知识抽取(一)
这部分知识涉及到知识图谱重要环节,知识抽取和知识链接,会涉及到很多算法和抽取pipline。需要较强的背景知识,本文仅把思路和算法做了概括并没详细展开讲解,需要了解相关算法细节可以谷歌。
目录
知识抽取任务定义和相关比赛
知识抽取技术
• 实体抽取
序列标注方法(HMM、CRF、LSTM+CRF)
• 关系抽取
基于模板的方法
优点
监督学习方法
机器学习方法
轻量级特征
中等量级特征
重量级特征
深度学习方法
深度学习方法特征设计
Pipeline
Joint Model
弱监督学习方法
远程监督方法
Bootstrapping
• 事件抽取
事件抽取任务最基础的部分包括:
事件抽取的pipeline方法
Joint Modeling with Structured Prediction
基于深度学习的事件抽取方法
扩充语料的方法
从网络获取事件信息
命名实体识别
术语抽取
关系抽取
事件抽取
共指消解
比赛
Knowledge Base Population (KBP)
Semantic Evaluation(SemEval)
面向结构化数据的知识抽取
标准与工具
面向半结构化数据的知识抽取
百科类知识抽取
DBpedia
Zhishi.me
WEB网页数据抽取:包装器生成
手工法
自动抽取
WEB TABLE抽取简介
实践展示:基于百科数据的知识抽取
抽取框架
Knowledge Collection (BuddhistFigures)
Knowledge Fusion (Buddhist Figures)
Knowledge Completion (Buddhist Figures)
从不同来源、不同结构的数据中进行知识提取,形成知识存入到知识图谱。20世纪70年代后期出现在NLP领域,自动化地从文本中发现和抽取相关信息。从多个文本碎片中合并信息,通常应用在特定领域,将非结构化转化为结构化数据。
Schemas
Relations
Knowledge base
RDF triples
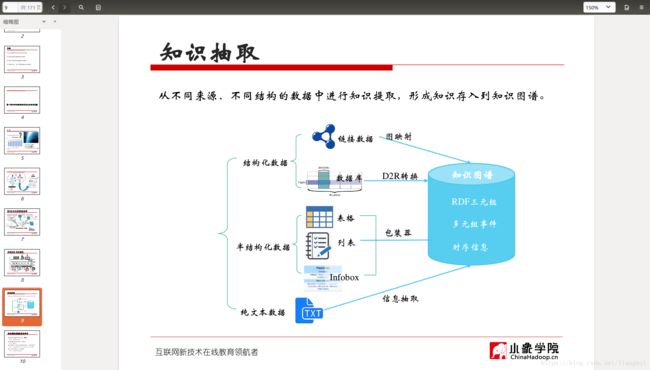
从结构化数据库中获取知识:D2R
难点:复杂表数据的处理
从链接数据中获取知识:图映射
难点:数据对齐
从半结构化(网站)数据中获取知识:使用包装器
难点:方便的包装器定义方法,包装器自动生成、更新与维护
从文本中获取知识:信息抽取
难点:结果的准确率与覆盖率
知识抽取任务定义和相关比赛
知识抽取技术

知识抽取的一个例子,如上图:
• 实体抽取
序列标注方法(HMM、CRF、LSTM+CRF)
人工特征
词本身的特征
-边界特征:边界词概率
-词性
-依存关系
互联网新技术在线教育领航者
前后缀特征
-姓氏:李XX、王X
-地名:XX省、XX市
字本身的特征
-是否是数字
-是否是字符
• 关系抽取
信息抽取 (Information Extraction)研究领域的任务之一
从文本中抽取出两个或者多个实体之间的语义关系
举例:
王健林谈儿子王思聪:我期望他稳重一点。
父子 (王健林, 王思聪)
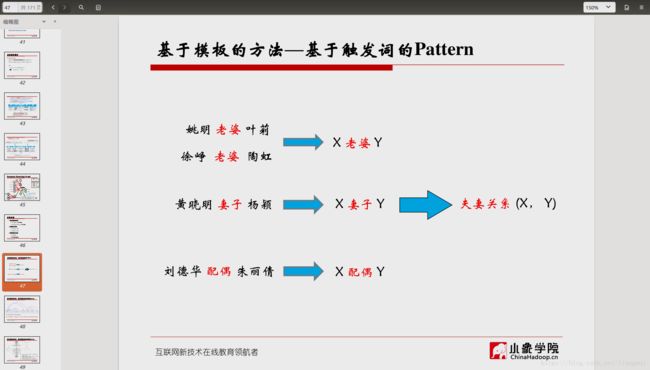
基于模板的方法
基于触发词的Pattern
基于依存句法分析的Pattern


优点
在小规模数据集上容易实现
构建简单
缺点
特定领域的模板需要专家构建
难以维护
可移植性差
规则集合小的时候,召回率很低
监督学习方法
确定实体对的情况下,根据句子上下文对实体关系进行预测,构建一个监督学习应该怎么做?
机器学习方法
预先定义好关系的类别
人工标注一些数据
设计特征表示
选择一个分类方法 (SVM、NN、Naive Bayes)
评估结果
轻量级特征
实体前后的词
实体的类型
实体之间的距离
中等量级特征
Chunk序列
重量级特征
实体间的依存关系路径
实体间树结构的距离
特定的结构信息
深度学习方法
深度学习方法特征设计
• Position embeddings
• Word embeddings
• Knowledge embeddings
Pipeline
• 识别实体和关系分类是完全分离的两个过程,不会相互影响,关系的识别依赖于实体识别的效果


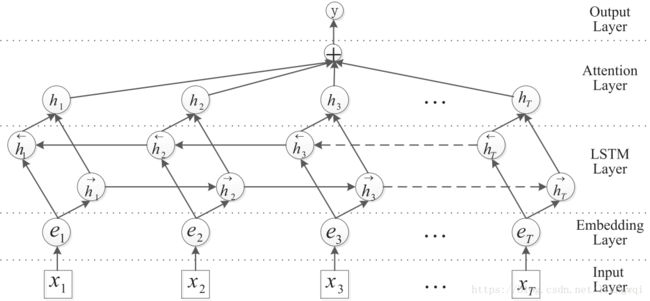
Joint Model
• 实体识别和关系分类的过程是共同优化的

优点
准确率高,标注数据越多越准确
缺点
标注数据成本太高
不能扩展新的关系
弱监督学习方法
没有足够多标注数据的情况下,怎么办?
数据量特别大的情况下,如何抽取实体间关系?
远程监督方法
知识库与非结构化文本对齐来自动构建大量训练数据,减少模型对人工标注数据的依赖,增强模型跨领域适应能力
Bootstrapping
通过在文本中匹配实体对和表达关系短语模式,寻找和发现新的潜在关系三元组
远程监督方法
两个实体如果在知识库中存在某种关系,则包含该两个实体的非结构化句子均能表示出这种关系。
在某知识库中存在: 创始人 (乔布斯, 苹果公司)则可构建训练正例:乔布斯是苹果公司的联合创始人和CEO
具体步骤
1. 从知识库中抽取存在关系的实体对
2. 从非结构化文本中抽取含有实体对的句子作为训练样例

优点
可以利用丰富的知识库信息,减少一定的人工标注
缺点
假设过于肯定,引入大量噪声,存在语义漂移现象
很难发现新的关系
Bootstrapping
给定种子集合,如:<姚明, 叶莉>
1. 从文档中抽取出包含种子实体的新闻,如
姚明 老婆 叶莉 简历身高曝光
X 老婆 Y 简历身高曝光
姚明 与妻子 叶莉 外出赴约
X 与妻子 Y 外出赴约
姚明 携爱妻 叶莉 外出赴约
X 携爱妻 Y 外出赴约
2. 将抽取出的Pattern去文档集中匹配
•
小猪 与妻子 伊万 外出赴约
3. 根据Pattern抽取出的新文档如种子库,迭代多轮直到不符合条件
优点
构建成本低,适合大规模构建
可以发现新的关系 (隐含的)
缺点
对初始给定的种子集敏感
存在语义漂移问题
结果准确率较低
缺乏对每一个结果的臵信度的计算
• 事件抽取
事件是指发生的事情,通常具有时间、地点、参与者等属性,事件的发生可能因为一个动作的产生或者系统状态的改变。
事件抽取的定义
从自然语言中抽取出用户感兴趣的事件信息,并以结构化的形式呈现出来,例如事件发生的时间、地点、发生原因、参与着等。
事件抽取的相关术语
事件描述 (Event Mention):描述事件的词组或句子
事件触发 (Event Trigger):表明事件出现的主要词汇
事件元素 (Event Argument):事件的重要信息
元素角色 (Argument Role):元素在句子中的语义角色
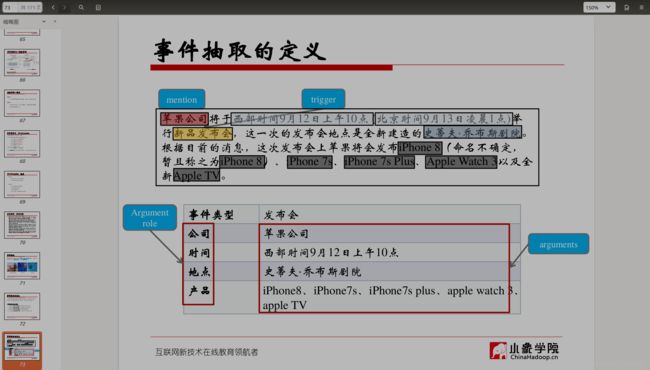
事件抽取任务最基础的部分包括:
识别事件触发词及事件类型
抽取事件元素同时判断其角色
抽出描述事件的词组或句子
此外,事件抽取任务还包括:
事件属性标注
事件共指消解
事件抽取的pipeline方法

有监督的事件抽取方法的标准流程一种pipeline的方法,将事件抽取任务转化为多阶段的分类问题,需要的分类器包括:
事件识别
事件触发次分类器 (Trigger Classifier)
• 用于判断词汇是否是是事件触发词,以及事件的类别
元素分类器 (Argument Classifier)
• 判别词组是否是事件的元素
元素抽取
元素角色分类器 (Role Classifier)
• 判定元素的角色类别
属性分类器 (attribute classifier)
属性分类
• 判定事件的属性
可报告性分类器 (Reportable-Event Classifier)
可报告性判别
• 判定是否存在值得报告的事件实例
分类器模型可以是机器学习方法中的各种分类器模型,比如MaxEnt、SVM等。


Joint Modeling with Structured Prediction
使用一个模型同时抽取出所有的信息的联合。
将问题建模成结构预测问题,使用搜索方法
进行求解。
避免了误差传播导致的性能下降。
全局特征可以从整体的结构中学习得到,从
而使用全局的信息来提升局部的预测。

基于深度学习的事件抽取方法
传统方法的缺陷:
需要借助外部的NLP工具
• 导致了误差的累积、传播
• 有些语言或者领域缺少NLP工具
需要人工设计特征
深度学习方法的优势:
减少了对外部NLP工具的依赖,甚至不依赖NLP工具,建模成端对端的系统。
使用词向量作为输入,词向量蕴含了丰富的语言特征。
神经网络具有自动提取句子特征的能力,避免了人工设计特征的繁琐工作。
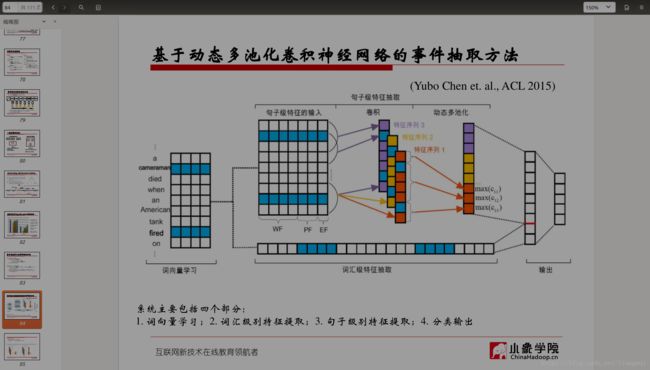

扩充语料的方法
使用FrameNet扩展语料 Shulin Liu, ACL 2016
FrameNet
• 语言学家定义及标注的语义框架资源
• 层级的组织结构
• 1000+ 框架、10000+ 词法单元、150000+ 标注例句
 运用结构化的知识库自动生成语料 Yubo Chen, ACL 2017
运用结构化的知识库自动生成语料 Yubo Chen, ACL 2017
• 利用世界知识和语言知识
• 自动生成大规模事件语料
从网络获取事件信息
• 从网络获取同一事件的不同报道
• 使用强化学习方法,做信息融合的决策

子任务
命名实体识别
检测: 库克非常兴奋。 [库克]:实体
分类: 库克非常兴奋。 [库克]:人物
术语抽取
从语料中发现多个单词组成的相关术语。
关系抽取
王思聪是万达集团董事长王健林的独子。
互联网新技术在线教育领航者
[王健林] <父子关系> [王思聪]
事件抽取
据路透社消息,英国当地时间9月15日早8时15分,位于伦敦西南地铁线
District Line的Parsons Green地铁站发生爆炸,目前已确定有多人受伤,具体
伤亡人数尚不明确。目前,英国警方已将此次爆炸与起火定性为恐怖袭击。
• 恐怖袭击事件
触发词: 发生爆炸
时间: 当地时间9月15日早8时15分
地点: Parsons Green地铁站
攻击者: -
伤亡人数: -
共指消解
[美国总统特朗普]否决了一家有中资背景的私募基金对美国莱迪思半导体公司
的收购案,[他]在多个专家小组的建议下做出该决定。
比赛
Knowledge Base Population (KBP)
KBP对ACE定义的任务进一步修订,适合现代知识抽取的需求
主要分为四个独立任务和一个整合任务 https://tac.nist.gov/2017/KBP/
实体发现与链接 (Entity Discovery and Linking, EDL)
• person (PER), organization (ORG), geopolitical entity (GPE), location
(LOC), and facility (FAC) entities mentioned in the documents, and to
link each mention to its KB node
槽填充 (Slot Filling, SF)
• to fill in values for specific attributes ("slots") for specific entities
• 姚明,1980年9月12日出生于上海市徐汇区,祖籍江苏省苏州市吴江
区震泽镇
事件抽取 (Event)
• Event Nugget (EN) to detect event nuggets (i.e., mentions of events in text),
and Event Argument (EAL) to extract event arguments and link arguments
that belong to the same event.
信念和情感 (Belief and Sentiment, BeSt)
• detects belief and sentiment of an entity toward another entity, relation, or
event
• 联合国安理会谴责埃及恐怖袭击事件
谴责(发起方:联合国安理会 承受方:埃及恐怖袭击事件)
端到端冷启动知识构建
• build a KB from scratch, using a predefined KB schema and a collection of
unstructured text
Semantic Evaluation(SemEval)
由ACL-SIGLEX组织的国际权威的词义消歧评测,目标是增进人们对词
义与多义现象的理解
https://en.wikipedia.org/wiki/SemEval
面向结构化数据的知识抽取
标准与工具
Mapping languages
Standards by RDB2RDF working group (W3C)
Direct Mapping
R2RML
Proprietary
Tools
Free: D2R, Virtuoso, Morph, r2rml4net,
db2triples, ultrawrap, Quest
Commercial: Virtuoso, ultrawrap, Oracle SW
面向半结构化数据的知识抽取
百科类知识抽取
DBpedia
大规模多语言百科知识图谱,维基百科的结构化版本,linked data核心数据集
覆盖127种语言,两千八百万个实体,数亿三元组,支持数据集的完全下载
固定模式对实体信息进行抽取,包括abstract, infobox,category, page link等
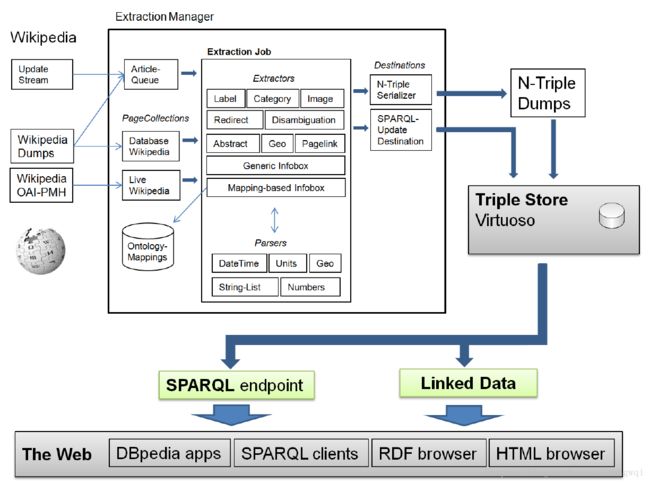 Generic Infobox Extraction
Generic Infobox Extraction
同义属性名不做映射,保持Wikipedia中原有内容,如:birthdate与dateOfBirth.
Mapping-based Infobox Extraction
定义dbpedia ontology,将属性做好对齐(二次处理, 人工定义规则),目前共有2795 properties.
Zhishi.me

1) 第一份中文大规模开放链接数据 (Chinese Linking Open Data);
2) 1000万实体,2亿三元组,提供关键字查询服务,API调用,SPARQL Endpoint

WEB网页数据抽取:包装器生成
互联网中的网页含有丰富的数据。例如电商网站中的商品数据,黄页网站中的公司数据等等。我们获取网页中的数据经过加工后便可以丰富我们的知识图谱。
手工法
手工方法需要查看网页结构和代码,通过人工分析,手工写出适合这个网站的表达式,这个表达式的形式可以是XPath表达式,也可以是CSS选择器的表达式等。
何为XPath?
XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位臵的语言。借助它可以获取网页中元素的位臵,从而获取需要的信息。分析上页搜索结果页面,价格信息的XPath为:
//*[@id="J_goodsList"]/ul/*/div/div[3]/strong
• 何为CSS选择器表达式?
通过CSS元素实现对网页中元素的定位,获取元素的信息。分析上页搜索结果页面,价格信息的CSS选择器表达式为:
#J_goodsList > ul > li:nth-child(1) > div > div.p-price > strong
包装器定义:
包装器是一个能够将数据从HTML网页中抽取出来,并且将它们还原为结构化的数据的软件程序。
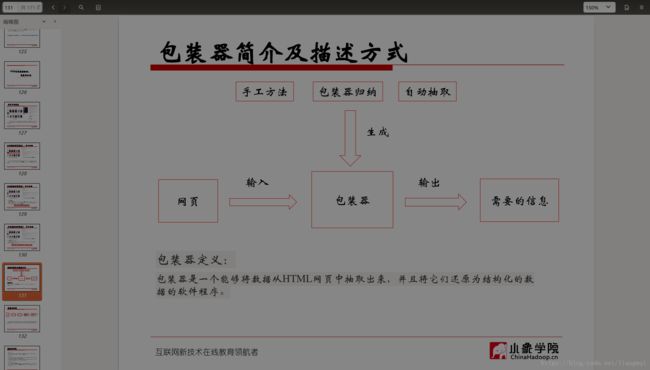
包装器归纳是基于有监督学习的,他从标注好的训练样例集合中学习数据抽取规则,用于从其他用相同标记或相同网页模板抽取目标数据。

• 网页清洗
有些网页结构不规范,例如前后标签不对成,没有结束标签符。不规范的网页结构容易在抽取的过程中产生噪声。清洗可以用Tidy来完成。
• 网页标注
网页标注是在网页上标注你需要抽取数据的过程。标注的过程可以是给网页中的某个位臵打上特殊的标签表明这是需要抽取的数据。
例如我们要抽取上面举例的“华为P10”搜索页面的商品信息和价格信息,就可以在通过在他们所在的标签里打上一个特殊的标记作为标注。
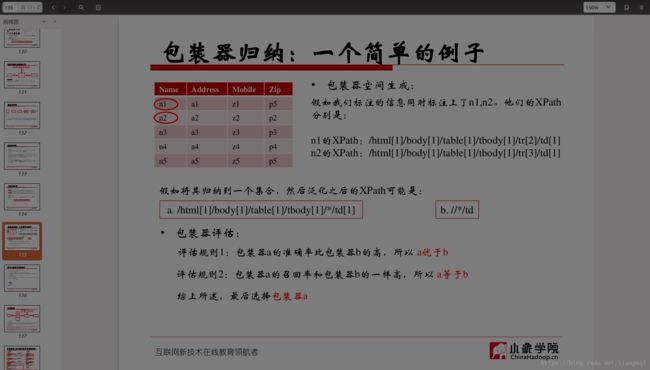
• 包装器空间的生成
对标注的数据生成XPath集合空间,对生成的集合进行归纳,形成若干个子集。归纳的规则是在子集中的XPath能够覆盖多个标注的数据项,具有一定的泛化能力。
• 包装器评估
评估规则一:准确率。将筛选出来的包装器对原先训练的网页进行标注,统计与人工标注的相同项的数量,除以当前标注的总数量。准确率越高评分越高。
评估规则二:召回率。将筛选出来的包装器对原先训练的网页进行标注,统计与人工标注的相同项的数量,除以人工标注的总数量。召回率越高评分越高。
• 包装器归纳结果
经过前面一系列的工作之后,“华为P10”搜索结果页面最后价格信息的XPath的路径为:
//*[@id="J_goodsList"]/ul/*/div/div[3]/strong
自动抽取
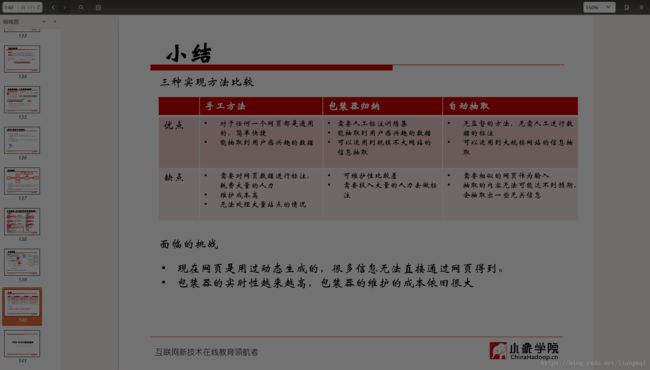
• 有监督学习包装器有缺陷
1. 由于需要手工标注的工作,它不适合对大量站点的抽取。
2. 包装器维护的开销会很大。例如网站改变了其已有的模板,之前生成的包装器将会无效。
• 自动抽取是可行的
网站中的数据通常是用很少的一些模板来编码的,通过挖掘多个数据记录中的重复模式来寻找这些模板是可能的。
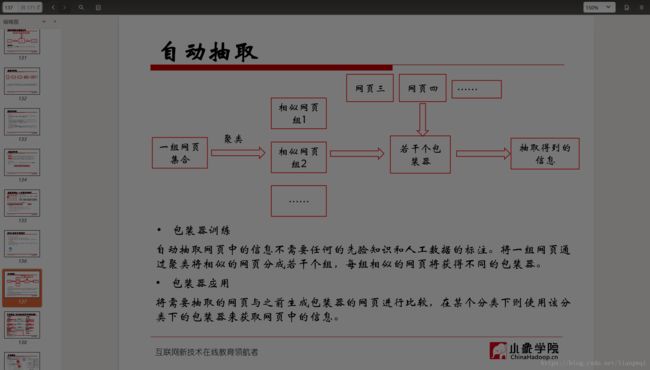
• 包装器训练
自动抽取网页中的信息不需要任何的先验知识和人工数据的标注。将一组网页通过聚类将相似的网页分成若干个组,每组相似的网页将获得不同的包装器。
• 包装器应用
将需要抽取的网页与之前生成包装器的网页进行比较,在某个分类下则使用该分类下的包装器来获取网页中的信息。
WEB TABLE抽取简介
为了解释Web table中隐含的语义,一些工作将其中的内容标注为RDF三元组。这种标注的第一步就是实体链接 (entity linking ), 即将表格中各单元格的字符串映射到给定知识库的实体上。
1) 候选生成.
针对表格单元格中的每个字符串,从给定的知识库中识别候选实体。
( token 匹配 ( 字符串匹配 , 同义词匹配 ,...…)
2) 实体消岐.
从给定字符串所对应的实体集中选择唯一的一个实体作为链接实体。
位于相同行或者列的字符串可能相关,换句话说,出现在同一表格中的任意两个字符串都存在某种潜在的
关联。使用图算法对给定表格中的所有字符串进行联合消岐。

对每张给定的表格建立一个实体消岐图
每个图由如下的元素构成:
字符串节点, 实体节点
字符串-实体 边: 字符串与候选实体间的无向边,
实体-实体 边: 实体间的无向边

两类实体链接影响因子:
1) 每个字符串的初始重要性(importance of each mention);
2) 不同节点间的语义相关度(semantic relatedness between different nodes).
实体消岐算法—PageRank.
PageRank算法 (Iterative probability propagation) 用来整合不同的实体
链接影响因子从而做出最终的实体链接决定.

实践展示:基于百科数据的知识抽取
在线百科知识抽取技术应用—佛学知识图谱构建。
抽取框架
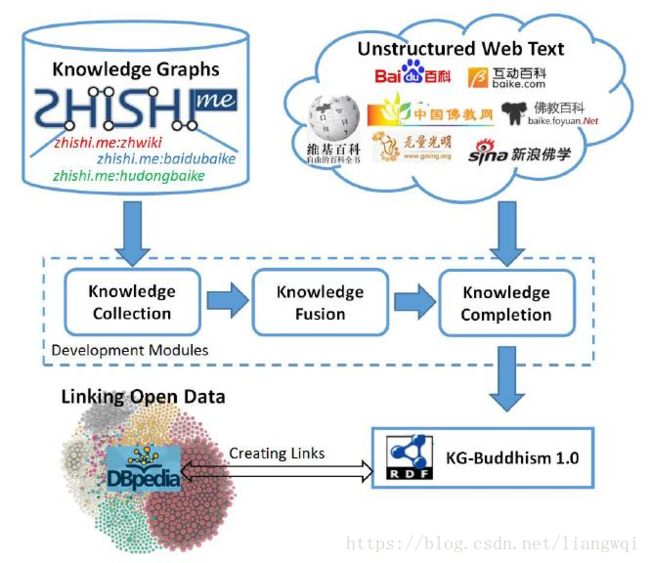 Knowledge Collection (BuddhistFigures)
Knowledge Collection (BuddhistFigures)
Category方法
– 人工观察百科中与佛教人物相关的分类
– 抽取佛教人物分类下所有文章对应的实体
•
命名规则方法
例: ―.+菩萨‖
―.+禅师‖
– 维基百科―佛教头衔‖分类下的所有实体
– 已抽取出的实体名中高频的公共字符串
 Knowledge Fusion (Buddhist Figures)
Knowledge Fusion (Buddhist Figures)
主语融合
实体的―别名‖属性和重定向作为实体的别名集合
不同来源的实体存在一个完全匹配的别名则认为是相同实体
人工检查相同实体数多于三个的映射
 主语融合 (寺庙知识图谱中的应用)
主语融合 (寺庙知识图谱中的应用)
问题
–同名不同实体
: {龙泉寺、北京龙泉寺}
–同实体不同名
{龙泉寺_(海淀区)、海淀区龙泉寺}
• 谓语融合
– Infobox属性
保留选定的15个佛学人物子属性与9个佛学寺庙子属性,人工总结每个属性在现有知识图谱中存在的谓语形式
– 其它属性
直接替换谓语的命名空间
宾语融合
单值属性
精确性原则:日期、地点等类型的属性值出现冲突时选择最精确的一个。
大多数原则:不同来源的属性值出现冲突时,选择出现次数最多的值。
多值属性
直接合并去重
Knowledge Completion (Buddhist Figures)
对infobox属性进行补全
人工编写规则从非结构化文本中抽取属性值
依照知识融合方法将属性值对转换为三元组
