Hive进阶(1)—— 压缩
压缩简介 & 为什么使用压缩 & 常用压缩技术
压缩简介
用户行为数据 GB TB … 越来越大
数据量越来越大 ==> 面对问题:如何高效的处理 ==> 优化
Hadoop生态系统 :对数据进行压缩处理使得提高我们的数据处理效率
如何选择和使用压缩 就是一个至关重要的问题 摆在我们面前
压缩工具:winrar、7-zip
压缩:
- 使用压缩技术来把数据“减少”的过程
解压缩:
- 将压缩过后的数据转换成原始数据的过程
为什么要使用压缩
- reduce file size
减少文件大小 - save disk space
节省磁盘空间 - Increase transfer speed at a given data rate
增加网络传输的效率
常用的压缩技术
Mainly two general types:
- Lossless compression
无损压缩
原始数据 对比 经过压缩再解压后的数据 肯定是一样的
也就是说压缩和解压缩的过程中是没有数据会丢失的
提出问题: 在压缩的过程中,多余的数据干嘛去了?- 多余的数据必然是冗余的数据
借助一些算法,冗余的数据在压缩的过程中会被移除
在解压的过程中,借助同样的算法,再把它自动的补充上来 - 适用场景:
用户行为日志
如果是用来做计费的,数据必然是不能丢的,丢了公司就少盈利了
- 多余的数据必然是冗余的数据
- Lossy compression
有损压缩(对于图片、视频的处理,可以采用有损压缩)
压缩过后和压缩之前的数据有损失
图片和视频丢掉几帧,凭肉眼是很难被区分出来的
有好处:- 技术成本低,压缩率 压缩比非常高 能够更节省空间,而且压缩的时间也非常短
压缩场景(以MapReduce为例)
从3个角度来看:输入、中间、输出
-
输入
如果输入文件是经过压缩的,那么数据压缩过后所占用的HDFS的空间就会少很多
通常情况下,也就意味着读取数据所耗费的时间也就比较少
但也有种情况下读取耗费的时间多(如果你的CPU跟不上,也是不行的)MapReduce/Hive/Spark这些框架是可以读取压缩文件的,它们会自动进行解压
这些计算框架在读取文件之后,具备自动解压文件的功能
数据有没有压缩,分布式处理框架都是能自动识别的,并不需要去做额外的东西涉及到一个问题:
- 不同的压缩方式它的codec是不一样的
比如:GzipCodec…
- 不同的压缩方式它的codec是不一样的
-
中间
以MapReduce来看,Map过程之后是有输出的
如果在做shuffle之前,对数据使用压缩,必然是会减少磁盘空间,
而在shuffle过程因为体积减少,传输效率也是会提高的
建议:中间过程也是采用压缩 -
输出
对于输出也是同理的,如果对于输出的文件是作为历史文件的,更应该使用压缩,而且需要选用压缩比非常高的压缩方式
这样历史数据,占用空间肯定少了
总结:
对于上述三点,不管哪一步,都建议采用压缩,
前提:CPU(如果CPU都不够用,就别采用压缩了)
压缩注意事项
从上述的来看,压缩能带来的好处有:
- 节省存储空间、加速数据传输、减少磁盘与网络的IO
- 这些对于大数据的执行性能是有改善的
但是压缩/解压缩的过程,CPU的利用率是很高的
在使用的时候,是针对集群的状况来做取舍的,如下图所示:
对于压缩的使用,是需要结合实际生产环境进行权衡的
压缩格式(测试压缩比&压缩速率)
| Compression format | Tool | Algorithm | File extention |
|---|---|---|---|
| Gzip | gzip | DEFLATE | .gz |
| Bzip2 | bzip2 | bzip2 | .bz2 |
| LZO | lzop | LZO | .lzo |
| Snappy | N/A | Snappy | .snappy |
测试环境:
8 core
i7 CPU
8GB memory
64 bit CentOS
1.4GB Wikipedia Corpus 2-gram text input(1.4G文本类型的数据)
压缩效果如下图所示:
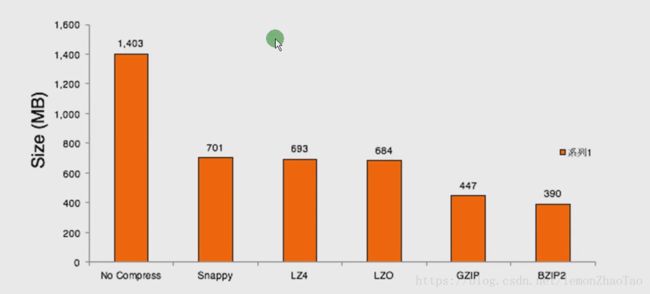
Compression Ratio:BZIP2 > GZIP > LZO
压缩解压缩时间小姑如下图所示:

压缩比和压缩速度成反比(因为你的压缩比越高,那么你压缩过后的数据也就越少,这样压缩所需要耗费的时间也就越多)
比如:BZIP2压缩效果最好,但是压缩解压缩时间最慢
Compression Speed:LZO > GZIP > BZIP2
选择合适的压缩格式
根据实际的业务场景来说:
- 老/冷数据(即平时用的不多的数据)
选择压缩比高(因为既然作为历史的东西,肯定是用的不多的) - Flume收集上来的数据
选择压缩速度快的 & 选择是否支持分割
如何选择压缩格式,是需要出于对时间/空间的权衡的,如下图所示:

是否支持分割
对于Hadoop/Spark作业(Hadoop指生态,Hive也是一样):
这些作业通常情况下,有一个特点,IO密集型(因为数据读取对于磁盘IO、网络IO等各方面都是比较重的)
能否支持分割对于一个作业的运行效率有很大的影响
假设数据大小为1G ==> 如果不支持分割,只能由1个mapper去处理
不支持分割的话,不管你的速度多快,肯定也会拖慢整个作业的执行时间,进而影响作业执行效率
$> hadoop checknative
会出现一堆false ==> 会影响压缩的使用
建议:Hadoop编译native使得支持native + snappy
参考Blog:编译hadoop2.6.0-cdh5.7.0 native支持snappy & 编译中遇到的坑及解决办法
压缩格式是否支持分割需要知道,这样有助于生产上的选型:
| Compression format | Tool | Algorithm | File extention | Splittable |
|---|---|---|---|---|
| Gzip | gzip | DEFLATE | .gz | No |
| Bzip2 | bzip2 | bzip2 | .bz2 | Yes |
| LZO | lzop | LZO | .lzo | Yes if indexed |
| Snappy | N/A | Snappy | .snappy | No |
关于压缩格式是否支持分割的相关解读:
When considering how to compress data that will be processed by MapReduce,it is important to understand whether the compression format supports splitting;Splittability must be taken into account;
当我们考虑如何去压缩我们的数据的时候。这是很重要的,去理解压缩格式是否支持分割分割必须被考虑在内
If a compression method is splittable,every compressed input split can be extracted and processed independently.
如果一个压缩方法是可以分割的,那么每个被压缩的文件被split之后就能被抽取出来,然后进行独立的处理
Split1.rar --> Decompress --> Mapper
Split2.rar --> Decompress --> Mapper
Split3.rar --> Decompress --> Mapper
Split4.rar --> Decompress --> Mapper
举例:
1个文件1个G 和 4个文件1个G
这样对比,必然是后者处理起来速度要更快一些的
如果不支持分割,只能进行串行的处理;如果支持分割,就能进行并行的处理
关于压缩(是否支持分割)的例子:
Consifer an uncompressed file stored in HDFS whose size 1GB.With an
HDFS block size of 64MB,the file will be stored as 16 blocks, and a
MapReduce job using this file as input will create 16 input
splits,each processed independently as input to a separate map task.
没有压缩的1G文件,block默认为64MB,会产生16个block
MapReduce job会为其创建16个input splits,有16个map task去处理
If the file were an GZIP file,a single map will process the 16 HDFS
blocks,most of which will not be local to the map.Also,with fewer
maps,so many take longer to run.
如果使用GZIP压缩(不支持分割),就只会有一个map task去处理,那么速度会慢很多
常用codec
| 压缩格式 | 类 |
|---|---|
| Zlib | org.apache.hadoop.io.compress.DefaultCodec |
| Gzip | org.apache.hadoop.io.compress.GzipCodec |
| Bzip2 | org.apache.hadoop.io.compress.BZip2Codec |
| Lzo | com.hadoop.compression.lzo.LzoCodec |
| Lzo | org.apache.hadoop.io.compress.Lz4Codec |
| Snappy | org.apache.hadoop.io.compress.SnappyCodec |
压缩在MapReduce中的应用(理论)

如上图所示,对于每个环节的技术选型如下:
- Use Compressed Map Input(从输入层面考虑)
- Mapreduce jobs read input from HDFS
MapReduce job从HDFS读数据 - Compress if input data is large.This will reduce disk read cost
如果输入数据大的话采用压缩,这样将会减少磁盘数据的读取 - Compress with splittable algorithms like Bzip2
压缩得考虑split是否支持 - Or use compression with splittable file structures such as Sequence Files, RC File etc
使用压缩支持分割的文件的结构,如Sequence File、RC File
总结:使用压缩,必然要支持split
- Compress Intermediate Data(从中间处理来考虑)
- Map output is written to disk(spill) and transferred accross the network
Map的输出,会写到磁盘上面去,然后通过网络进行传输 - Always use compression to reduce both disk write,and network transfer load
通常会采用压缩去减少磁盘的写、网络传输的负载 - Beneficial in performace point if view even if input and output is uncompressed
性能上是有帮助的,即使输入和输出没有使用压缩,在中间使用压缩,在性能上也是有提升的 - Use faster codecs such as Snappy,LZO
在这个阶段,使用速度更快的压缩方式,比如Snappy、LZO
- Compress Reducer Output(从输出层面来考虑)
- Mapreduce output used for both archiving or chaining mapreduce jobs
MapReduce的输出有两种场景:- 归档(当作历史)
- 作为其它MR作业的输入(两个MR配合起来使用)
- Use compression to reduce disk space for archiving
使用压缩在归档的时候减少磁盘空间 - Compression is also beneficial for chaining jobs especially with limited disk through put resource
在chain(操作链的情况下) 压缩通常情况在这种场景下是有用的 - Use compression methods with higher compress ratio to save more disk space
在这个阶段得使用的压缩方法是高的压缩比去节省更多的节省空间 比如BZIP2(压缩比最高)
**注意:**如果作业是作为另外一个作业的输入的话,是需要考虑压缩方式是否支持split的
压缩在MapReduce中的应用(实践)
Hadoop配置压缩:
core-site.xml:
io.compression.codecs
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec
mapred-site.xml(只配了最终的输出,中间输出的自己去配):
mapreduce.output.fileoutputformat.compress
true
mapreduce.output.fileoutputformat.compress.codec
org.apache.hadoop.io.compress.BZip2Codec
注意: 该配置文件是reduce的 如果是map会是mapreduce.map.output
测试:
$>hadoop jar hadoop-mapreduce-examples-2.6.0-cdh5.7.0.jar wordcount
/ruozeinput.txt /wc_compression_output
查看结果:
- 文件的后缀为.bz2
- 可以使用hadoop fs -text /xxx进行查看文件里的内容
压缩在Hive中的使用
不采用压缩
创建表,并导入数据:
hive>create table page_view(
track_time string,
url string,
session_id string,
referer string,
ip string,
end_user_id string,
city_id string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
hive>LOAD DATA LOCAL INPATH '/home/hadoop/data/page_views.dat' OVERWRITE INTO TABLE page_views;
查看HDFS上的数据:
$>hadoop fs -ls /user/hive/warehouse/page_views
$>hadoop fs -du -h /user/hive/warehouse/page_views
18.1M 18.1M
Bzip2测试
配置:
hive>set hive.exec.compress.output=true;
hive>set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.BZip2Codec;
创建表page_views_bzip2:
hive>create table page_views_bzip2
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
AS SELECT * FROM page_views;
查看HDFS上的数据:
$>hadoop fs -du -h /user/hive/warehouse/page_views_bzip2
3.6M 3.6M
GZIP测试
配置:
hive>set hive.exec.compress.output=true;
hive>set mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodec;
创建表page_views_gzip:
hive>create table page_views_gzip
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
AS SELECT * FROM page_views;
查看HDFS上的数据:
$>hadoop fs -du -h /user/hive/warehouse/page_views_bzip2
5.3M 5.3M