win10+only-cpu利用Caffe框架测试mnist数据集
一、下载mnist数据集,正常步骤:在如下网站下载四个zip:http://yann.lecun.com/exdb/mnist/
但是从这里下载的数据集需要进行格式转换(转换方法以后会说到的),所以我现在选择下载现成的数据集如此zip文件

解压后得到这么两个文件夹:
![]()
(附:这了两个文件夹中的内容:
 )
)
将这两个文件夹放入D:/caffe-master/examples/mnist中(因为我把caffe-master解压在了D盘根目录下,大家自己寻找自己的caffe-master就可以了),
效果如图

二、修改相关文件
①在D:\caffe-master\examples\mnist中,用VS2013打开lenet_solver..protptxt文件,如图:![]()
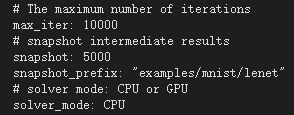
,拉到最后一行做如下修改:![]() ,该页面包括了最大迭代次数,max_iter,以及输出中间结果snapshot,如图所示:
,该页面包括了最大迭代次数,max_iter,以及输出中间结果snapshot,如图所示:
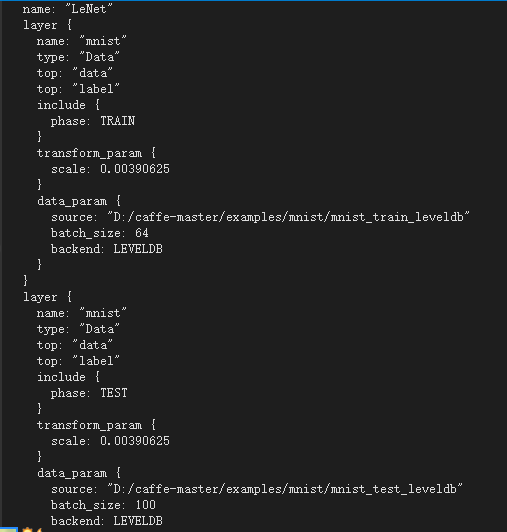
②在D:\caffe-master\examples\mnist中,用VS2013打开lenet_train_test.prototxt文件,如图:![]() ,进行如图所示修改,两个source,定位到数据集文件夹名字。
,进行如图所示修改,两个source,定位到数据集文件夹名字。
三、返回caffe-master所在目录中,新建一个txt文件,输入如下代码,效果如图
Build\x64\Debug\caffe.exe train --solver=examples\mnist\lenet_solver.prototxt
Pause

然后将后缀改为bat,效果如图,然后双击此文件,就进入训练了,效果如图
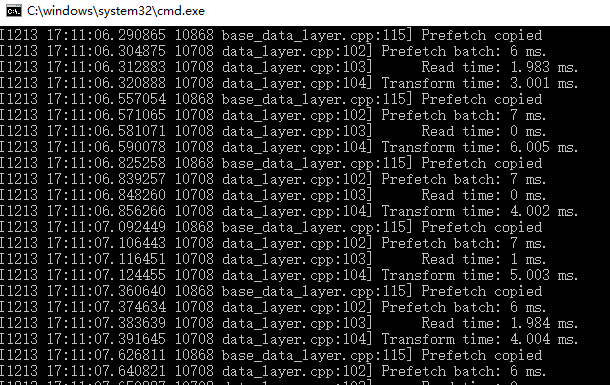
此过程caffe采用的GLOG库内方法打印的信息,这个库主要是起记录日志的功能,方便出现问题时查找根源,具体格式为:
【日期】【时间】【进程号】【文件名】【行号】
四、等待训练结束,如下图:
①
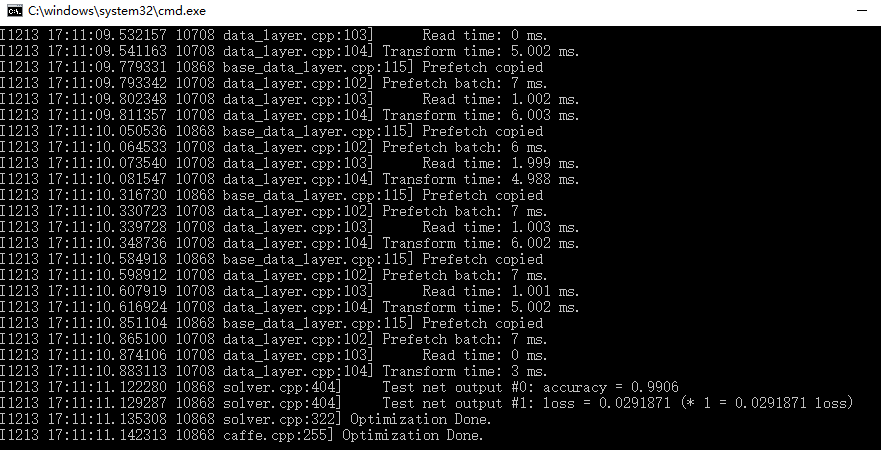
上面显示了训练精确率0.996
损失函数0.0291871
②在训练过程中:
中间有些比较长的部分,可以通过拉动窗口右侧小条找到
下图:

显示当前迭代次数和以及损失值,训练过程中不产生精确率accuracy
③当迭代次数达到lenet_solver.prototxt定义的max_iter时,就可以认为训练结束了,并且在训练结束后,在D:\caffe-master\examples\mnist文件夹中会多出如下四个文件:
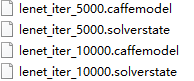
这时产生训练出的模型(文件后缀名为caffemodel和solverstate),它们分别是训练至一半(5000次)和训练最终(10000次)完成的模型,接下来就可以用这对模型对mnist的测试集和自己的手写字进行测试,接下来会说明如何测试。
五、测试数据集(摘自网络)
接下来就可以利用模型进行测试了,关于测试的方法按照以上教程还是选择bat文件,当然python、matlab更为方便,比如可以迅速把识别错误的图片显示出来。
①产生均值文件mean.binaryproto
在进行分类之前首先需要产生所有图片平均值图片,真正分类时的每个图片都会先减去这张平均值图片再进行分类。这样的处理方式能够提升分类的准确率。
产生均值文件的方法是利用解决方案中的compute_image_mean.exe,位于目录D:/caffe-master/Build/x64/Debug下。回到caffe-master根目录下创建一个mnist_mean.txt,写入如下内容:
Build\x64\Debug\compute_image_mean.exe examples\mnist\mnist_train_leveldb mean.binaryproto --backend=leveldb
pause
效果如图:
![]()
然后把.txt后缀改为.bat,文件如图所示:![]()
然后双击运行(其实写了那么多bat文件也因该有体会了,只要指定的路径正确就行,不一定非要放在caffe-master根目录下)。正确运行的话会在根目录下产生一个mean.binaryproto,也就是我们所需要的均值文件,如右图所示:![]()
接着为了使用均值文件需要稍微修改下层的定义(其实还是添加了如下图两行代码mean file的两行代码),然后用VS2013打开D:\caffe-master\examples\mnist\lenet_train_test.prototxt
并作如下修改,如图所示:
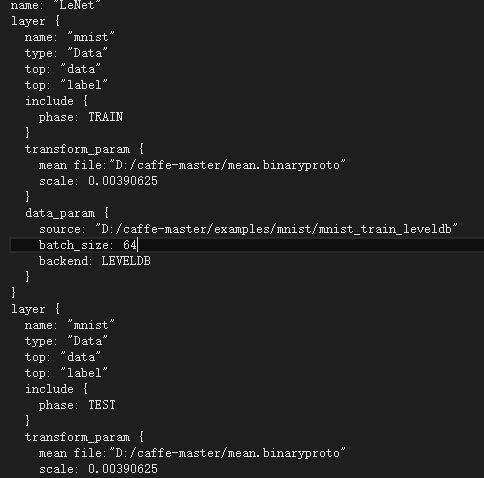
保存退出
至此,均值文件的预处理部分处理完毕,下面就可以进行测试了(至于为什么这样预处理,我也在学习中,知道的朋友还麻烦在下面评论区说一下,谢谢啦)。
②利用mnist数据集进行测试
这部分比较简单,因为之前生成的caffe.exe就可以直接用来进行测试。同样地在caffe-master根目录下新建mnist_test.txt,并写入如下内容(其中间断处都为一个空格)
内容如下:
.\Build\x64\Debug\caffe.exe test --model=examples/mnist/lenet_train_test.prototxt -weights=examples/mnist/lenet_iter_10000.caffemodel
pause
效果如图所示:
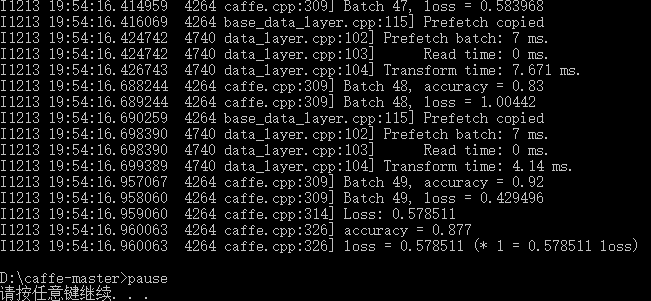
注意:这里的测试,指的是把训练出的模型,应用在刚才的训练集上,看一下测试精度。
③这一步往后就比较实用了,先介绍如何制作手写数字的单张测试样本。
必须使用经过二值化后的图片
把转换好的二值图像拷贝到D:\caffe-master\examples\mnist\
在D:\caffe-master\examples\mnist下建立标签文件synset_words.txt,如图所示![]()
里面输入如图所示:

④调用classification.exe去识别某张图片,D:\caffe-master目录新建mnist_class.bat
D:\caffe-master\Build\x64\Debug\classification.exe D:\caffe-master\examples\mnist\lenet.prototxt D:\caffe-master\examples\mnist\lenet_iter_10000.caffemodel D:\caffe-master\mean.binaryproto D:\caffe-master\examples\mnist\synset_words.txt D:\caffe-master\examples\mnist\binarybmp\0.bmp
pause
注意:此处使用的lenet.prototxt是一个deploy文件,这个文件只是高速分类程序(mnist_classification.exe)网络结构是怎么样子的,不需要反向计算,不需要计算误差。
然后得到如图所示结果:

解释一下结果:在最后的分类结果中,一共显示了5行(据说程序中可以控制,但是我并没有找到),表示输入的这张图片与它最像的有这5类,前面的0和1表示得分,这5行前面的得分和应该为1,也就是1+0+0+0+0=1,第一项得分最高,所以识别此图为6.
⑤接下来我打算自己用画图做一个试一下,
这是我用画图做的,如图所示
 (这是桌面截图,把下面的89.bmp截图的目的是待会儿给大家看一下怎么修改网络)
(这是桌面截图,把下面的89.bmp截图的目的是待会儿给大家看一下怎么修改网络)
怕格式(包括大小以及像素问题)不正确,我用它的图片集修改的,然后输入到网络中,也就是在上一步中建立的mnist_class.bat中用记事本打开,做如图所示修改:

保存退出,双击mnist_class.bat,开始运行,得到如下结果:
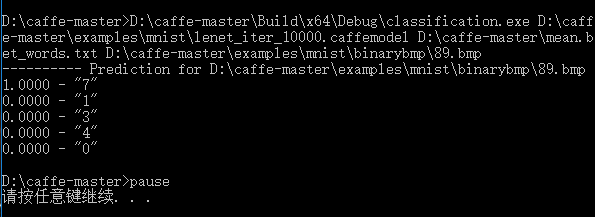
“7”得分最高,所以网络识别图片中的数字为7
自己制作数据集成功!