸。
先做一个用户在当前小时内和当天的点击量统计特征,以及当前所在的小时。
def convert_data(data):
data['time'] = data.context_timestamp.apply(timestamp2datetime)
data['day'] = data.time.apply(lambda x: int(x[8:10]))
data['hour'] = data.time.apply(lambda x: int(x[11:13]))
user_query_day = data.groupby(['user_id', 'day']).size(
).reset_index().rename(columns={0: 'user_query_day'})
data = pd.merge(data, user_query_day, 'left', on=['user_id', 'day'])
user_query_day_hour = data.groupby(['user_id', 'day', 'hour']).size().reset_index().rename(
columns={0: 'user_query_day_hour'})
data = pd.merge(data, user_query_day_hour, 'left',
on=['user_id', 'day', 'hour'])
return data做类别属性的特征:
df['category_list'] = df.item_category_list.apply(lambda s: ([d for d in s.split(';')][1]))
print '类别第一个属性', df['category_list']将一些没有等级关系的属性转换成one-hot类型
def gender_to_onecode(data):
user_gender_trade = data[['instance_id', 'item_brand_id']]
df_gender = pd.get_dummies(user_gender_trade['item_brand_id'], prefix='item_brand_id')
data = pd.concat([data, df_gender], axis=1)
return data
查看属性的重要性:
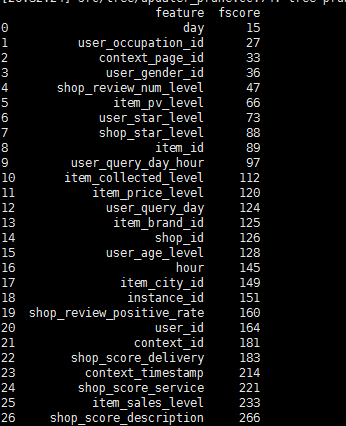
其中实现的代码:
train_y = df['is_trade'].values
df_train=df.drop(['riqi', 'time', 'item_category_list', 'item_property_list', 'predict_category_property', 'is_trade'], axis=1)
xgb_params = {
'max_depth': 7,
'nthread': 25,
'eta': 0.05,
'eval_metric': 'logloss',
'objective': 'binary:logistic',
'subsample': 0.7,
'colsample_bytree': 0.5,
'silent': 1,
'seed': 1,
'min_child_weight': 10
}
dtrain = xgb.DMatrix(df_train, train_y, feature_names=df_train.columns.values)
model = xgb.train(dict(xgb_params, silent=0), dtrain, num_boost_round=50)
features = [x for x in df_train.columns]
importance = model.get_fscore()
importance = sorted(importance.items(), key=operator.itemgetter(1))
df = pd.DataFrame(importance, columns=['feature', 'fscore'])
print df==========================================================
先放个baseline,明天在写,按照日期对训练集进行划分,最后一天作为验证集,前面的5天作为训练集。线下0.088,
采用xgboost的模型: 线上0.085
# -*- coding:utf-8 -*-
import pandas as pd
import numpy as np
import datetime
import scipy as sp
import xgboost as xgb
from sklearn.model_selection import train_test_split
# 评价函数
def logloss(act, pred):
epsilon = 1e-15
pred = sp.maximum(epsilon, pred)
pred = sp.minimum(1-epsilon, pred)
ll = sum(act*sp.log(pred) + sp.subtract(1, act)*sp.log(sp.subtract(1, pred)))
ll = ll * -1.0/len(act)
return ll
# 转换UNIX时间为正常时间
def timestamp2datetime(timestamp):
dt = datetime.datetime.utcfromtimestamp(timestamp) + datetime.timedelta(hours=8)
return dt.strftime('%Y-%m-%d %H:%M:%S')
'''
# df训练集的数据量:478138 日期:2018-09-18~2018-09-24
# df_test的预测量:18371 日期:2018-09-25
'''
dir = 'data/oria/'
df = pd.read_table(dir + 'round1_ijcai_18_train_20180301.txt', engine='python', sep=" ")
df_test = pd.read_table(dir + 'round1_ijcai_18_test_a_20180301.txt', engine='python', sep=" ")
# 转换df的时间属性
date_list = df['context_timestamp'].values
date_lste = []
for dates in date_list:
date_lste.append(timestamp2datetime(dates))
df['riqi'] = date_lste
# 转换df_test的时间属性
date_li = df_test['context_timestamp'].values
date_ls = []
for dates in date_li:
date_ls.append(timestamp2datetime(dates))
df_test['riqi'] = date_ls
'''
# 划分训练集和测试集 训练集2018-09-18~2018-09-23 测试集2018-09-24
'''
train = df[(df.riqi >= '2018-09-18 00:00:00') & (df.riqi <= '2018-09-23 23:59:59')]
test = df[(df.riqi >= '2018-09-24 00:00:00') & (df.riqi <= '2018-09-24 23:59:59')]
df_train_data = train.drop(['is_trade'], axis=1)
# 先将不能用的数据剔除 item_category_list, item_property_list, predict_category_property, riqi
df_train_data = train.drop(['is_trade', 'item_category_list', 'item_property_list', 'predict_category_property', 'riqi'], axis=1)
df_train_target = train['is_trade']
train_x, test_x, train_y, test_y = train_test_split(df_train_data, df_train_target, test_size=0.2, random_state=502)
params = {'max_depth':8,
'nthread':25,
'eta':0.1,
'eval_metric':'logloss',
'objective':'binary:logistic',
'subsample':0.7,
'colsample_bytree':0.5,
'silent':1,
'seed':1123,
'min_child_weight':10
#'scale_pos_weight':0.5
}
num_boost_round = 300
dtrain = xgb.DMatrix(train_x, train_y)
dvalid = xgb.DMatrix(test_x, test_y)
watchlist = [(dtrain, 'train'), (dvalid, 'eval')]
gbm = xgb.train(params, dtrain, num_boost_round, evals=watchlist,
early_stopping_rounds=200, verbose_eval=True)
res = gbm.predict(xgb.DMatrix(test_x))
print '本地cv:'
print logloss(test_y, res)
# 线下成绩: 0.0885740627643
'''
测试文件的生成
'''
df_test = df_test.drop(['item_category_list', 'item_property_list', 'predict_category_property', 'riqi'], axis=1)
answer = gbm.predict(xgb.DMatrix(df_test))
pd_result = pd.DataFrame({'instance_id': df_test["instance_id"], 'predicted_score': answer})
pd_result.to_csv('result_xgb_v1.txt', index=False, sep=' ', columns={'instance_id', 'predicted_score'})
print '完成训练'