轻量级深度学习网络概览
调研了一下最近的一些轻量级网络,列举并简单介绍各个网络的设计思路
PVANET
2016年1月在arxiv网站第一次提交
文章地址:https://arxiv.org/abs/1608.08021
代码链接:https://github.com/sanghoon/pva-faster-rcnn
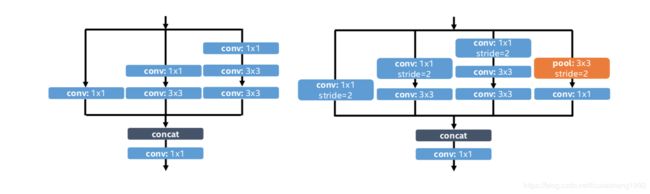
文章目的是减少网络计算量加快网络的速度,文章采用C.Relu(类似于一个对称的Relu函数)和inception结构(分别如下两图所示),通过减少通道数增加网络层数来加速网络
C.Relu结构如下图所示

新的inception结构如下图所示
pvanet网络结构如下表所示

SqueezeNet
2016年2月在arxiv上第一次提交
文章地址:https://arxiv.org/abs/1602.07360
代码地址:https://github.com/DeepScale/SqueezeNet
该文章对精简网络遵循三个策略:
- 使用1*1大小的卷积代替3*3的卷积,这样可以减少网络参数
- 减少3*3卷积层的输入通道数,因为一层3*3网络参数个数计算方式为(输入通道数*输出通道数*3*3),减少通道数能够很大程度的减少网络参数
- 下采样的操作尽量靠后,一般的网络层后会接激活层,文章认为激活层越大网络精度越高,所以推迟对feature map下采样,可以增加激活层的大小,从而提高网络精度。
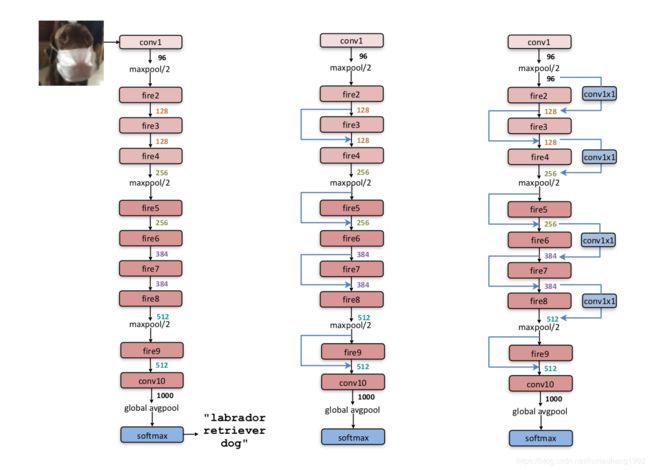
通过上述三点文章提出fire module的结构,根据fire module构造出sqeezenet
fire module结构如下图所示

sqeezenet及其两种变式如下图所示
Densenet
2016年8月在arxiv上第一次提交,发表于CVPR 2017
文章地址:https://arxiv.org/abs/1608.06993
代码地址:https://github.com/liuzhuang13/DenseNet
文章通过借鉴resenet提出的新的网络结构,网络由多个dense block组成,在dense block中每层的输入是前面所有层的输出concat形成的,这样做有下列优点:
- 减轻了vanishing-gradient(梯度消失)
- 加强了feature的传递
- 更有效地利用了feature
- 一定程度上较少了参数数量
Dense block结构如下图所示

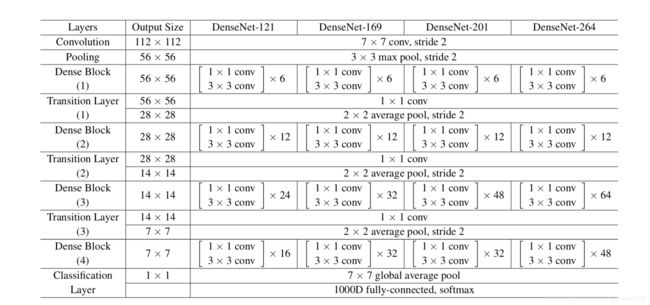
DenseNet结构如下表所示
Xception
2016年10月在arxiv上第一次提交,发表于CVPR 2017
文章地址:https://arxiv.org/abs/1610.02357
代码地址:https://keras.io/applications/#xception
之所以叫Xception,文章指出是因为灵感来自于inception,网络结构其实和inception没太大关系,主要是该网络使用了depthwise和pointwise的卷积,构建了一个新的网络,在与inception V3相同参数量的情况下获得了比inception V3更好的结果
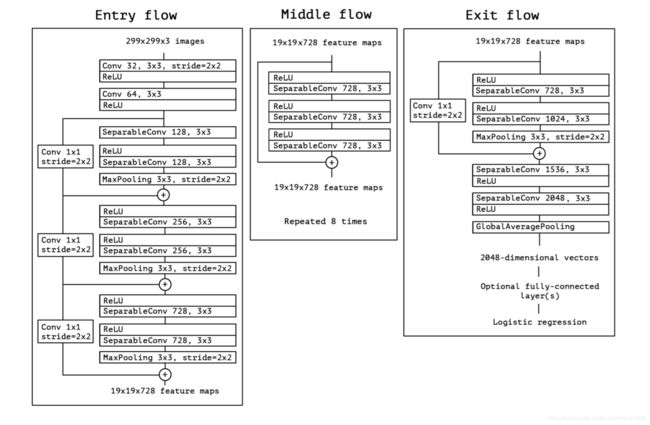
Xception网络结构如下图所示
其中的SeparableConv就是由depthwise和pointwise的卷积组成
CondenseNet
2017年11月在arxiv上第一次提交
文章地址:https://arxiv.org/abs/1711.09224
代码地址: https:// github.com/ShichenLiu/CondenseNet
文章是对Densenet的改进,在Densenet的基础上引入了group conv,但是对于1*1的卷积采用group conv会导致网络效果下降,文章猜测是因为1*1的输入是由前面所有的输出concat得到的,使用group会导致一些不相关的feature map进行计算,从而使得效果降低,所以对于1*1的卷积文章提出了Learned Group Convolution。
Learned Group Convolution不同于Group convolution的是,它可以自己学习分组,而且在得到分组结果后裁去一些组里面不重要的连接
最后对于整体网络结构不同于Densenet的是,不同的block之间的feature map也相互连接,随着网络的加深增大了growth rate(densenet每层的输出通道数)
下图为densenet与CondenseNet单元结构(block)的对比图
左图为DenseNet的结构,中图为CondenseNet训练的结构,右图为CondenseNet推断(inference)的结构
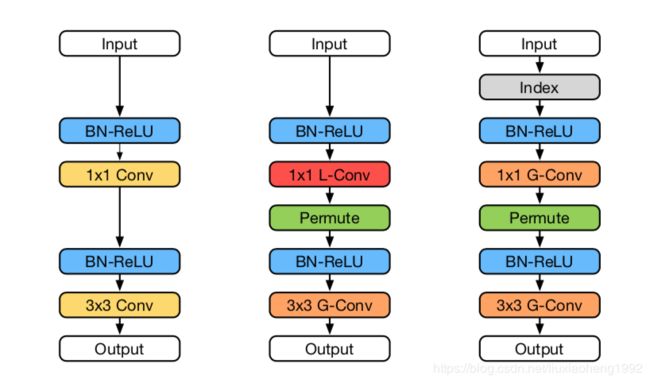
CondenseNet网络的结构示意图如下图所示

MobileNets
2017年4月在arxiv上提交
论文地址:https://arxiv.org/abs/1704.04861
代码地址:https://github.com/tensorflow/models/tree/master/research/slim/nets
文章目的:该网络设计的主要目的不是减小网络而是加快网络的计算速度
主要思想是将一个普通的卷积分解为一个depth wise的卷积和一个point wise的卷积
depthwise就是每个通道有一个卷积核,卷积结果不想加是独立的
pointwise就是将通道数转化为最终输出的通道数,这样可以将各个通道的输出结果有个结合的过程
网络还有两个参数控制通道数和feature map的大小可以在程序中进行设置
普通卷积、depthwise卷积、pointwise卷积的区别如下图所示

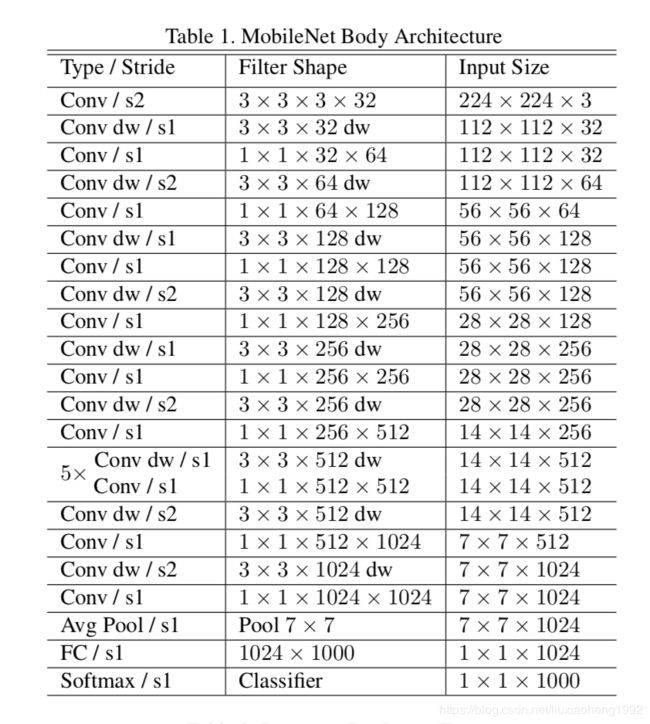
MobileNets网络结构如下表所示
MobileNetV2
2018年1月在arxiv上第一次提交,发表于CVPR 2018
文章地址:https://arxiv.org/abs/1801.04381
代码地址:https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet
文章目的:该网络设计是给手机端使用
网络中继承了mobilenet的depthwise和pointwise的思想,并且采用了resnet中的bottleneck的块结构
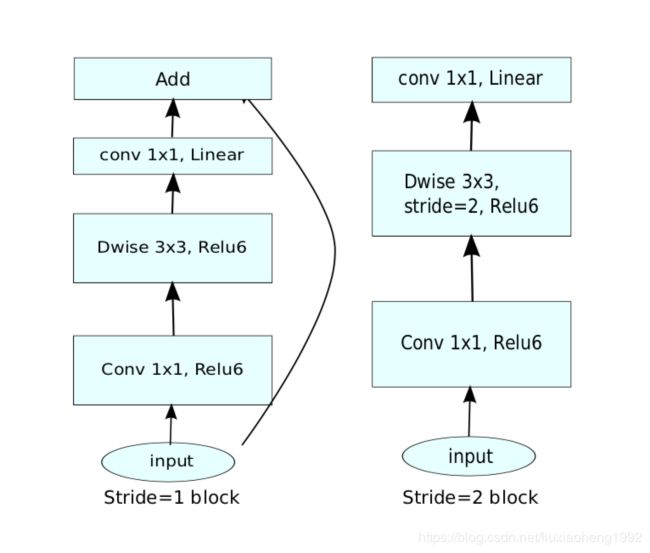
该文章残差块称为Inverted residuals,不同于残差网络的残差块,这里残差块里面的通道数是先增后减(先增加通道数可以增加网络容量),而且减少通道数的卷积层是不带relu函数的(文章认为relu会对提取好的特征有一定的损伤)
Inverted residuals结构如下图所示
左图为stride=1,右图为stride=2的Inverted residuals结构
MobileNetV2结构如下表所示

ShuffleNet
2017年7月在arxiv上第一次提交
文章地址:https://arxiv.org/abs/1707.01083
文章目的:文章主要考虑的是网络的计算量,提出高效的网络
文章采用了group convolutions和channels shuffle,采用group convolutions是为了减少计算量,采用channels shuffle是为了防止group convolutions带来的负效应
shuffle的结构
左图为正经group convulution这样的操作会导致输入一直到输出提取的特征都是分离的没有任何交集
中图的操作方式会导致GConv2的输入与Gconv1是强相关的
右图加入了shuffle的结构,这样不同组卷积的结果能够一起参与运算

ShuffleNet Units
左图为正经的resnet结构并将 3 × 3 3\times 3 3×3的卷积改为depthwise convolution
中图和右图为ShuffleNet Units,其中中图stride=1,右图stride=2

ShuffleNet结构如下图所示

ShuffleNet V2
2018年7月在arxiv上提交,发表在ECCV 2018
文章地址:https://arxiv.org/abs/1807.11164
文章认为现在很多评价网络效率的论文都是只考虑FLOPS,这个一种间接的评价方法,应该直接测试网络的速度,因为相同FLOPS的网络可能因为硬件内存等原因导致网络速度不同
通过一系列的试验,文章总结出四点:
- 对于网络的某一层来说,输入与输出通道数相同这样能更高的加速网络的计算速度
- 群卷积对网络计算速度有一定影响(在相同的FLOPS下,群卷积的分的越细,即g越大,速度越慢)
- 分支越多,网络计算速度越慢
- 减少element-wise的操作
ShuffleNet V2 Units结构如下图所示
a、b图为ShuffleNet Units,c、d图为ShuffleNet V2 Units
a\c图stride=1,b\d图stride=2

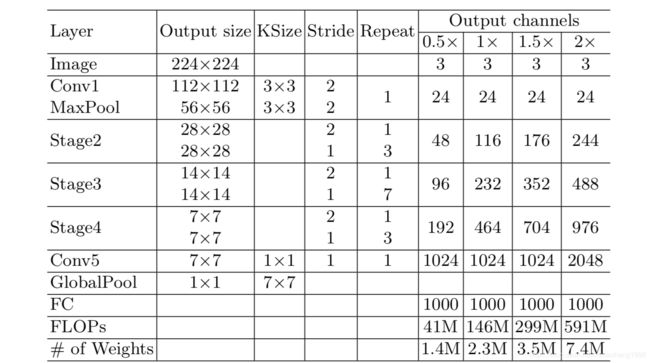
ShuffleNet V2网络结构如下图所示
网络框架和shuffle net基本一样
IGCV1
2017年7月在arxiv上第一次提交,发表在ICCV 2017
文章地址:https://arxiv.org/abs/1707.02725
文中提出了新的block来消除冗余的卷积核,认为该结构在相同参数量的情况下相对与普通的卷积网络结构更宽,效果更好
新的block就是group convolution+point wise的结合
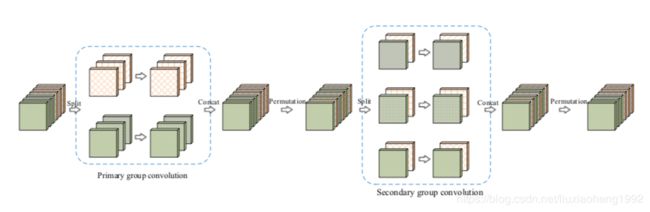
IGCV1 block结构如下图所示
primary group convolution就是普通的group convolution
secondary group convolution就是point wise convolution
IGCV2
2018年4月在arxiv上提交,发表在CVPR 2018
文章地址:https://arxiv.org/abs/1804.06202
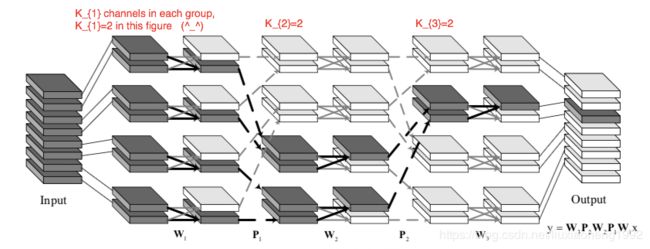
来自IGCV1的启发。第一,组卷积能够在保证性能的情况下降低复杂度,减少计算量;第二,组卷积中每组分配两个通道能够达到最佳性能。通过上述两点将V1扩展,不只是将输入分为两组卷积,而是采用交错组卷积。
IGCV2 block结构如下图所示
IGCV3
2018年6月在arxiv上提交
文章地址:https://arxiv.org/abs/1806.00178
代码地址: https://github.com/homles11/IGCV3
在IGCV2和mobilenetV2基础上提出了新的block,block由point wise conv和group wise组成的一个类Inverted residuals的结构,先增加通道数后减少通道数的操作
IGCV3 block结构如下图所示
下图可以很直观的看出block是先增加通道数后减少通道数
