知识图谱存储
目录
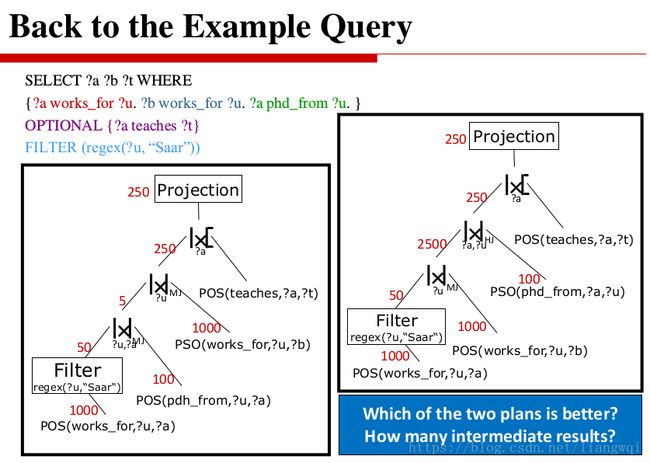
从一个例子开始
数据来源
数据描述
数据导入
数据查询
数据更新
图数据库介绍
图数据库分类
开源数据库介绍:RDF4j 、gStore等
商业数据库介绍:Virtuoso、AllegroGraph、Stardog等
Virtuoso
Allgrograph
Stardog
原生图数据库介绍:Neo4j、OrientDB、Titan等
Neo4j
OrientDB
Titan
Benchmark
数据库实现细节
Which indexes should be built?
Indexes for Commonly Used Triple Patterns
How can we reduce storage space?
Compression Effectiveness vs. Efficiency
Handling Updates
What should we do when our data changes?
Principles
Observations and assumptions:
从一个例子开始
数据来源
数据描述
数据导入
数据查询
数据更新
图数据库介绍
图数据库分类
开源数据库介绍:RDF4j 、gStore等
商业数据库介绍:Virtuoso、AllegroGraph、Stardog等
Virtuoso
Allgrograph
Stardog
原生图数据库介绍:Neo4j、OrientDB、Titan等
Neo4j
OrientDB
Titan
Benchmark
数据库实现细节
Which indexes should be built?
Indexes for Commonly Used Triple Patterns
How can we reduce storage space?
Compression Effectiveness vs. Efficiency
Handling Updates
What should we do when our data changes?
Principles
Observations and assumptions:
Property Tables: Pros and Cons
Even More Systems...
Property Tables: Pros and Cons
Even More Systems...
How can we find the best execution plan?
从一个例子开始
数据来源
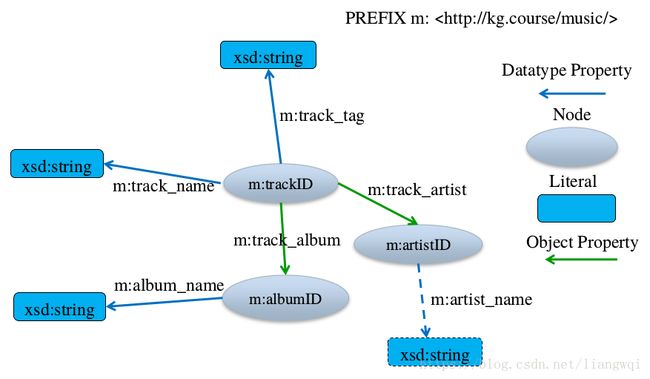
数据描述

数据导入
图谱存储工具 – 图数据库
图数据库
图数据库源起欧拉和图理论 (graph theory),也可称为面向/基于图的数据库,对应的英文是Graph Database。图数据库的基本含义是以“图”这种数据结构存储和查询数据。它的数据模型主要是以节点和关系 (边)来体现,也可处理键值对。它的优点是快速解决复杂的关系问题。
图具有如下特征:
1.包含节点和边
2.节点上有属性 (键值对)
3.边有名字和方向,并总是有一个开始节点和一个结束节点
4.边也可以有属性
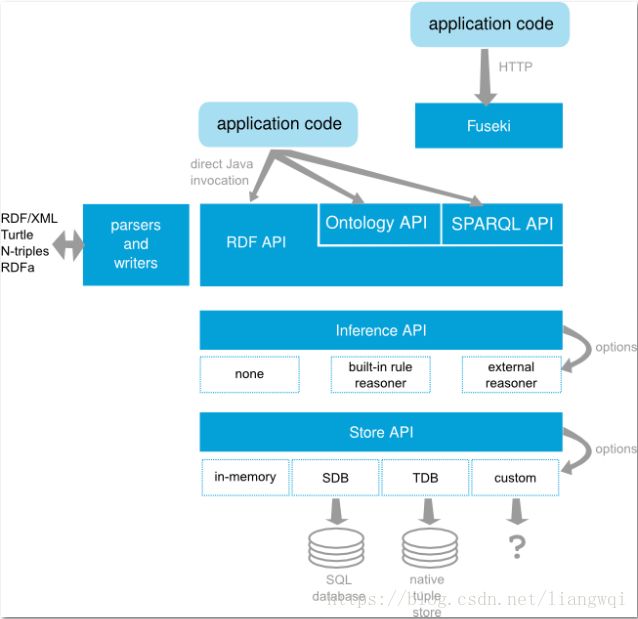
开源数据库 – Apache Jena
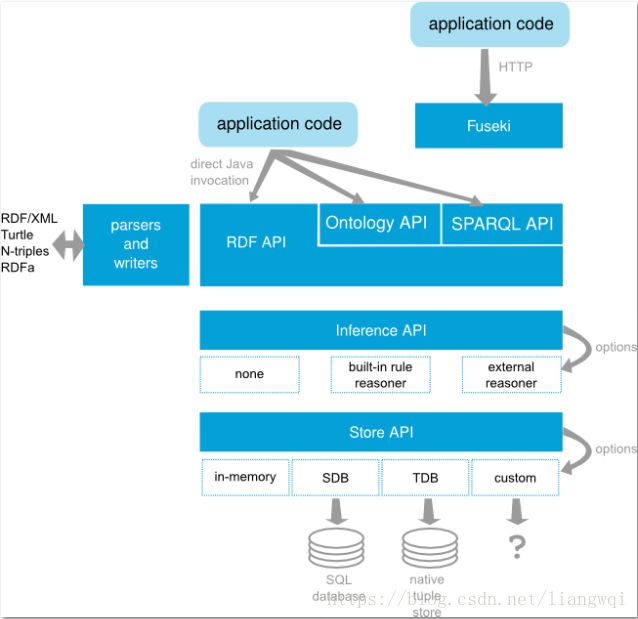
数据导入方法:
1.Fuseki 手动导入 (稍后演示)
2.使用TDB导入
使用TDB导入的命令如下
/jena-fuseki/tdbloader --loc=/jena-fuseki/data filename Fuseki启动的命令如下,需要指定tdb生成的文件路径并指定数据库名/jena-fuseki/fuseki-server –loc=/jena-fuseki/data --update /music
数据查询
1.Fuseki 界面查询 (稍后演示)
2.使用endpoint接口查询
Endpoint地址:
SPARQL Query: http://localhost:3030/music/query
SPARQL Update: http://localhost:3030/music/update
数据更新
 点击 manage datasets
点击 manage datasets
点击 add one 增加一个数据库
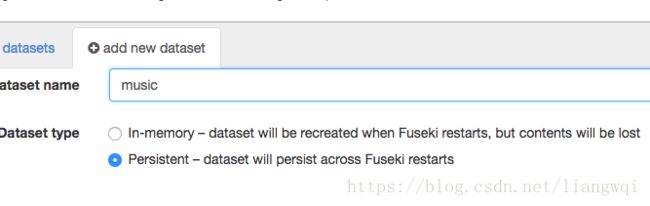 输入dataset name为: music
输入dataset name为: music
选择 Persistent
点击 create dataset 完成数据库的创建

 点击最右的upload data会出现导入数据的界面
点击最右的upload data会出现导入数据的界面
图数据库介绍
图数据库分类
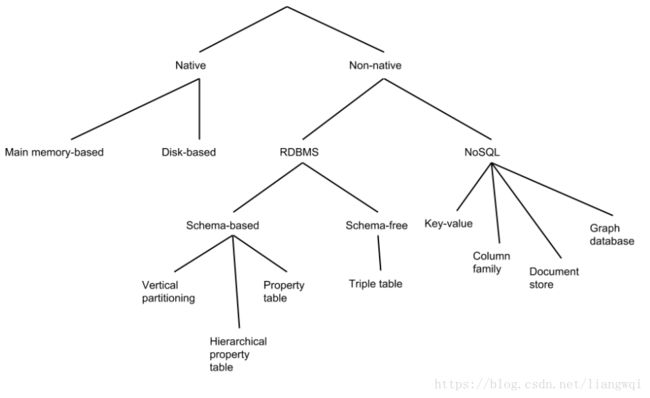
开源数据库介绍:RDF4j 、gStore等
处理RDF数据的Java框架
使用简单可用的API来实现RDF存储
支持SPARQL endpoints
支持两种RDF存储机制
支持所有主流的RDF文件格式
 gStore
gStore
gStore从图数据库角度存储和检索RDF知识图谱数据;
gStore支持W3C定义的SPARQL 1.1标准,包括含有Union,
OPTIONAL,FILTER和聚集函数的查询;gStore支持有效的增删改操作
gStore单机可以支持1Billion(十亿)三元组规模的RDF知识图谱的数据管理任务。
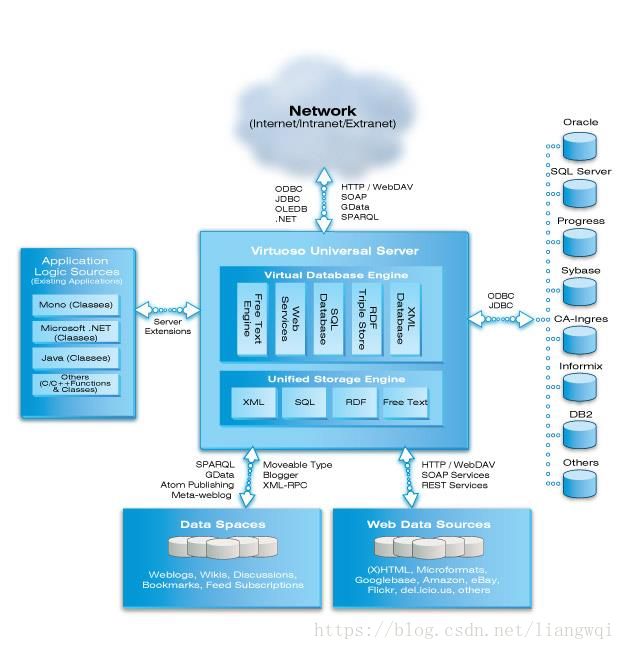
商业数据库介绍:Virtuoso、AllegroGraph、Stardog等
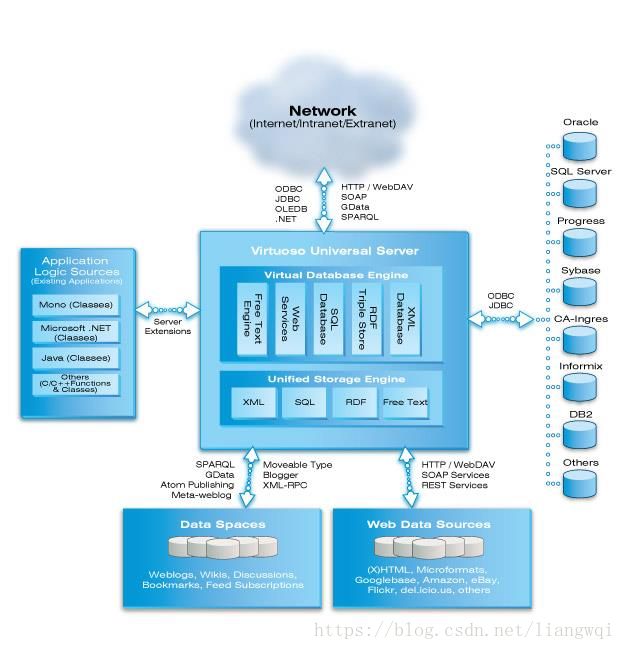
Virtuoso
智能数据,可视化与整合
可扩展和高性能的数据管理
支持Web 扩展和安全
 Allgrograph
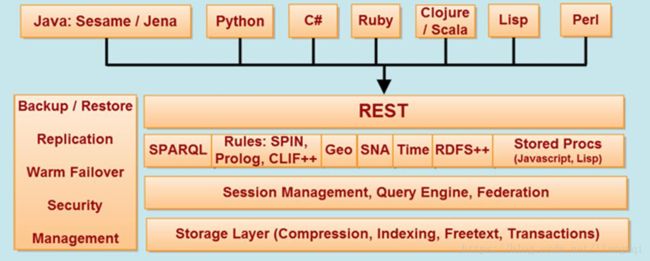
Allgrograph
一个现代的,高性能的,支持永久存储的图数据库
基于Restful接入支持多语言编程
Stardog

原生图数据库介绍:Neo4j、OrientDB、Titan等
Neo4j
图数据库+Lucene索引
支持属性图
支持ACID
高可用性
支持320亿的结点,320亿的关系结点,640亿的属性
REST API接口
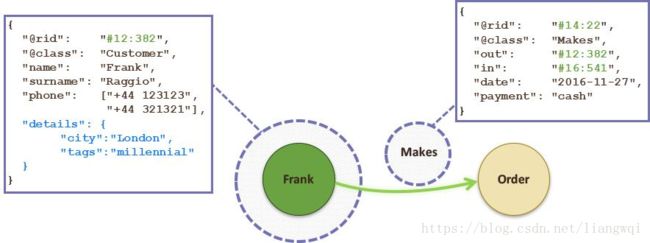
在一个图中包含两种基本的数据类型:Nodes (节点) 和Relationships (关系)。
Nodes 和 Relationships 包含key/value形式的属性。Nodes通过Relationships所定义的关系相连起来,形成关系型网络结构。
优点
高连通数据
推荐
路径查找
A*算法
数据优先
OrientDB
OrientDB是一个用Java实现的开源NoSQL数据库管理系统。它是一个多模式的数据
库,支持图形、文档、键值对、对象模型和关系,也可以为图数据库的管理与记录之间的提供连接
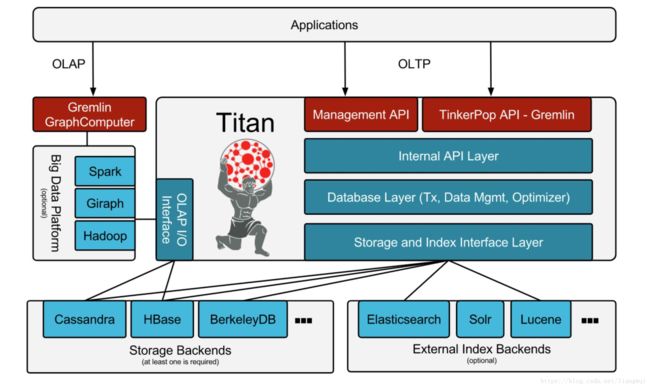
 Titan
Titan
• 弹性和线性增长的数据和用户的可扩展性
• 数据分布和复制性能和容错性
• 支持增删改查,支持一致性
• 支持各种后端存储
• 支持全局图数据分析,报告,并通过ETL连接大数据平台
• 支持全文检索
Benchmark
常用衡量指标
Load Time
Repository Size
Query Response Time
Throughputs
 Inference Support
Inference Support
数据库实现细节
Conversion of SPARQL to SQL
General approach to translate SPARQL into SQL:
(1) Each triple pattern is translated into a (self-) JOIN over the triple table
(2) Shared variables create JOIN conditions
(3) Constants create WHERE conditions
(4) FILTER conditions create WHERE conditions
(5) OPTIONAL clauses create OUTER JOINS
(6) UNION clauses create UNION expressions
 Which indexes should be built?
Which indexes should be built?
(to support efficient evaluation of triple patterns)
Existing databases need modifications:
• flexible, extensible, generic storage not needed here
• cannot deal with multiple self-joins of a single table
• often generate bad execution plans
Indexes for Commonly Used Triple Patterns
Patterns with a single variable are frequent
Example: Albert_Einstein invented ?x
Build clustered index over (s,p,o)
 Can also be used for pattern like Albert_Einstein ?p ?x
Can also be used for pattern like Albert_Einstein ?p ?x
Build similar clustered indexes for all six permutations (3 x 2 x 1 = 6)
SPO, POS, OSP to cover all possible triplet patterns
SOP, OPS, PSO to have all sort orders for patterns with two var’s
Triple table no longer needed, all triples in each index
 RDF-3x: Compression Scheme for Triplets
RDF-3x: Compression Scheme for Triplets
Compress sequences of triples in lexicographic order
(v1;v2;v3); for SPO: v1=S, v2=P, v3=O
Step 1: compute per-attribute deltas

How can we reduce storage space?
Compression Effectiveness vs. Efficiency
Byte-level encoding almost as effective as bit-level encoding techniques (Gamma, Golomb, Rice, etc.)
Much faster (10x) for decompressing
Example for Barton dataset [Neumann & Weikum: VLDB’10]:
Raw data 51 million triples, 7GB uncompressed (as N-Triples)
All 6 main indexes:
1.1GB size, 3.2s decompression with byte-level encoding
Optionally: additional compression with LZ77 2x more compact, but much slower to decompress
Compression always on page level
 RDF-3x: Selectivity Estimation
RDF-3x: Selectivity Estimation
How many results will a triple pattern have?
Standard databases:
Per-attribute histograms
Assume independence of attributes
too simplistic and inexact
Use aggregated indexes for exact count
Additional join statistics for triple blocks (pages):

Handling Updates
What should we do when our data changes?
(SPARQL 1.1 has updates!)
Assumptions:
Queries far more frequent than updates
Updates mostly insertions, hardly any deletions
Different applications may update concurrently
Solution: Differential Indexing
 Principles
Principles
Observations and assumptions:
Not too many different predicates
Triple patterns usually have fixed predicate
Need to access all triples with one predicate
Design consequence:
• Use one two-attribute table for each predicate

从一个例子开始
数据来源

数据描述

数据导入
图谱存储工具 – 图数据库
图数据库
图数据库源起欧拉和图理论 (graph theory),也可称为面向/基于图的数据库,对应的英文是Graph Database。图数据库的基本含义是以“图”这种数据结构存储和查询数据。它的数据模型主要是以节点和关系 (边)来体现,也可处理键值对。它的优点是快速解决复杂的关系问题。
图具有如下特征:
1.包含节点和边
2.节点上有属性 (键值对)
3.边有名字和方向,并总是有一个开始节点和一个结束节点
4.边也可以有属性
开源数据库 – Apache Jena
数据导入方法:
1.Fuseki 手动导入 (稍后演示)
2.使用TDB导入
使用TDB导入的命令如下
/jena-fuseki/tdbloader --loc=/jena-fuseki/data filename Fuseki启动的命令如下,需要指定tdb生成的文件路径并指定数据库名/jena-fuseki/fuseki-server –loc=/jena-fuseki/data --update /music
数据查询
1.Fuseki 界面查询 (稍后演示)
2.使用endpoint接口查询
Endpoint地址:
SPARQL Query: http://localhost:3030/music/query
SPARQL Update: http://localhost:3030/music/update
数据更新
 点击 manage datasets
点击 manage datasets
点击 add one 增加一个数据库
 输入dataset name为: music
输入dataset name为: music
选择 Persistent
点击 create dataset 完成数据库的创建

 点击最右的upload data会出现导入数据的界面
点击最右的upload data会出现导入数据的界面
图数据库介绍
图数据库分类
开源数据库介绍:RDF4j 、gStore等
处理RDF数据的Java框架
使用简单可用的API来实现RDF存储
支持SPARQL endpoints
支持两种RDF存储机制
支持所有主流的RDF文件格式
 gStore
gStore
gStore从图数据库角度存储和检索RDF知识图谱数据;
gStore支持W3C定义的SPARQL 1.1标准,包括含有Union,
OPTIONAL,FILTER和聚集函数的查询;gStore支持有效的增删改操作
gStore单机可以支持1Billion(十亿)三元组规模的RDF知识图谱的数据管理任务。
商业数据库介绍:Virtuoso、AllegroGraph、Stardog等
Virtuoso
智能数据,可视化与整合
可扩展和高性能的数据管理
支持Web 扩展和安全
 Allgrograph
Allgrograph
一个现代的,高性能的,支持永久存储的图数据库
基于Restful接入支持多语言编程

Stardog

原生图数据库介绍:Neo4j、OrientDB、Titan等
Neo4j
图数据库+Lucene索引
支持属性图
支持ACID
高可用性
支持320亿的结点,320亿的关系结点,640亿的属性
REST API接口
在一个图中包含两种基本的数据类型:Nodes (节点) 和Relationships (关系)。
Nodes 和 Relationships 包含key/value形式的属性。Nodes通过Relationships所定义的关系相连起来,形成关系型网络结构。
优点
高连通数据
推荐
路径查找
A*算法
数据优先
OrientDB
OrientDB是一个用Java实现的开源NoSQL数据库管理系统。它是一个多模式的数据
库,支持图形、文档、键值对、对象模型和关系,也可以为图数据库的管理与记录之间的提供连接
 Titan
Titan
• 弹性和线性增长的数据和用户的可扩展性
• 数据分布和复制性能和容错性
• 支持增删改查,支持一致性
• 支持各种后端存储
• 支持全局图数据分析,报告,并通过ETL连接大数据平台
• 支持全文检索

Benchmark
常用衡量指标
Load Time
Repository Size
Query Response Time
Throughputs
 Inference Support
Inference Support
数据库实现细节
Conversion of SPARQL to SQL
General approach to translate SPARQL into SQL:
(1) Each triple pattern is translated into a (self-) JOIN over the triple table
(2) Shared variables create JOIN conditions
(3) Constants create WHERE conditions
(4) FILTER conditions create WHERE conditions
(5) OPTIONAL clauses create OUTER JOINS
(6) UNION clauses create UNION expressions
 Which indexes should be built?
Which indexes should be built?
(to support efficient evaluation of triple patterns)
Existing databases need modifications:
• flexible, extensible, generic storage not needed here
• cannot deal with multiple self-joins of a single table
• often generate bad execution plans
Indexes for Commonly Used Triple Patterns
Patterns with a single variable are frequent
Example: Albert_Einstein invented ?x
Build clustered index over (s,p,o)
 Can also be used for pattern like Albert_Einstein ?p ?x
Can also be used for pattern like Albert_Einstein ?p ?x
Build similar clustered indexes for all six permutations (3 x 2 x 1 = 6)
SPO, POS, OSP to cover all possible triplet patterns
SOP, OPS, PSO to have all sort orders for patterns with two var’s
Triple table no longer needed, all triples in each index
 RDF-3x: Compression Scheme for Triplets
RDF-3x: Compression Scheme for Triplets
Compress sequences of triples in lexicographic order
(v1;v2;v3); for SPO: v1=S, v2=P, v3=O
Step 1: compute per-attribute deltas

How can we reduce storage space?
Compression Effectiveness vs. Efficiency
Byte-level encoding almost as effective as bit-level encoding techniques (Gamma, Golomb, Rice, etc.)
Much faster (10x) for decompressing
Example for Barton dataset [Neumann & Weikum: VLDB’10]:
Raw data 51 million triples, 7GB uncompressed (as N-Triples)
All 6 main indexes:
1.1GB size, 3.2s decompression with byte-level encoding
Optionally: additional compression with LZ77 2x more compact, but much slower to decompress
Compression always on page level
 RDF-3x: Selectivity Estimation
RDF-3x: Selectivity Estimation
How many results will a triple pattern have?
Standard databases:
Per-attribute histograms
Assume independence of attributes
too simplistic and inexact
Use aggregated indexes for exact count
Additional join statistics for triple blocks (pages):

Handling Updates
What should we do when our data changes?
(SPARQL 1.1 has updates!)
Assumptions:
Queries far more frequent than updates
Updates mostly insertions, hardly any deletions
Different applications may update concurrently
Solution: Differential Indexing
 Principles
Principles
Observations and assumptions:
Not too many different predicates
Triple patterns usually have fixed predicate
Need to access all triples with one predicate
Design consequence:
• Use one two-attribute table for each predicate

 Property Tables: Pros and Cons
Property Tables: Pros and Cons
Advantages:
More in the spirit of existing relational systems
Saves many self-joins over triple tables etc.
Disadvantages:
Potentially many NULL values
Multi-value attributes problematic
Query mapping depends on schema
Schema changes very expensive
Even More Systems...
Store RDF data as sparse matrix with bit-vector
compression [BitMat, Hendler at al.: ISWC’09]
Convert RDF into XML and use XML methods
(XPath, XQuery, ...)
Store RDF data in graph databases and perform
Property Tables: Pros and Cons
Advantages:
More in the spirit of existing relational systems
Saves many self-joins over triple tables etc.
Disadvantages:
Potentially many NULL values
Multi-value attributes problematic
Query mapping depends on schema
Schema changes very expensive
Even More Systems...
Store RDF data as sparse matrix with bit-vector
compression [BitMat, Hendler at al.: ISWC’09]
Convert RDF into XML and use XML methods
(XPath, XQuery, ...)
Store RDF data in graph databases and perform
bi-simulation [Fletcher at al.: ESWC’12] or employ
specialized graph index structures [gStore, Zou et al.:
PVLDB’11]
And many more …
How can we find the best execution plan?
SPARQL with different entailment regimes
New SPARQL 1.1 features
(grouping, aggregation, updates)
User-oriented ranking of query results
Efficient top-k operators
Effective scoring methods for structured queries
What are the limits of a centralized RDF engine?
Dealing with uncertain RDF data –what is the most likely query answer?
Triples with probabilities probabilistic database