hive 窗口函数,分析函数的一些理解
一.先解释什么是窗口函数
首先,我们要知道什么是窗口子句:
需要指定一个窗口的边界,语法是这样的:
ROWS betweenCURRENT ROW | UNBOUNDED PRECEDING | [num] PRECEDING AND UNBOUNDED FOLLOWING | [num] FOLLOWING| CURRENT ROW
或
RANGE between [num] PRECEDING AND [num]FOLLOWING
如下图:
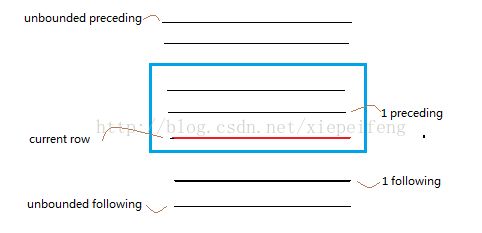
ROWS是物理窗口,从行数上控制窗口的尺寸的;
RANGE是逻辑窗口,从列值上控制窗口的尺寸。这个比较难理解,但说白了就简单了
普通的聚合函数用group by分组,每个分组返回一个统计值,而分析函数采用partition by分组,并且每组每行都可以返回一个统计值
开窗函数over(),包含三个分析子句:分组(partition by), 排序(order by), 窗口(rows) ,他们的使用形式如下:over(partition by xxx order by yyy rows between zzz)
窗口就是分析函数分析时要处理的数据范围,就拿sum来说,它是sum窗口中的记录而不是整个分组中的记录,因此我们在想得到某个栏位的累计值时,我们需要把窗口指定到该分组中的第一行数据到当前行, 如果你指定该窗口从该分组中的第一行到最后一行,那么该组中的每一个sum值都会一样,即整个组的总和。
注释:
当开窗函数over()出现分组(partition by)子句时,
unbounded preceding即第一行是指表中一个分组里的第一行, unbounded following即最后一行是指表中一个分组里的最后一行;
当开窗函数over()省略了分组(partition by)子句时,
unbounded preceding即第一行是指表中的第一行, unbounded following即最后一行是指表中的最后一行。
而无论是否省略分组子句,如下结论都是成立的:
1、窗口子句不能单独出现,必须有order by子句时才能出现。
2、当省略窗口子句时:
a) 如果存在order by则默认的窗口是unbounded preceding and current row --当前组的第一行到当前行,即在当前组中,第一行到当前行
b) 如果同时省略order by则默认的窗口是unbounded preceding and unbounded following --整个组
所以,
lag(sal) over(order by sal) 解释
over(order by salary)表示意义如下:
首先,我们要知道由于省略分组子句,所以当前组的范围为整个表的数据行,
然后,在当前组(此时为整个表的数据行)这个范围里执行排序(即order by salary),
最后,我们知道分析函数lag(sal)在当前组(此时为整个表的数据行)这个范围里的窗口范围为当前组的第一行到当前行,即分析函数lag(sal)在这个窗口范围执行。
rank(),dense_rank()与row_number():求排序
rank,dense_rank,row_number函数为每条记录产生一个从1开始至n的自然数,n的值可能小于等于记录的总数。这3个函数的唯一区别在于当碰到相同数据时的排名策略。
①row_number:
row_number函数返回一个唯一的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。
②dense_rank:
dense_rank函数返回一个唯一的值,当碰到相同数据时,此时所有相同数据的排名都是一样的。
③rank:
rank函数返回一个唯一的值,当碰到相同的数据时,此时所有相同数据的排名是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间空出排名。
二、窗口函数
first_value(求组的第一个值)
select id,money,
first_value(money) over (partition by id order by money
rows between 1 preceding and 1 following)
from winfunc
每行对应的数据窗口是从第一行到最后一行
rows between unbounded preceding and unbounded following
lead(money,2) 取后面距离为2的记录值,没有就取null
select id,money,lead(money,2) over(order by money) from winfunc
lag(money,2)于lead相反
rank()排序函数与row_number()
select id,money, rank() over (partition by id order by money) from winfunc
结果
1001 100 1
1001 150 2
1001 150 2
1001 200 4
dense_rank()
select id,money, dense_rank() over (partition by id order by money) from winfunc
结果
1001 100 1
1001 150 2
1001 150 2
1001 200 3
cume_dist()
计算公式:CUME_DIST 小于等于当前值的行数/分组内总行数–比如,统计小于等于当前薪水的人数,所占总人数的比例
select id,money, cume_dist() over (partition by id order by money) from winfunc
结果
1001 100 0.25
1001 150 0.75
1001 150 0.75
1001 200 1
percent_rank(),第一个总是从零开始
PERCENT_RANK() = (RANK() – 1) / (Total Rows – 1)
计算公式:(相同值最小行号-1)/(总行数-1)
结果
1001 100 0
1001 150 0.33
1001 150 0.33
1001 200 1
ntile(2) 分片
asc时, nulls last为默认
desc时, nulls first为默认
select id,money, ntile(2) over (order by money desc nulls last) from winfunc;
混合函数(使用java里面的方法)
java_method和reflect是一样的
select java_method("java.lang.Math","sqrt",cast(id as double)) from winfunc;
UDTF表函数explode()配合lateral view关键字
select id ,adid from winfunc lateral view explode(split(type,'B')) tt as adid
1001 ABC
列转行
1001 A
1001 C
正则表达式函数
like 字符"_"表示任意单个字符,而字符"%"表示任意数量的字符
rlike后面跟正则表达式
select 1 from dual where 'footbar' rlike '^f.*r$';
正则表达式替换函数
regexp_replace(string A,string B,string C)
将字符串A中符合java正则表达式B的部分替换为C
select regexp_replace('foobar','oo|ar','') from dual;
返回fb
regexp_extract(string subject,string pattern,int index)
select regexp_extract('foothebar','foo(.*?)(bar)',1) from dual;
返回the,()正则表达式中表示组,1表示第一个组的索引
1.贪婪匹配(.*), |一直匹配到最后一个|
select regexp_extract('979|7.10.80|8684','.*\\|(.*)',1) from dual;
返回8684
2.非贪婪匹配(.*?)加个问号告诉正则引擎,尽可能少的重复上一个字符
select regexp_extract('979|7.10.80|8684','(.*?)\\|(.*)',1) from dual;