【配置】vs13+opencv2.4.9+cuda6.5+64位win7编译配置
2017/12/12–2017/12/14
记录过程
最近需要计算光流,试了几种方法,想看一下哪种算法的效果比较好,然后想用到brox光流法,opencv中已经包含这个算法,但是,需要用到GPU!!!所以以前编译的opencv已经不能弄了,需要重新编译一个支持GPU的版本。
- 首先记录一下编译过程,并注明过程中出现哪些错误
- 然后注明测试过程出现的错误,以及可能会解决的方法
- 最后是其他一些错误
参考链接:http://blog.csdn.net/zxj820/article/details/50821036
感谢
一、准备
首先注意一点,在整个过程中最好不要出现中文路径。
1、安装cmake
2、安装cuda6.5
3、下载opencv2.4.9源文件
4、安装vs2013
5、安装intel tbb库
6、python2.7(可选)
以上安装包在参考链接中都有给出。
二、配置
1、解压opencv2.4.9
2、解压tbb,并添加路径到系统环境变量path中。
即右击计算机–属性–高级系统设置–环境变量–用户变量–path
添加一下路径(即你的tbb的路径),每个路径之间用英文分号隔开。
D:\tbb43_20150424oss\bin\intel64\vc12;
D:\tbb43_20150424oss\include;
D:\tbb43_20150424oss\lib\intel64
3、配置cmake
3.1 打开cmake,添加一下内容:
where is the source code:你的opencv中source文件路径,如:D:\opencv\sources
where to build the binaries:一个新路径,用来存放你编译生成的文件,如:D:\opencv\newmake
勾选Advanced

3.2 点 Configure,选择编译器,选择 ‘Visual Studio 12 2013 Win64′
3.3 配置cuda选项
取消 ‘BUILD_DOCS’ 和 ‘BUILD_EXAMPLES’
取消 ‘CUDA_ATTACH_VS_BUILD_RULE_TO_CUDA_FILE’
检查 ‘CMAKE_LINKER’, 保证是 Visual Studio 12.0 (vs2013)的路径
勾上 ‘WITH_CUBLAS’, ‘WITH_CUDA’, ‘WITH_OPENGL’, ‘WITH_TBB’
选择 CUDA_GENERATION:可以查看NVIDIA官网,你的显卡的架构。
点击 Configure 刷新配置
3.4 配置tbb选项
设置'TBB_INCLUDE_DIRS',例如“D:\toolkits\tbb43_20140724oss\include”
点击 Configure
然后可以看到TBB_LIB_DIR和TBB_STDDEF_PATH下的目录自动有了,
但是可能是错的,需要改到 Debug 和 Release 文件夹的上级目录为止。
例如 D:/toolkits/tbb43_20140724oss/lib/intel64/vc12〃
点击 Configure 刷新,如果在下方信息框中有:
Use TBB: YES(ver 4.1 interface 6105),Use Cuda: YES(ver5.0),
证明我们已经将inteltbb和CUDA正确配置。3.5 点击generate,生成OpenCV.sln文件
三、编译
1、用vs2013以管理员的身份打开OpenCV.sln文件。
2、在编译之前,需要修改opencv-2.4.9\modules\gpu\src\nvidia\core\NCV.cu文件内容,添加#include ,保证max函数调用不会出错。
3、进行编译,中文是生成,应为是build。
分别在X64下的DEBUG和RELEASE下各生成一次。建议先生成release的,因为这个不会有错误。
首先对 **opencv_core** 和 **opencv_gpu** 两个文件右击,点击生成。前者相对较快,后者大约会两三个小时左右。
然后对**ALL_BUILD** 右击,生成。
然后对**INSTALL** 右击,生成。
在这个过程中如果你装过python,可能debug下会出现
error LNK1104: 无法打开文件“python27_d.lib” C:\OpenCV\VS2013_64\modules\python\LINK opencv_python这个错误,可以参考博客中的方法,将会使用到python27_d.lib的代码中替换为python27.lib。然后重新编译。
编译完成后,重新加载。
四、配置环境
如果你之前配置过opencv,那么请删除之前所有的路径,配置新的。
1、首先配置系统环境变量。
新建opencv路径:

配置path路径,添加
D:\opencv\newmake\install\x64\vc12\lib2、打开vs2013,新建cuda项目,配置环境。
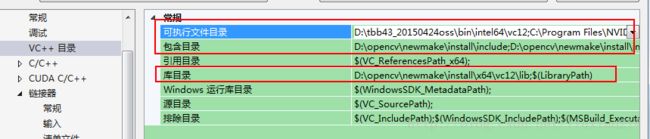
分别在X64(如果没有,则新建)的Debug和Release上的Microsoft.Cpp.Win64.user上,右击,属性—VC++目录:进行修改:
包含目录:
D:opencv\newmake\install\include;
D:opencv\newmake\install\include\opencv;
D:opencv\newmake\install\include\opencv2;
可执行文件目录:
D:\tbb43_20150424oss\bin\intel64\vc12
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v6.5\bin
库目录:
D:opencv\newmake\install\x64\vc12\lib
然后在属性–链接器–附加依赖项中添加:(如果之前配置过opencv,这里不需要改)
opencv_calib3d249d.lib
opencv_contrib249d.lib
opencv_core249d.lib
opencv_features2d249d.lib
opencv_flann249d.lib
opencv_gpu249d.lib
opencv_highgui249d.lib
opencv_imgproc249d.lib
opencv_legacy249d.lib
opencv_ml249d.lib
opencv_nonfree249d.lib
opencv_objdetect249d.lib
opencv_ocl249d.lib
opencv_photo249d.lib
opencv_stitching249d.lib
opencv_superres249d.lib
opencv_ts249d.lib
opencv_video249d.lib
opencv_videostab249d.lib
opencv_calib3d249.lib
opencv_contrib249.lib
opencv_core249.lib
opencv_features2d249.lib
opencv_flann249.lib
opencv_gpu249.lib
opencv_highgui249.lib
opencv_imgproc249.lib
opencv_legacy249.lib
opencv_ml249.lib
opencv_nonfree249.lib
opencv_objdetect249.lib
opencv_ocl249.lib
opencv_photo249.lib
opencv_stitching249.lib
opencv_superres249.lib
opencv_ts249.lib
opencv_video249.lib
opencv_videostab249.lib好了,至此,所有配置已经完成了,那么现在重启一下电脑吧。
五、验证
一共四个验证,前两个可行,后两个有错误,试图解决错误。
1、验证1:简单的图像基本操作,可行:
#include 
另外,这验证中出现错误:错误 1 error LNK1104: 无法打开文件“opencv_calib3d249d.lib”
然后你需要查看属性中的VC++添加的目录,是否是都配置好的,
如果没有配好,则重新配置环境。
如果遇到目录为空,但是点击编辑发现有路径,可以继承父类,然后就发现有路径了。
2、验证2:建立cuda项目,默认kernel.cu文件可行
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include 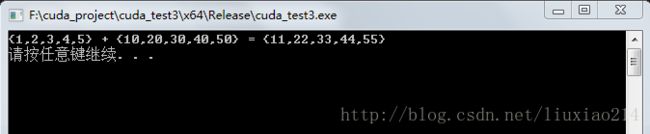
3、验证3:使用gpu::mat加载,有错误:
#include <opencv2/opencv.hpp>
#include <opencv2/gpu/gpu.hpp>
using namespace cv;
using namespace cv::gpu;
#if 1
int main()
{
int num_devices = cv::gpu::getCudaEnabledDeviceCount();
if (num_devices <= 0)
{
std::cerr << "There is no device. " << std::endl;
return -1;
}
std::cerr << "getCudaEnabledDeviceCount NUM :" << num_devices << std::endl;
cv::Mat srcImage = cv::imread("test.jpg");
cv::Mat dstImage;
cv::gpu::GpuMat d_srcImage;//upload image to GPU
cv::gpu::GpuMat d_dstImage;
d_srcImage.upload(srcImage);//中断
cv::gpu::cvtColor(d_srcImage, d_dstImage, CV_BGR2GRAY);
d_dstImage.download(dstImage);
cv::imshow("RGB", srcImage);
cv::imshow("gray", dstImage);
cv::waitKey(0);
return 0;
}
#else
#endif出现问题:
OpenCV Error: Assertion failed (!m.empty()) in cv::gpu::GpuMat::upload, file D:\
opencv\sources\modules\core\src\gpumat.cpp, line 595
解决方法:
d_srcImage.upload(srcImage);//这句出现了中断不知道在我干了什么之后,就突然可以了,也算是已解决吧。
改过一个地方,因为我的笔记本有两个显卡,要用NVIDIA的显卡,所以去开始我们安装的cuda中,打开,将其中选项都改成了true。
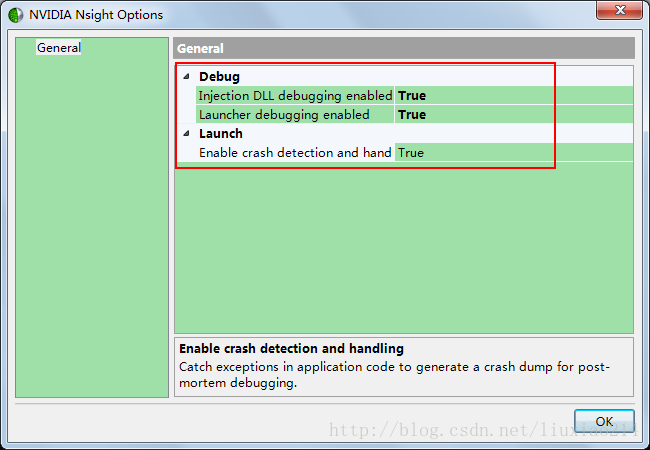
可能是之前没有选用NVIDIA显卡,导致上载出错的吧。
4、验证4:建立cuda项目,查看gpu设备信息,出现错误。
#if 1
#include
#include
#include
#include
#include
#include 直接运行,错误:
“f:\dd\vctools\crt\crtw32\stdio\fopen.c”
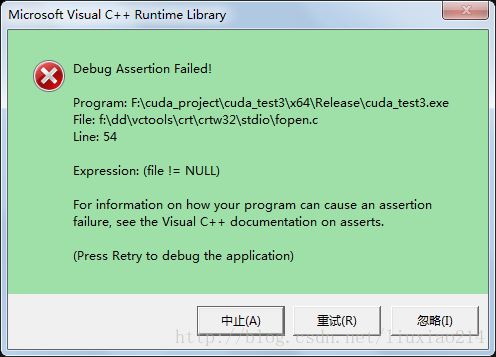
调试,错误:
OpenCV Error: Gpu API call (unknown error) in DeviceProps::get, file D:\opencv\s
ources\modules\dynamicuda\include\opencv2/dynamicuda/dynamicuda.hpp, line 551
解决方法:
cv::gpu::DeviceInfo dev_info(i);//这句中断了调试时发现name没有初始化,没有获取到信息。
目前还没解决。
坑
但是,虽然这个问题没解决,但是其他用到gpu的地方都是好的,且设备信息是读的出来的。
六、最后
cuda编译opencv就是为了用Brox光流,现在也可以用了,撒花完结!!!