双向LSTM NLP序列标志读书笔记
Bidirectional LSTM-CRF Models for Sequence Tagging
原论文下载地址:https://arxiv.org/pdf/1508.01991v1
论文摘要
本文百度出品。使用双向LSTM+CRFs 模型用于NLP序列标注问题(POS、分块、命名实体识别)。作者认为应该是这个模型首次用于该研究领域。模型两个优点,精度高和对词向量的依赖性小 (In addition, it is robust and has less dependence on word embedding as compared to previous observations)
研究背景
序列标注是基础性的NLP研究课题,是许多NLP任务的基础。比如搜索引擎使用命名实体识别查询语句中的产品类实体,继而推荐广告。经典的序列标注有HMM、MEMMs和CRFs(Lafferty et al., 2001)三种,其中CRFs的效果最好,可以解决HMM和MEMMs的标签偏置(label bias)问题。后来词向量的研究兴起,Collobert(Collobert et al.201) 的C&W词向量也在序列标注一展身手。Collobert 用的是卷积神经网络+CRF。LSTM在语音识别等领域已经有了成功的应用,引文若干。作者在之后的实验中对比了这些模型和自己模型(BI-LSTM-CRF, state of the art)的结果。
模型介绍
LSTM
可以参考一下博客,如果浏览器加载不出图片,请换一个Chrome或者Edge浏览器
http://blog.csdn.net/Dark_Scope/article/details/47056361
双向LSTM
http://blog.csdn.net/jojozhangju/article/details/51982254
A. Graves and J. Schmidhuber. 2005. FramewisePhonemeClassificationwithBidirectional LSTM and Other Neural Network Architectures. Neural Networks
CRF networks
线性CRF 和逻辑回归在数学上是一致的。训练集中的每个句子中的每一个词,有一个标注。对句子的第i个位置的词抽取高维特征(包括上一个词的标注id,前后ngram特征),通过学习特征到标注的映射,可以得到特征到任意标注的概率(归一化),测试的时候,从句子的开头开始,抽取特征,预测标注概率,标注带入下一个特征,预测新一轮标注的概率,使用Viterbi Algorithm记录所有最优路径(当前对每个可能标注记录概率最大的上一个标注来源,直到句子边界)。CRF的求解可以用梯度下降,前向后向算法等。可以参考李航老师的《统计学习方法》。
LSTM-CRF networks
论文指出 A CRF layer has a state transition matrix as parameters. With such a layer, we can efficiently use past and future tags to predict the current tag. 其实CRF训练时采用的是前一个的标注作为当前标注的有效特征(以训练标签和标签之间的转移矩阵),解码时才能用未来的标注改变最优路径的选择(另外解码的时候,不需要之前的标签作为特征,认为每次预测都是单独的事件,算出单独的分数(概率的log值,这样可以忽略算概率时的归一化分母,叠加分数就可以选择的到最优路径))。
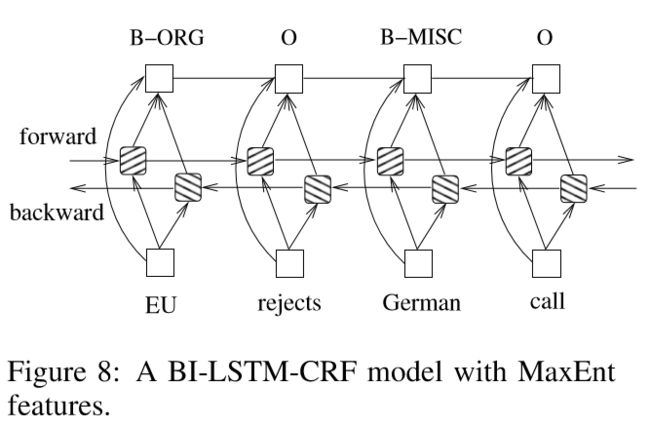
文本特征
使用了拼写特征、NGram特征还有词向量特征
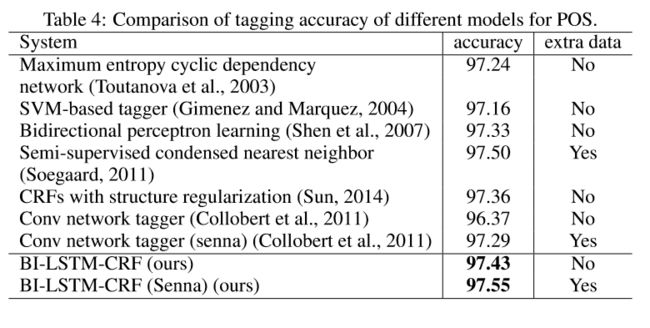
结果对比
本文用了三个数据集 Penn Treebank (POS),CoNLL2000 (分块),CoNLL2003(命名实体识别)
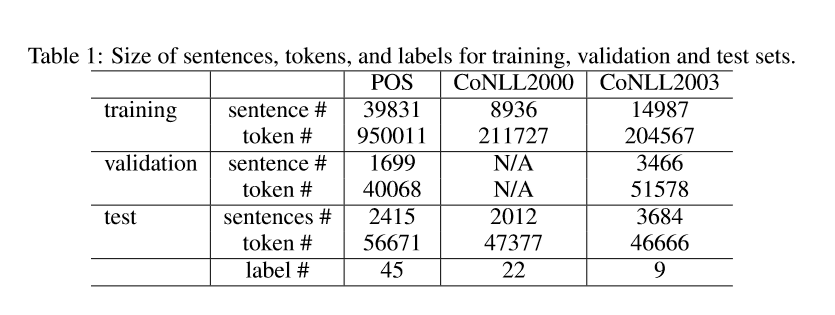
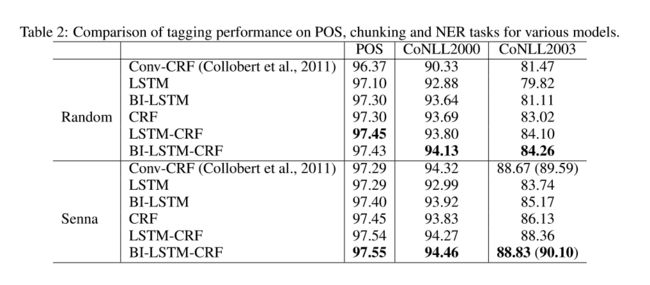
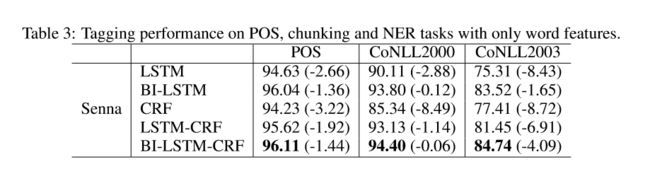


J. Lafferty, A. McCallum, and F. Pereira. 2001. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. Proceedings of ICML.
R. Collobert, J. Weston, L. Bottou, M. Karlen, K. Kavukcuoglu and P. Kuksa. 2011. Natural Language Processing (Almost) from Scratch. Journal of Machine Learning Research (JMLR).
K. S. Yao, B. Peng, Y. Zhang, D. Yu, G. Zweig, and Y. Shi. 2014. Spoken Language Understanding using Long Short-Term Memory Neural Networks. IEEE SLT
K.S.Yao,B.L.Peng,G.Zweig,D.Yu, X. L. Li, and F. Gao. 2014. Recurrent conditional random fields for language understanding