D*路径搜索算法原理解析及Python实现
D*路径搜索算法原理解析及Python实现
- 1.D*算法简述
- 2.操作
- 2.1扩张
- 2.2障碍处理
- 2.3 发生死锁
- 3.伪代码
- 3.1扩张
- 3.2Raise检查
- 4.变体
- Focussed D*
- D* Lite
- 5.最小成本与当前成本之比
- 6.经典论文算法介绍
- 6.1符号表示
- 6.2算法描述
- 7.D*算法的另一种理解
- 8.D*算法实现(Python)
- 9.算法总结
- 参考资料
- 搜索算法其他文章
1.D*算法简述
D*是以下三种相关增量搜索算法之一:
- 最初的D* (Anthony Stentz的)是一种知情的增量搜索算法。
- Focussed D是Anthony Stentz设计的一种增量启发式搜索算法,它结合了A[3]和原始D的思想。Focussed D源于对原始D*的进一步开发。
- D* Lite[4]是Sven Koenig和Maxim Likhachev基于LPA_star的增量启发式搜索算法,是结合A*思想和动态SWSF-FP的增量启发式搜索算法。
这三种搜索算法都解决了相同的基于假设的路径规划问题,包括利用空闲空间假设进行规划,其中机器人必须在未知地形中导航到给定的目标坐标[7]。它对地形的未知部分(例如:它不包含障碍物)进行假设,并在这些假设下找到从当前坐标到目标坐标的最短路径。然后机器人沿着这条路走。当它观察到新的地图信息(如以前未知的障碍)时,它将这些信息添加到地图中,并在必要时重新规划从当前坐标到给定目标坐标的新的最短路径。它重复这个过程,直到达到目标坐标或确定无法达到目标坐标。当穿越未知地形时,可能会经常发现新的障碍物,所以这种重新规划需要快速。增量式(启发式)搜索算法利用以往问题的经验加快对当前问题的搜索,从而加快对相似搜索问题序列的搜索。假设目标坐标不变,三种搜索算法都比重复的A*搜索更有效。
D_star及其变体已广泛应用于移动机器人和自主车辆导航。当前的系统通常基于D* Lite,而不是最初的D或Focussed D。事实上,甚至Stentz的实验室在一些实现中也使用D* Lite而不是D*。这些导航系统包括在“机遇号”和“勇气号”火星漫游者上测试的原型系统,以及在美国国防部高级研究计划局城市挑战赛中获胜的导航系统。
最初的D是Anthony Stentz在1994年提出的。名称D来自术语“Dynamic A*”,因为该算法的行为类似于A*,只是在算法运行时圆弧成本可能发生变化。
2.操作
D_star的基本操作概述如下。
与Dijkstra算法和A*类似,D *维护要评估的节点列表,称为“OPEN list”。节点被标记为具有以下几种状态之一:
- NEW:意味着它从未被列入OPEN list
- OPEN:意味着它当前在OPEN list中
- CLOSED:意味着它不在OPEN list中
- RAISE:意味着它的成本比上次OPEN list时要高
- LOWER:意味着它的成本比上次OPEN list时要低
2.1扩张
该算法通过迭代地从OPEN list中选择一个节点并对其求值来工作。然后,它将节点的变化传播到所有相邻节点,并将它们放到OPEN list中。这种传播过程称为“扩张”。与从始至终遵循路径的canonical A_star不同,D*从目标节点开始向后搜索。每个扩张节点都有一个反向指针,它指向指向目标的下一个节点,每个节点都知道目标的确切成本。当开始节点是下一个要展开的节点时,算法就完成了,只需遵循反向指针就可以找到目标的路径。
2.2障碍处理
当在指定的路径上检测到障碍物时,所有受影响的点将再次被放到OPEN列表中,这次标记为RAISE。然而,在一个RAISED的节点增加成本之前,算法会检查它的邻居,并检查它是否可以降低节点的成本。如果没有,则提升状态传播到所有节点的后代,即具有反向指针的节点。然后评估这些节点,并且传递RAISE状态,形成波。 当RAISED节点可以减少时,它的反向指针(backpointer)会更新,并将LOWER状态传递给它的邻居。这些RAISE和LOWER的状态波是D*的核心。到这个时候,一系列其他的点就不会被波浪“碰触”了。因此,该算法只适用于受成本变化影响的点。

2.3 发生死锁
这一次,不能如此优雅地绕过死锁。没有一个点可以通过邻居找到一条新的路线到达目的地。因此,他们继续传播他们的成本增加。只有在通道外才能找到点,这些点可以通过可行的路线到达目的地。这就是两个较低的波是如何发展的,它们扩张成具有新路线信息的不可到达的标记点。



3.伪代码
while(!openList.isEmpty()) {
point = openList.getFirst();
expand(point);
}
3.1扩张
void expand(currentPoint) {
boolean isRaise = isRaise(currentPoint);
double cost;
foreach(neighbor in currentPoint.getNeighbors()) {
if(isRaise) {
if(neighbor.nextPoint == currentPoint) {
neighbor.setNextPointAndUpdateCost(currentPoint);
openList.add(neighbor);
} else {
cost = neighbor.calculateCostVia(currentPoint);
if(cost < neighbor.getCost()) {
currentPoint.setMinimumCostToCurrentCost();
openList.add(currentPoint);
}
}
} else {
cost = neighbor.calculateCostVia(currentPoint);
if(cost < neighbor.getCost()) {
neighbor.setNextPointAndUpdateCost(currentPoint);
openList.add(neighbor);
}
}
}
}
3.2Raise检查
boolean isRaise(point) {
double cost;
if(point.getCurrentCost() > point.getMinimumCost()) {
foreach(neighbor in point.getNeighbors()) {
cost = point.calculateCostVia(neighbor);
if(cost < point.getCurrentCost()) {
point.setNextPointAndUpdateCost(neighbor);
}
}
}
return point.getCurrentCost() > point.getMinimumCost();
}
4.变体
Focussed D*
顾名思义,Focussed D是D的一个扩展,它使用启发式的方法来聚焦(focus)RAISE、LOWER对机器人的传播。这样,只更新重要的状态,就像A*只计算某些节点的成本一样。
D* Lite
D* Lite不是基于原始的D或聚焦的D,而是实现了相同的行为。它更容易理解,而且可以用更少的代码行实现,因此名为“D* Lite”。在性能方面,它和Focussed D一样好,甚至更好。D Lite基于Lifelong Planning A*,这是Koenig和Likhachev在几年前提出的。
5.最小成本与当前成本之比
对于D*,区分当前成本和最低成本是很重要的。前者只在收集时重要,而后者非常重要,因为它对OpenList进行了排序。返回最小成本的函数总是当前点的最低成本,因为它是OpenList的第一个条目。
6.经典论文算法介绍
“D_star算法”的名称源自 Dynamic A Star,最初由Anthony Stentz于“Optimal and Efficient Path Planning for Partially-Known Environments”中介绍。它是一种启发式的路径搜索算法,适合面对周围环境未知或者周围环境存在动态变化的场景。
同A_star算法类似,D-star通过一个维护一个优先队列(OpenList)来对场景中的路径节点进行搜索,所不同的是,D*不是由起始点开始搜索,而是以目标点为起始,通过将目标点置于Openlist中来开始搜索,直到机器人当前位置节点由队列中出队为止(当然如果中间某节点状态有动态改变,需要重新寻路,所以才是一个动态寻路算法)。
6.1符号表示
主要介绍一下论文中用到的一些符号及其含义。
论文中将地图中的路径点用State表示,每一个State包含如下信息:
- Backpointer: 指向前一个state的指针,指向的state为当前状态的父辈,当前state称为指针指向state的后代,目标state无Backpointer。(路径搜索完毕后,通过机器人所在的state,通过backpointer即可一步步地移动到目标Goal state,GoalState以后用 G表示),b(X)=Y表示X的父辈为Y。
- Tag:表示当前state的状态,有 New、Open、Closed三种状态,New表示该State从未被置于Openlist中,Open表示该State正位于OpenList中,Closed表示已不再位于Openlist中。
- H(X):代价函数估计,表示当前State到G的开销估计。
- K(X):Key Function,该值是优先队列Openlist中的排序依据,K值最小的State位于队列头,对于处于OpenList上的State X,K(X)表示从X被置于Openlist后,X到G的最小代价H(X),可以简单理解为K(X)将位于Openlist的State X划分为两种不同的状态,一种状态为Raise(如果K(X)
Lower(如果K(X)=H(X)),用来传递路径开销的减少(例如某两点之间开销的减少,或者某一新的节点被加入到Openlist中,可能导致与之相关的节点到目标的路径开销随之减少)。 - k m i n k_{min} kmin:表示所有位于Openlist上的state的最小K值。
- C(X,Y):表示X与Y之间的路径开销。
- Openlist 是依据K值由小到大进行排序的优先队列。
6.2算法描述
搜索的关键是state的传递过程,即由G向机器人所在位置进行搜索的过程,这种传递过程是通过不断地从当前OpenList中取出K值最小的State来实现的,每当一个State由Openlist中移出时,它会将开销传递给它的邻域state,这些邻域state会被置于Openlist中,持续进行该循环,直到机器人所在State的状态为 Closed ,或者Openlist为空(表示不存在到G的路径)。
算法最主要的是两个函数,Process-State 和 Modify-Cost,前者用于计算到目标G的最优路径,后者用于改变两个state之间的开销C(X,Y)并将受影响的state置于Openlist中。
算法的主要流程,在初始时,所有state的t(Tag)被设置为New,H(G)被设置为0,G被放置于OpenList,然后Process-State函数被不断执行,直到机器人所处state X由openlist中出队,然后可以通过机器人的当前state按backpointer指向目标G。当移动过程中发现新探测到的障碍时,Modify-Cost函数立刻被调用,来更正C(X,Y)中的路径开销并将受影响的state重新置于openlist中。
令Y表示robot发现障碍时所在的state,通过不断调用Process-State直到kmin≥H(Y),这时表示路径开销的更改已经传播到了Y,此时,新的路径构建完成。
论文中的伪代码如下:
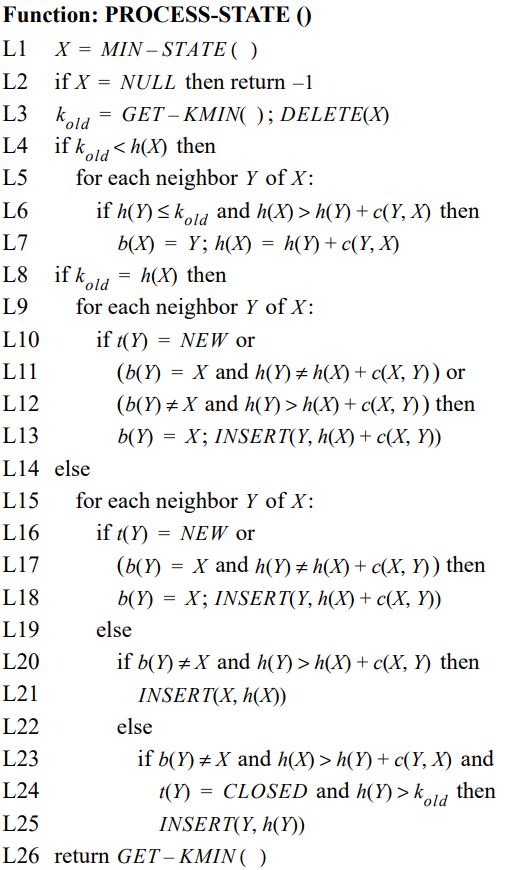
-
L1-L3表示拥有最低K值的X由openlist中移出,如果X为Lower,那么它的路径代价为最优的。
-
在L8-L13,X为Lower状态,X的所有邻接state都被检测是否其路径代价可以更低,状态为New的邻接state被赋予初始路径开销值,并且开销的变动被传播给每一个backpointer指向X的邻接state Y(不管这个新的开销比原开销大或者小),也就是说只要你指向了X,那么X的路径开销变动时,你的路径代价必须随之改变。这里可能存在由于X路径开销变动过大,Y可以通过非X的其他state到达目标且路径开销更小的情况,这点在L8-13中并没有处理,而是放在后续针对Y的process-state函数中,在对Y进行处理时,会将其backpointer指向周围路径开销最小的state。如果X的邻接State状态为New时,应将其邻接state的backpointer指向X。所有路径开销有所变动的state都被置于Openlist中进行处理,从而将变动传播给邻接的state。
-
在L4-L7中X为Raise,它的路径开销H可能不是最优的,通过其邻居state中已经处于最优开销(即h(Y)≤kold)的节点来优化X的路径开销,如果存在更短的路径,则将X的backpointer指向其neighbor。
-
在L15-L18中,开销变动传播到状态为New的邻居state。如果X可以使一个backpointer并不指向X的邻居state的路径开销最小,即Y通过X到目标G的距离更短,但是此时Y的backpointer并不指向X,针对这种情况,可以将X重新置于Openlist中进而优化Y。
-
在L23-25中,如果X可以通过一个状态为closed的并不是最理想的邻居stateY来减小路径开销,那么将Y重新置于Openlist中。

在modify-cost中,更新C(X,Y)并将X重新置于Openlist中,当X通过process-state进行传播时,会对Y进行开销计算, h ( Y ) = h ( X ) + c ( X , Y ) h(Y)=h(X)+c(X,Y) h(Y)=h(X)+c(X,Y)。
7.D*算法的另一种理解
以下来自于参考资料[2]:
- 先用Dijstra算法从目标节点G向起始节点搜索。储存路网中目标点到各个节点的最短路和该位置到目标点的实际值h,k(k为所有变化h之中最小的值,当前为k=h。原OPEN和CLOSE中节点信息保存。
- 机器人沿最短路开始移动,在移动的下一节点没有变化时,无需计算,利用上一步Dijstra计算出的最短路信息从出发点向后追述即可,当在Y点探测到下一节点X状态发生改变,如堵塞。机器人首先调整自己在当前位置Y到目标点G的实际值h(Y),h(Y)=X到Y的新权值c(X,Y)+X的原实际值h(X).X为下一节点(到目标点方向Y->X->G),Y是当前点。k值取h值变化前后的最小。机器人沿最短路开始移动,在移动的下一节点没有变化时,无需计算,利用上一步Dijstra计算出的最短路信息从出发点向后追述即可,当在Y点探测到下一节点X状态发生改变,如堵塞。机器人首先调整自己在当前位置Y到目标点G的实际值h(Y),h(Y)=X到Y的新权值c(X,Y)+X的原实际值h(X).X为下一节点(到目标点方向Y->X->G),Y是当前点。k值取h值变化前后的最小。
- 用A_star或其它算法计算,这里假设用A_star算法,遍历Y的子节点,点放入CLOSE,调整Y的子节点a的h值,h(a)=h(Y)+Y到子节点a的权重C(Y,a),比较a点是否存在于OPEN和CLOSE中,方法如下:用A或其它算法计算,这里假设用A算法,遍历Y的子节点,点放入CLOSE,调整Y的子节点a的h值,h(a)=h(Y)+Y到子节点a的权重C(Y,a),比较a点是否存在于OPEN和CLOSE中,方法如下:
while()
{
从OPEN表中取k值最小的节点Y;
遍历Y的子节点a,计算a的h值 h(a)=h(Y)+Y到子节点a的权重C(Y,a)
{
if(a in OPEN) 比较两个a的h值
if( a的h值小于OPEN表a的h值 )
{
更新OPEN表中a的h值;k值取最小的h值
有未受影响的最短路经存在
break;
}
if(a in CLOSE) 比较两个a的h值 //注意是同一个节点的两个不同路径的估价值
if( a的h值小于CLOSE表的h值 )
{
更新CLOSE表中a的h值; k值取最小的h值;将a节点放入OPEN表
有未受影响的最短路经存在
break;
}
if(a not in both)
将a插入OPEN表中; //还没有排序
}
放Y到CLOSE表;
OPEN表比较k值大小进行排序;
}
8.D*算法实现(Python)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2018/12/13 0013 22:30
# @Author : 心一
# @Site :
# @File : D_star.py
# @Software: PyCharm
import math
from sys import maxsize # 导入最大数,2^63-1
class State(object):
def __init__(self, x, y):
self.x = x
self.y = y
self.parent = None
self.state = "."
self.t = "new"
self.h = 0
self.k = 0 # k即为f
def cost(self, state):
if self.state == "#" or state.state == "#":
return maxsize # 存在障碍物时,距离无穷大
return math.sqrt(math.pow((self.x - state.x), 2) +
math.pow((self.y - state.y), 2))
def set_state(self, state):
if state not in ["S", ".", "#", "E", "*","+"]:
return
self.state = state
class Map(object):
'''
创建地图
'''
def __init__(self, row, col):
self.row = row
self.col = col
self.map = self.init_map()
def init_map(self):
# 初始化map
map_list = []
for i in range(self.row):
tmp = []
for j in range(self.col):
tmp.append(State(i, j))
map_list.append(tmp)
return map_list
def print_map(self):
for i in range(self.row):
tmp = ""
for j in range(self.col):
tmp += self.map[i][j].state + " "
print(tmp)
def get_neighbers(self, state):
# 获取8邻域
state_list = []
for i in [-1, 0, 1]:
for j in [-1, 0, 1]:
if i == 0 and j == 0:
continue
if state.x + i < 0 or state.x + i >= self.row:
continue
if state.y + j < 0 or state.y + j >= self.col:
continue
state_list.append(self.map[state.x + i][state.y + j])
return state_list
def set_obstacle(self, point_list):
# 设置障碍物的位置
for x, y in point_list:
if x < 0 or x >= self.row or y < 0 or y >= self.col:
continue
self.map[x][y].set_state("#")
class Dstar(object):
def __init__(self, maps):
self.map = maps
self.open_list = set() # 创建空集合
def process_state(self):
'''
D*算法的主要过程
:return:
'''
x = self.min_state() # 获取open list列表中最小k的节点
if x is None:
return -1
k_old = self.get_kmin() #获取open list列表中最小k节点的k值
self.remove(x) # 从openlist中移除
# 判断openlist中
if k_old < x.h:
for y in self.map.get_neighbers(x):
if y.h <= k_old and x.h > y.h + x.cost(y):
x.parent = y
x.h = y.h + x.cost(y)
elif k_old == x.h:
for y in self.map.get_neighbers(x):
if y.t == "new" or y.parent == x and y.h != x.h + x.cost(y) \
or y.parent != x and y.h > x.h + x.cost(y):
y.parent = x
self.insert(y, x.h + x.cost(y))
else:
for y in self.map.get_neighbers(x):
if y.t == "new" or y.parent == x and y.h != x.h + x.cost(y):
y.parent = x
self.insert(y, x.h + x.cost(y))
else:
if y.parent != x and y.h > x.h + x.cost(y):
self.insert(y, x.h)
else:
if y.parent != x and x.h > y.h + x.cost(y) \
and y.t == "close" and y.h > k_old:
self.insert(y, y.h)
return self.get_kmin()
def min_state(self):
if not self.open_list:
return None
min_state = min(self.open_list, key=lambda x: x.k) # 获取openlist中k值最小对应的节点
return min_state
def get_kmin(self):
# 获取openlist表中k(f)值最小的k
if not self.open_list:
return -1
k_min = min([x.k for x in self.open_list])
return k_min
def insert(self, state, h_new):
if state.t == "new":
state.k = h_new
elif state.t == "open":
state.k = min(state.k, h_new)
elif state.t == "close":
state.k = min(state.h, h_new)
state.h = h_new
state.t = "open"
self.open_list.add(state)
def remove(self, state):
if state.t == "open":
state.t = "close"
self.open_list.remove(state)
def modify_cost(self, x):
if x.t == "close": # 是以一个openlist,通过parent递推整条路径上的cost
self.insert(x, x.parent.h + x.cost(x.parent))
def run(self, start, end):
self.open_list.add(end)
while True:
self.process_state()
if start.t == "close":
break
start.set_state("S")
s = start
while s != end:
s = s.parent
s.set_state("+")
s.set_state("E")
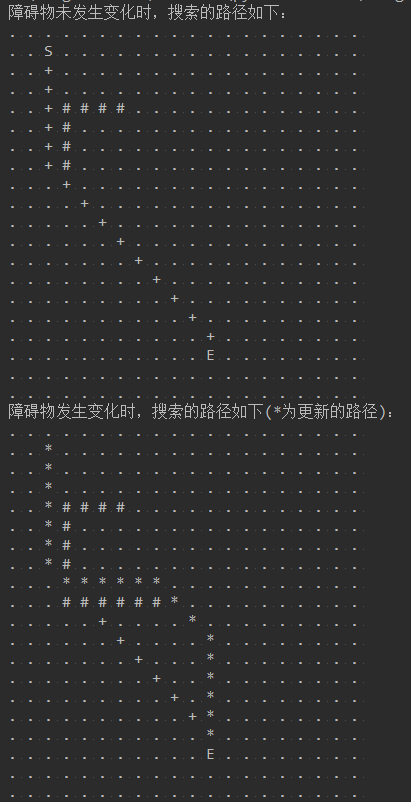
print('障碍物未发生变化时,搜索的路径如下:')
self.map.print_map()
tmp = start # 起始点不变
self.map.set_obstacle([(9, 3), (9, 4), (9, 5), (9, 6), (9, 7), (9, 8)]) # 障碍物发生变化
'''
从起始点开始,往目标点行进,当遇到障碍物时,重新修改代价,再寻找路径
'''
while tmp != end:
tmp.set_state("*")
# self.map.print_map()
# print("")
if tmp.parent.state == "#":
self.modify(tmp)
continue
tmp = tmp.parent
tmp.set_state("E")
print('障碍物发生变化时,搜索的路径如下(*为更新的路径):')
self.map.print_map()
def modify(self, state):
'''
当障碍物发生变化时,从目标点往起始点回推,更新由于障碍物发生变化而引起的路径代价的变化
:param state:
:return:
'''
self.modify_cost(state)
while True:
k_min = self.process_state()
if k_min >= state.h:
break
if __name__ == '__main__':
m = Map(20, 20)
m.set_obstacle([(4, 3), (4, 4), (4, 5), (4, 6), (5, 3), (6, 3), (7, 3)])
start = m.map[1][2]
end = m.map[17][11]
dstar = Dstar(m)
dstar.run(start, end)
# m.print_map()
运行效果如下:
9.算法总结
相比A-star算法,D-star的主要特点就是由目标位置开始向起始位置进行路径搜索,当物体由起始位置向目标位置运行过程中,发现路径中存在新的障碍时,对于目标位置到新障碍之间的范围内的路径节点,新的障碍是不会影响到其到目标的路径的。新障碍只会影响的是物体所在位置到障碍之间范围的节点的路径。在这时通过 将新的障碍周围的节点加入到Openlist中进行处理然后向物体所在位置进行传播,能最小程度的减少计算开销。
D*路径搜索的过程和Dijkstra算法比较像,A-star算法中f(n)=g(n)+h(n),h(n)在D-star中并没有体现,路径的搜索并没有A-star所具有的方向感,即朝着目标搜索的感觉,这种搜索更多的是一种由目标位置向四周发散搜索,直到把起始位置纳入搜索范围为止,更像是Dijkstra算法。
同时,由示例的算法效果来看,D_star算法能够在障碍物发生变化时,仍能找到一条路径,但不一定是一条最短的路径。
参考资料
[1] Wiki百科:D*
[2] 最短路经算法简介(Dijkstra算法,A算法,D算法)(转载)
[3] D star路径搜索算法
[4] Optimal and Efficient Path Planning for Partially-Known Environments.pdf
搜索算法其他文章
Field Dstar路径规划算法
Dstar Lite路径规划算法
终身规划Astar算法(LPA*):Lifelong Planning A*