Hadoop集群单机版搭建
Hadoop集群单机版搭建
首先本文是基于CentOS 7 , jdk1.8.0_141 和Hadoop2.7.3环境搭建
1. CentOS的安装
首先准备好CentOS7 64位的镜像
然后在VMware上安装虚拟机
这里注意选择镜像自动检测CentOS 64位, 不然之后步骤比较麻烦

其他步骤都与普通安装虚拟机一样,直接默认下一步,然后开启虚拟机
这里直接进行回车继续即可

语言选择可以选择简体中文
这时选择安装位置,直接点击完成即可,这样才能继续下一步操作

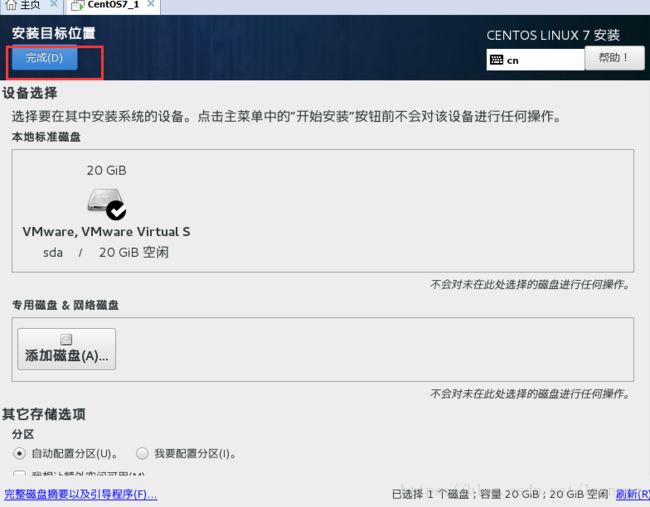
然后开始安装,设置并且设置root密码

然后重新开机登录root账号即可,成功登录则表示CentOS安装成功
2. 设置Linux静态ip
开机完成后需要我们设置静态ip,这样之后开机都不需要dhclient动态分配ip地址
首先找到/etc/sysconfig/network-scripts/下的ifcfg-ens33配置文件(如果没有找到此文件,说明你没有选择安装CentOS64位系统,建议重新安装)
vi /etc/sysconfig/network-scripts/ifcfg-ens33
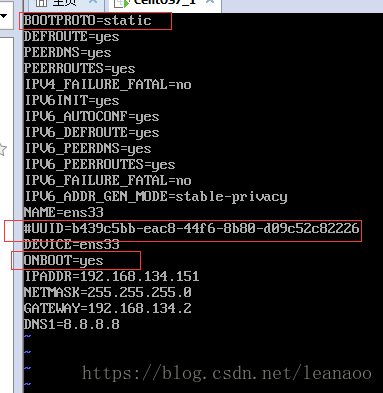
2.首先把BOOTPROTO="dhcp"改成BOOTPROTO="static"表示静态获取,然后把UUID注释掉,把ONBOOT=no改为yes表示开机自动静态获取,然后在最后追加比如下面的配置:
IPADDR=192.168.134.151 #自己的ip地址
NETMASK=255.255.255.0
GATEWAY=192.168.134.2
DNS1=8.8.8.8
IPADDR就是静态IP,NETMASK是子网掩码,GATEWAY就是网关或者路由地址;需要说明,原来还有个NETWORK配置的是局域网网络号,这个是ifcalc自动计算的,所以这里配置这些就足够了,最终配置如下图:
如果不知道自己的GATEWAY可以去虚拟机的编辑查看虚拟网络编辑器中的NAT设置

最后保存退出
重启服务
centos6的网卡重启方法:service network restart
centos7的网卡重启方法:systemctl restart network
然后查看自己的ip地址是不是自己设置的
centos6的查看ip方法: ifconfig
centos7的查看ip方法: ip addr

接下来可以用Xshell工具连接虚拟机了,这样比较好操作(如果没有此工具的需要去官网下载,Xshell和配套的文件传输工具Xftp,都有免费版本)

3. JDK的安装
首先在usr的目录下创建一个java文件夹用来存放jdk的安装包并作为安装路径

这时候新建文件传输,将jdk的压缩包放入到CentOS中

然后解压jdk
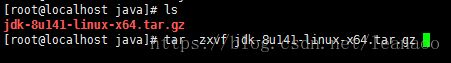
解压完成之后返回到根目录的etc文件夹下,改写profile配置文件 vi /etc/profile
在profile最后加上:
export JAVA_HOME=/usr/java/jdk1.8.0_141
export JAVA_BIN=/usr/java/jdk1.8.0_141/bin
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
保存退出,source /etc/profile刷新配置文件
用java -version看看jdk环境是否配置完毕
4. 修改主机名和ip映射
修改etc文件夹下的hosts文件vi /etc/hosts
如图:
5. 安装hadoop并修改配置文件
在usr文件夹下创建hadoop文件夹作为压缩包存放和解压路径,将hadoop的压缩包传输到此文件夹下
然后解压 tar -zxf hadoop-2.7.3.tar.gz
5.1配置proflie文件
注意:hadoop2.x的配置文件$HADOOP_HOME/etc/hadoop
在etc的profile最后添加,然后source刷新配置文件
export HADOOP_HOME=/usr/hadoop/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
接下来需要改五个配置文件
5.2 第一个:hadoop-env.sh
进入到hadoop-2.7.3/etc/hadoop文件夹下,修改hadoop-env.sh vi hadoop-env.sh
第25行将

改为
![]()
保存退出
5.3 第二个 core-site.xml
在configuration中加上
fs.defaultFS
hdfs://zhiyou:9000
hadoop.tmp.dir
/zhiyou/hadoop/tmp
保存退出
5.4 第三个 hdfs-site.xml
同上configuration中添加
dfs.replication
1
dfs.namenode.name.dir /usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir /usr/local/hadoop/tmp/dfs/data
5.5 第四个mapred-site.xml
这个是需要你复制一个模版文件出来的 cp mapred-site.xml.template mapred-site.xml
然后 vi mapred-site.xml添加
mapreduce.framework.name
yarn
保存退出
5.6 第五个 yarn-site.xml
yarn.resourcemanager.hostname
zhiyou
yarn.nodemanager.aux-services
mapreduce_shuffle
6.格式化namenode(是对namenode进行初始化)
hadoop namenode -format
如果没有报错说明配置文件成功,否则重新检查配置文件
7.启动hadoop
先启动HDFS
start-dfs.sh
再启动YARN
start-yarn.sh
这里需要yes三次并输入你的root密码三次
8.验证是否启动成功
jps
3912 DataNode
4378 Jps
4331 NodeManager
4093 SecondaryNameNode
3822 NameNode
4239 ResourceManager
关闭防火墙
#停止firewall
systemctl stop firewalld
systemctl disable firewalld.service #禁止firewall开机启动
浏览器查看
http://ip地址:50070 (HDFS管理界面)
http://ip地址:8088 (yarn管理界面)
如果页面正常则说明hadoop配置成功
有人觉得每次启动都需要输入密码很繁琐,那么就设置ssh免密登录
9.设置ssh免密登录
#生成ssh免登陆密钥
#进入到我的home目录
cd ~/.ssh
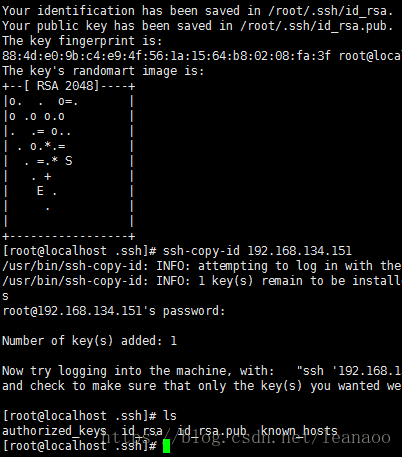
ssh-keygen -t rsa (四个回车)
执行完这个命令后,会生成两个文件id_rsa(私钥)、id_rsa.pub(公钥)
将公钥拷贝到要免登陆的机器上
ssh-copy-id 192.168.134.151
然后重新启动虚拟机reboot
进入到hadoop下的sbin文件夹
cd /usr/hadoop/hadoop-2.7.3/sbin
有个start-all.sh和stop-all.sh,这是启动和停止所有服务,这样更加快捷
启动之后再次验证是否启动成功
至此,基本的搭建已经完成