数据集制作(pascal voc 格式)
PASCAL VOC数据集分析
https://blog.csdn.net/zhangjunbob/article/details/52769381
1)JPEGImages文件夹中包含了PASCAL VOC所提供的所有的图片信息,包括了训练图片和测试图片。图片的像素尺寸大小不一,但是横向图的尺寸大约在500*375左右,纵向图的尺寸大约在375*500左右,基本不会偏差超过100。(在之后的训练中,第一步就是将这些图片都resize到300*300或是500*500,所有原始图片不能离这个标准过远。)
2)Annotations文件夹中存放的是xml格式的标签文件,每一个xml文件都对应于JPEGImages文件夹中的一张图片。
3)ImageSets存放的是每一种类型的challenge对应的图像数据。主要关心Main文件夹。
Main文件夹下包含了20个分类的***_train.txt、***_val.txt和***_trainval.txt。
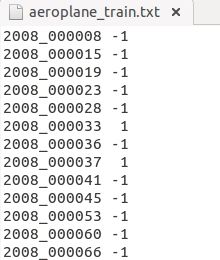
前面的表示图像的name,后面的1代表正样本,-1代表负样本。
_train中存放的是训练使用的数据,每一个class的train数据都有5717个。
_val中存放的是验证结果使用的数据,每一个class的val数据都有5823个。
_trainval将上面两个进行了合并,每一个class有11540个。
需要保证的是train和val两者没有交集,也就是训练数据和验证数据不能有重复,在选取训练数据的时候 ,也应该是随机产生的。
环境
ubuntu16.04
labelImg:https://blog.csdn.net/juwenkailaodi/article/details/85244761
步骤
1. 图片分类:先将图片按照不同的分类标准划分到不同的文件夹下。
2. resize:等比例缩放
https://www.cnblogs.com/xianglan/archive/2010/12/26/1917410.html
图像比例缩放是指将给定的图像在x轴方向按比例缩放,在y轴方向也按比例缩放,从而获得一幅新的图像。
如果两个方向上缩放比例相等,则为全比例缩放,否则为非全比例缩放。
比例缩放用矩阵形式可表示为:
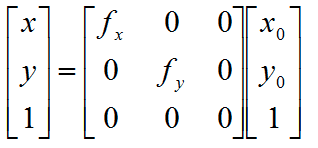
代数式为 :
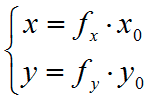
较为简单的缩小变换方法有:
1)基于等间隔采样的图像缩小方法
2)基于局部均值的图像缩小方法
设原图的矩阵为f[M*N],缩小后的矩阵为g[(M*m)*(N*n)],其中m和n为比例因子,由于原图像素点多,映射到g后会出现多点对一点的现象。
对于1)采用对画面像素均匀采样的方式保证所选像素仍旧可以保持原图像特征,即选择一些点,舍弃一些点,用选取的点组成一张图,使其和原图差不多。其映射方程为:
g(i,j) = f(i/m,j/n)
对于2)是采用局部均值的方式,对所有映射到g(i,j)上的点求取均值,即其映射矩阵为:
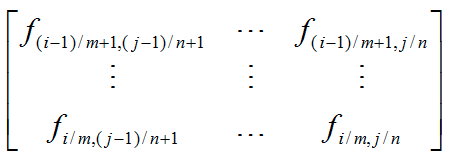
原图


1)基于等间隔采样的图像缩小方法 2)基于局部均值的图像缩小方法
由于1)会出现很多锯齿,而2)则相对比较平滑,但存在轻微的模糊效果。综合考量,在此选用基于局部均值的图像缩小方法。
3. 重命名
与voc2007保持一致。网上有蛮多比较赞的代码。
000392.jpg3.标注:labelImg
https://blog.csdn.net/weixin_38385446/article/details/81081172
修改默认类型:/home/whut/software/labelImg-master/data/predefined_classes.txt
然后就开始标注。
4. 合并,制作Main文件夹下的各个文件。
test.txt是测试集
train.txt是训练集
val.txt是验证集
trainval.txt是训练和验证集
VOC2007中,trainval大概是整个数据集的50%,test也大概是整个数据集的50%;train大概是trainval的50%,val大概是trainval的50%。
import os
import random
trainval_percent = 0.8
train_percent = 0.8
xmlfilepath = '/home/whut/2/voc_ship/Annotataions'
txtsavepath = '/home/whut/2/voc_ship/ImageSets/Main'
total_xml = os.listdir(xmlfilepath)
num=len(total_xml)
list=range(num)
tv=int(num*trainval_percent)
tr=int(tv*train_percent)
trainval= random.sample(list,tv)
train=random.sample(trainval,tr)
ftrainval = open('/home/whut/2/voc_ship/ImageSets/Main/trainval.txt', 'w')
ftest = open('/home/whut/2/voc_ship/ImageSets/Main/test.txt', 'w')
ftrain = open('/home/whut/2/voc_ship/ImageSets/Main/train.txt', 'w')
fval = open('/home/whut/2/voc_ship/ImageSets/Main/val.txt', 'w')
for i in list:
name=total_xml[i][:-4]+'\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest .close()根据已生成的xml,制作VOC2007数据集中的trainval.txt ; train.txt ; test.txt ; val.txt
trainval占总数据集的80%,test占总数据集的20%;train占trainval的80%,val占trainval的20%; 这样划分的原因是数据集比较少。
5. 统计train.txt中各个class的数量
这个值会有一定的用处。
至此,用修改了Annotations、ImageSets、JPEGImages\Main 三个文件夹的数据替换原来的数据,就可以跑自己的数据啦,当然可能该需要修改一些模型参数。
在此:可对生成的xml中的内容按照自己的需要进行更改。
https://github.com/XinZhangNLPR/Xml-document-modify
参考的文章:
https://blog.csdn.net/zhangjunbob/article/details/52769381
https://blog.csdn.net/weixin_38385446/article/details/81081172
https://blog.csdn.net/qq_29068265/article/details/80654514