深度学习的attention机制笔记
原文 关于深度学习中的注意力机制,这篇文章从实例到原理都帮你参透了 不能转载,就自己摘要了一些.
attention机制源于人类快速处理视觉信息的大脑机制.通过重点关注目标区域,抑制无关区域,从而从大量信息中快速筛选出有价值的信息
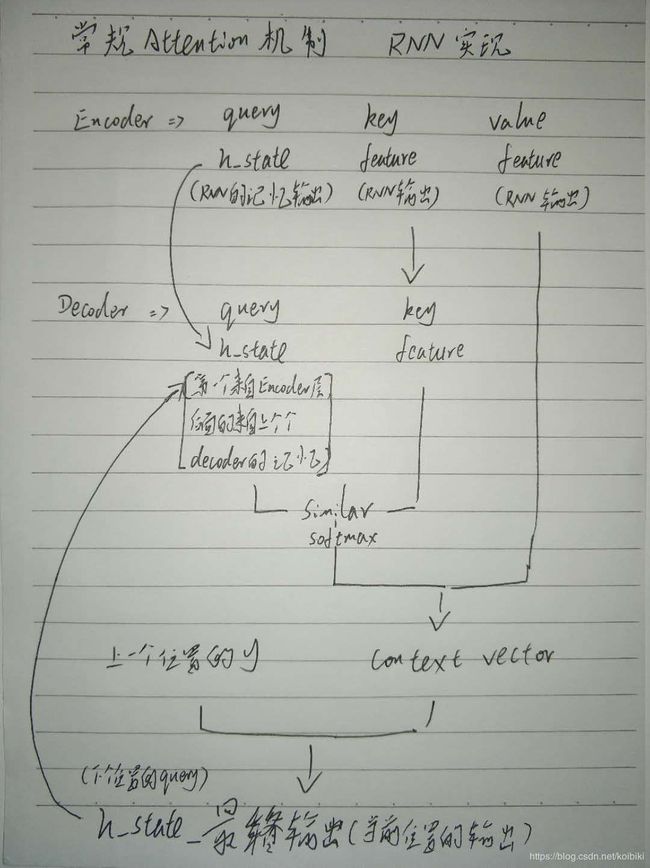
Encoder-Decoder 框架
目前attention机制主要依赖于encoder-decoder框架
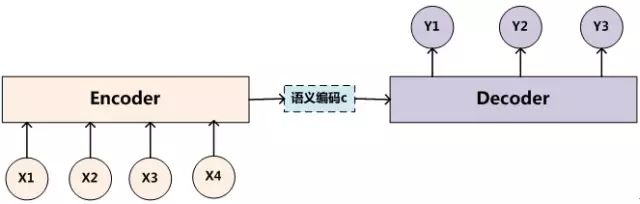
上图为Encoder-Decoder框架的抽象表示.
Encoder-Decoder框架可以看成一个由句子(段落,图片)生成另一个句子(段落、图片、字符串)的通用模型.
以在文本处理领域中机器翻译应用为例,对于句子对
Encoder用于对source进行编码,通过非线性变换得到中间矩阵C
![]()
Decoder用于解码生成target,其任务是根据句子X的中间语义表示C和之前已经生成的历史信息y1,y2….yi-1来生成i时刻要生成的单词yi
![]()
每个yi都依次这么产生,那么看起来就是整个系统根据输入句子X生成了目标句子Y。
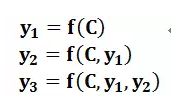
原始的Encoder-Decoder在生成每个 ![]() 时均使用的同一个C,这意味着source中的每个单词对输出中的每个单词的影响是相同的。但实际情况下,英文 Tom chase Jerry 翻译为中文 汤姆追求杰瑞。Tom对于汤姆的影响应该最大。
时均使用的同一个C,这意味着source中的每个单词对输出中的每个单词的影响是相同的。但实际情况下,英文 Tom chase Jerry 翻译为中文 汤姆追求杰瑞。Tom对于汤姆的影响应该最大。
因此引入attention机制,使得source中的每个单词对输出的不同单词具有不同权重的影响。
在翻译“杰瑞”的时候,体现出英文单词对于翻译当前中文单词不同的影响程度,比如给出类似下面一个概率分布值:
(Tom,0.2)(Chase,0.1) (Jerry,0.5)
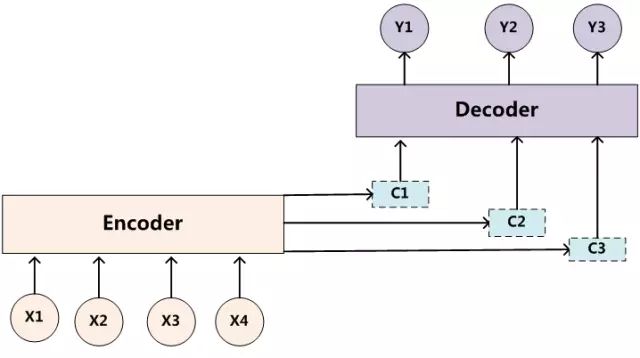
即生成目标句子单词的过程成了下面的形式:
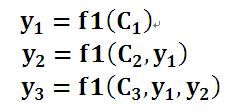
而每个Ci可能对应着不同的源语句子单词的注意力分配概率分布,比如对于上面的英汉翻译来说,其对应的信息可能如下:

其中,f2函数代表Encoder对输入英文单词的某种变换函数,比如如果Encoder是用的RNN模型的话,这个f2函数的结果往往是某个时刻输入 ![]() 后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,即下列公式:
后隐层节点的状态值;g代表Encoder根据单词的中间表示合成整个句子中间语义表示的变换函数,一般的做法中,g函数就是对构成元素加权求和,即下列公式:
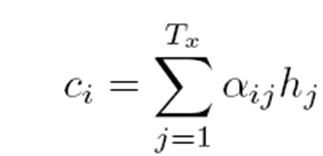
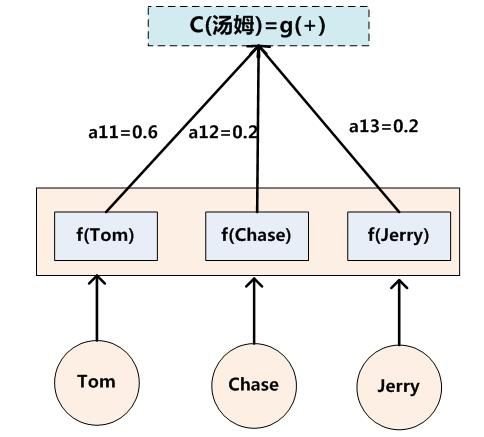
假设Ci中那个i就是上面的“汤姆”,那么Tx就是3,代表输入句子的长度,h1=f(“Tom”),h2=f(“Chase”),h3=f(“Jerry”),对应的注意力模型权值分别是0.6,0.2,0.2,所以g函数就是个加权求和函数。如果形象表示的话,翻译中文单词“汤姆”的时候,数学公式对应的中间语义表示Ci的形成过程类似下图:
这里还有一个问题:生成目标句子某个单词,比如“汤姆”的时候,如何知道Attention模型所需要的输入句子单词注意力分配概率分布值呢?就是说“汤姆”对应的输入句子Source中各个单词的概率分布:(Tom,0.6)(Chase,0.2) (Jerry,0.2) 是如何得到的呢?
为了便于说明,我们假设对图2的非Attention模型的Encoder-Decoder框架进行细化,Encoder采用RNN模型,Decoder也采用RNN模型,这是比较常见的一种模型配置,则图2的框架转换为图5。

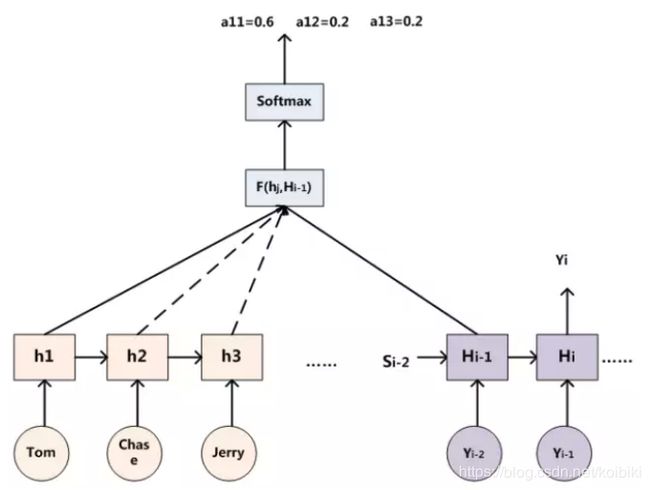
对于采用RNN的Decoder来说,在时刻 ![]() ,如果要生成
,如果要生成 ![]() 单词,我们是可以知道Target在生成
单词,我们是可以知道Target在生成 ![]() 之前的时刻
之前的时刻 ![]() 时,隐层节点
时,隐层节点 ![]() 时刻的输出值
时刻的输出值 ![]() 的,而我们的目的是要计算生成
的,而我们的目的是要计算生成 ![]() 时输入句子中的单词“Tom”、“Chase”、“Jerry”对
时输入句子中的单词“Tom”、“Chase”、“Jerry”对 ![]() 来说的注意力分配概率分布,那么可以用Target输出句子
来说的注意力分配概率分布,那么可以用Target输出句子 ![]() 时刻的隐层节点状态
时刻的隐层节点状态 ![]() 去一一和输入句子Source中每个单词对应的RNN隐层节点状态
去一一和输入句子Source中每个单词对应的RNN隐层节点状态 ![]() 进行对比,即通过函数
进行对比,即通过函数 ![]() 来获得目标单词
来获得目标单词 ![]() 和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
和每个输入单词对应的对齐可能性,这个F函数在不同论文里可能会采取不同的方法,然后函数F的输出经过Softmax进行归一化就得到了符合概率分布取值区间的注意力分配概率分布数值。
常用的 F 函数包括 dot、general、concat和MLP。
Attention机制的本质
把Attention机制从上文讲述例子中的Encoder-Decoder框架中剥离,并进一步做抽象,可以更容易看懂Attention机制的本质思想。
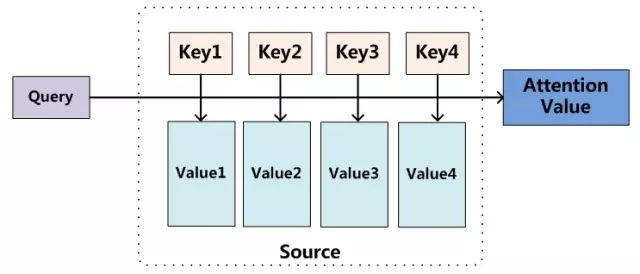
我们可以这样来看待Attention机制(参考图9):将Source中的构成元素想象成是由一系列的

当然,从概念上理解,把Attention仍然理解为从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息,这种思路仍然成立。聚焦的过程体现在权重系数的计算上,权重越大越聚焦于其对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
至于Attention机制的具体计算过程,如果对目前大多数方法进行抽象的话,可以将其归纳为两个过程:第一个过程是根据Query和Key计算权重系数,第二个过程根据权重系数对Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据Query和Key计算两者的相似性或者相关性;第二个阶段对第一阶段的原始分值进行归一化处理;这样,可以将Attention的计算过程抽象为如图10展示的三个阶段。
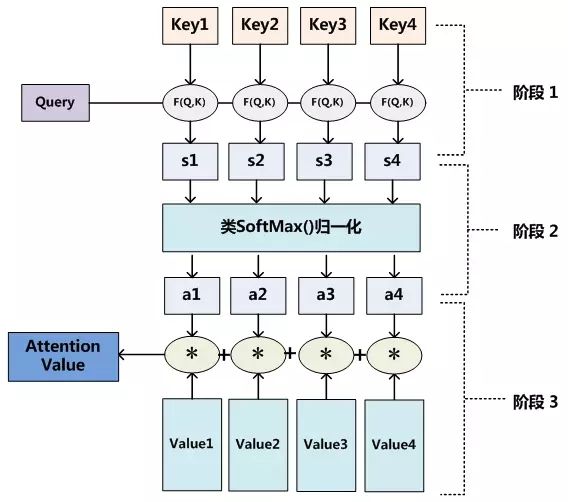
图10 三阶段计算Attention过程
在第一个阶段,可以引入不同的函数和计算机制,根据Query和某个keyi,计算两者的相似性或者相关性,最常见的方法包括:求两者的向量点积、求两者的向量Cosine相似性或者通过再引入额外的神经网络来求值,即如下方式:

第一阶段产生的分值根据具体产生的方法不同其数值取值范围也不一样,第二阶段引入类似SoftMax的计算方式对第一阶段的得分进行数值转换,一方面可以进行归一化,将原始计算分值整理成所有元素权重之和为1的概率分布;另一方面也可以通过SoftMax的内在机制更加突出重要元素的权重。即一般采用如下公式计算:

通过如上三个阶段的计算,即可求出针对Query的Attention数值,目前绝大多数具体的注意力机制计算方法都符合上述的三阶段抽象计算过程。
对于常规的RNN结构, query 就是 上一个 RNN 的输出状态 h(表示当前需要查询位置),key 和 value 都是 Encoder 输出的结果向量 output。