Hierarchical Attention Network for Document Classification中文文本分类,以及模型部署
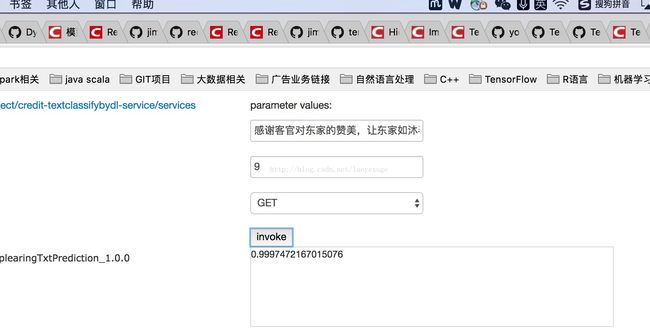
这周五写了尝试把attention加入rnn网络中做文本分类,实际这种思想来源于Hierarchical Attention Network for Document Classification,周末整整花了一天半的时间来搞这个网络,终于把模型在tensorflow训练好,并部署在java上面,下面看看吧:
首先是把一段中文文本看成一个doc,然后把doc分解成sen,再对sen进行分词,在这里涉及的主要逻辑是,doc怎么分解成sen,我首先是把全角转化为半角,然后按照标点符号进行split,符合涉及:
public final static String splitstr = "[;。.,:?!~、]";
public static String getSplitStr(String text) { String result = qj2bj(text).replaceAll("#", "").replaceAll("\n", "#") .replaceAll("\\s+", "#").replaceAll("\\-{2,}", "#") .replaceAll(splitstr, "#"); return result; }
句子跟句子之间以#号隔开,最后分词转化为下面文本:
1 我是 这边 工作人员 # 要是 有 什么 问题 可以 咨询 我 #
第一列是label,以\t隔开,后面是doc,像这个doc下面有两个sen,我这边由于全部是短文本,所以全部都转化为20*20的一个形式,多余的截取,不够用0填充。后面对句子进行了分词,把文本抓化为这种形式然后就是python代码了,主要文件如下:
data_utils.py #一些方法runha.py #主程序test.pyconfiguration.py #一些参数model.py #han模型tensorflow #存放数据目录
data_utils.py :
import osimport numpy as npimport codecsimport pickledef _read_vocab(filename): """读取词汇列别""" words=list(map(lambda line:line.strip(),codecs.open(filename,'r',encoding='utf-8').readlines())) word_to_id=dict(zip(words,range(len(words)))) return words,word_to_iddef _read_file(filename,word_to_id,num_classes=2,max_sent_in_doc=20,max_word_in_sent=20): data_x=[] data_y=[] with open(filename, "r") as f: for line in f: # doc=[] doc = np.zeros((max_sent_in_doc, max_word_in_sent), dtype=np.int32) doclabel = line.split("\t") if len(doclabel)>1: label=int(doclabel[0]) sents=doclabel[1].split("#") for i, sent in enumerate(sents): if i < max_sent_in_doc and sent!='': for j, word in enumerate(sent.strip().split(" ")): if j < max_word_in_sent and word!='' : doc[i][j] = word_to_id.get(word, 0) labels = [0] * num_classes labels[label - 1] = 1 data_y.append(labels) data_x.append(doc.tolist()) #pickle.dump((data_x, data_y), open('tensorflow/business/business_data', 'wb')) return data_x,data_ydef preocess_file(data_path,vocapath): """一次性返回所有的数据""" words,word_to_id=_read_vocab(vocapath) x_train, y_train = _read_file(data_path, word_to_id) return x_train, y_train,wordsdef batch_iter(data,batch_size=64,num_epochs=5): """生成批次数据""" data=np.array(data) data_size=len(data) num_batchs_per_epchs=int((data_size-1)/batch_size)+1 for epoch in range(num_epochs): indices=np.random.permutation(np.arange(data_size)) shufflfed_data=data[indices] for batch_num in range(num_batchs_per_epchs): start_index=batch_num*batch_size end_index=min((batch_num + 1) * batch_size, data_size) yield shufflfed_data[start_index:end_index]if __name__=='__main__': path = "tensorflow/business/vocab.txt" words,word_to_id=_read_vocab(path) print(words[0:10]) print(len(word_to_id))
model.py
import tensorflow as tffrom tensorflow.contrib import rnnfrom tensorflow.contrib import layersimport timeclass HAN(): def __init__(self,config): self.config=config self.max_sentence_num=self.config.max_sent_in_doc self.max_sentence_length=self.config.max_word_in_sent self.vocab_size =self.config.vocab_size self.num_classes = self.config.num_classes self.embedding_size = self.config.embedding_size self.hidden_size = self.config.hidden_dim # x的shape为[batch_size, 句子数, 句子长度(单词个数)],但是每个样本的数据都不一样,,所以这里指定为空 # y的shape为[batch_size, num_classes] self.input_x = tf.placeholder(tf.int32, [None, self.max_sentence_num, self.max_sentence_length], name='input_x') self.input_y = tf.placeholder(tf.float32, [None, self.num_classes], name='input_y') self.keep_prob = tf.placeholder(tf.float32, name='keep_prob') # 构建模型 word_embedded = self.word2vec() sent_vec = self.sent2vec(word_embedded) doc_vec = self.doc2vec(sent_vec) out = self.classifer(doc_vec) self.rnnhamodel(out) def rnnhamodel(self,out): with tf.name_scope("score"): self.pred_y = tf.nn.softmax(out, name="pred_y") tf.add_to_collection('pred_network', self.pred_y) with tf.name_scope('loss'): self.loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=self.input_y, logits=out, name='loss')) with tf.name_scope('acc'): predict = tf.argmax(out, axis=1, name='predict') label = tf.argmax(self.input_y, axis=1, name='label') self.acc = tf.reduce_mean(tf.cast(tf.equal(predict, label), tf.float32)) global_step = tf.Variable(0, trainable=False) optimizer = tf.train.AdamOptimizer(self.config.learning_rate) # RNN中常用的梯度截断,防止出现梯度过大难以求导的现象 tvars = tf.trainable_variables() grads, _ = tf.clip_by_global_norm(tf.gradients(self.loss, tvars),self.config.grad_clip) grads_and_vars = tuple(zip(grads, tvars)) self.train_op = optimizer.apply_gradients(grads_and_vars, global_step=global_step) def word2vec(self): # 嵌入层 with tf.name_scope("embedding"): embedding_mat = tf.Variable(tf.truncated_normal((self.vocab_size, self.embedding_size))) # shape为[batch_size, sent_in_doc, word_in_sent, embedding_size] word_embedded = tf.nn.embedding_lookup(embedding_mat, self.input_x) return word_embedded def sent2vec(self, word_embedded): with tf.name_scope("sent2vec"): # GRU的输入tensor是[batch_size, max_time, ...].在构造句子向量时max_time应该是每个句子的长度,所以这里将 # batch_size * sent_in_doc当做是batch_size.这样一来,每个GRU的cell处理的都是一个单词的词向量 # 并最终将一句话中的所有单词的词向量融合(Attention)在一起形成句子向量 # shape为[batch_size*sent_in_doc, word_in_sent, embedding_size] word_embedded = tf.reshape(word_embedded, [-1, self.max_sentence_length, self.embedding_size]) # shape为[batch_size*sent_in_doce, word_in_sent, hidden_size*2] word_encoded = self.BidirectionalGRUEncoder(word_embedded, name='word_encoder') # shape为[batch_size*sent_in_doc, hidden_size*2] sent_vec = self.AttentionLayer(word_encoded, name='word_attention') return sent_vec def doc2vec(self, sent_vec): # 原理与sent2vec一样,根据文档中所有句子的向量构成一个文档向量 with tf.name_scope("doc2vec"): sent_vec = tf.reshape(sent_vec, [-1, self.max_sentence_num, self.hidden_size * 2]) # shape为[batch_size, sent_in_doc, hidden_size*2] doc_encoded = self.BidirectionalGRUEncoder(sent_vec, name='sent_encoder') # shape为[batch_szie, hidden_szie*2] doc_vec = self.AttentionLayer(doc_encoded, name='sent_attention') return doc_vec def classifer(self, doc_vec): # 最终的输出层,是一个全连接层 with tf.name_scope('doc_classification'): out = layers.fully_connected(inputs=doc_vec, num_outputs=self.num_classes, activation_fn=None) return out def BidirectionalGRUEncoder(self, inputs, name): # 双向GRU的编码层,将一句话中的所有单词或者一个文档中的所有句子向量进行编码得到一个 2×hidden_size的输出向量,然后在经过Attention层,将所有的单词或句子的输出向量加权得到一个最终的句子/文档向量。 # 输入inputs的shape是[batch_size, max_time, voc_size] with tf.variable_scope(name): if self.config.isgru: GRU_cell_fw = rnn.GRUCell(self.hidden_size) GRU_cell_bw = rnn.GRUCell(self.hidden_size) else: GRU_cell_fw = rnn.LSTMCell(self.hidden_size) GRU_cell_bw = rnn.LSTMCell(self.hidden_size) # fw_outputs和bw_outputs的size都是[batch_size, max_time, hidden_size] ((fw_outputs, bw_outputs), (_, _)) = tf.nn.bidirectional_dynamic_rnn(cell_fw=GRU_cell_fw, cell_bw=GRU_cell_bw, inputs=inputs, sequence_length=self.length(inputs), dtype=tf.float32) # outputs的size是[batch_size, max_time, hidden_size*2] outputs = tf.concat((fw_outputs, bw_outputs), 2) return outputs def AttentionLayer(self, inputs, name): # inputs是GRU的输出,size是[batch_size, max_time, encoder_size(hidden_size * 2)] with tf.variable_scope(name): # u_context是上下文的重要性向量,用于区分不同单词/句子对于句子/文档的重要程度, # 因为使用双向GRU,所以其长度为2×hidden_szie u_context = tf.Variable(tf.truncated_normal([self.hidden_size * 2]), name='u_context') # 使用一个全连接层编码GRU的输出的到期隐层表示,输出u的size是[batch_size, max_time, hidden_size * 2] h = layers.fully_connected(inputs, self.hidden_size * 2, activation_fn=tf.nn.tanh) # shape为[batch_size, max_time, 1] alpha = tf.nn.softmax(tf.reduce_sum(tf.multiply(h, u_context), axis=2, keep_dims=True), dim=1) # reduce_sum之前shape为[batch_szie, max_time, hidden_szie*2],之后shape为[batch_size, hidden_size*2] atten_output = tf.reduce_sum(tf.multiply(inputs, alpha), axis=1) atten_output = tf.nn.dropout( atten_output, self.keep_prob, name="dropout") return atten_output def length(self,sequences): used = tf.sign(tf.reduce_max(tf.abs(sequences), reduction_indices=2)) seq_len = tf.reduce_sum(used, reduction_indices=1) return tf.cast(seq_len, tf.int32)
config.py:
class HAConfig: max_sent_in_doc = 20 max_word_in_sent = 20 embedding_size = 64 # 词向量维度 num_classes = 2 # 类别个数 vocab_size = 9000 # 词汇表的大小 num_layers = 2 # 隐含层的层数 hidden_dim = 128 # 隐藏层神经元 rnn = 'gru' # lstm 或 gru keep_prob = 0.7 # dropout保留比例 learning_rate = 1e-3 # 学习率 grad_clip=5 batch_size = 64 # 每批训练大小 num_epochs = 15 # 总迭代轮次 print_per_batch = 100 # 每多少轮输出一次结果 l2_reg_lambda = 0.003 isgru = True
run.py:
结果:
2017-11-26 14:48:10.169322: I tensorflow/core/common_runtime/gpu/pool_allocator.cc:247] PoolAllocator: After 3141 get requests, put_count=2789 evicted_count=1000 eviction_rate=0.358551 and unsatisfied allocation rate=0.4377592017-11-26 14:48:10.169371: I tensorflow/core/common_runtime/gpu/pool_allocator.cc:259] Raising pool_size_limit_ from 256 to 2812017-11-26 14:48:11.145964: I tensorflow/core/common_runtime/gpu/pool_allocator.cc:247] PoolAllocator: After 3278 get requests, put_count=3359 evicted_count=1000 eviction_rate=0.297708 and unsatisfied allocation rate=0.2983532017-11-26 14:48:11.146014: I tensorflow/core/common_runtime/gpu/pool_allocator.cc:259] Raising pool_size_limit_ from 655 to 720Iter: 100, Train Loss: 0.12, Train Acc: 95.31%, Time: 0:00:12Iter: 200, Train Loss: 0.096, Train Acc: 95.31%, Time: 0:00:22Iter: 300, Train Loss: 0.11, Train Acc: 96.88%, Time: 0:00:33Iter: 400, Train Loss: 0.11, Train Acc: 96.88%, Time: 0:00:44Iter: 500, Train Loss: 0.16, Train Acc: 93.75%, Time: 0:00:55Converted 25 variables to const ops.attention模型在第500步已经保存Iter: 600, Train Loss: 0.048, Train Acc: 96.88%, Time: 0:01:06Iter: 700, Train Loss: 0.092, Train Acc: 96.88%, Time: 0:01:16Iter: 800, Train Loss: 0.057, Train Acc: 98.44%, Time: 0:01:27Iter: 900, Train Loss: 0.047, Train Acc: 96.88%, Time: 0:01:38Iter: 1000, Train Loss: 0.056, Train Acc: 98.44%, Time: 0:01:48Converted 25 variables to const ops.attention模型在第1000步已经保存Iter: 1100, Train Loss: 0.02, Train Acc: 98.44%, Time: 0:01:59Iter: 1200, Train Loss: 0.028, Train Acc: 98.44%, Time: 0:02:10Iter: 1300, Train Loss: 0.0041, Train Acc: 100.00%, Time: 0:02:21Iter: 1400, Train Loss: 0.042, Train Acc: 98.44%, Time: 0:02:31Iter: 1500, Train Loss: 0.0043, Train Acc: 100.00%, Time: 0:02:42
在java中调用要写两个方法具体如下:
public static int[][][] gettexttoidBuinessByCutHAN(String text, Map<String, Integer> map) { int[][][] docs = new int[1][20][20]; if (StringUtils.isBlank(text)) { return docs; } String docword = WordUtilHAN.getSegmentHANModelStr(text); if (StringUtils.isBlank(docword)) { return docs; } String[] sents=docword.split("#"); for(int i=0;i<sents.length&& i<20;i++){ if(StringUtils.isNotBlank(sents[i])){ String[] words=sents[i].trim().split(" "); for(int j=0;j<words.length&& j<20;j++){ if(StringUtils.isNotBlank(words[j])){ if(map.containsKey(words[j])){ docs[0][i][j]=map.get(words[j]); } } } } } return docs; }
public static double getClassifyBusinessByHANModel(String text, Session sess, Map<String, Integer> map, Tensor keep_prob) { if (StringUtils.isBlank(text)) { return 0.0; } int[][][] arr = gettexttoidBuinessByCutHAN(text, map); Tensor input = Tensor.create(arr); Tensor result = sess.runner().feed("input_x", input).feed("keep_prob", keep_prob).fetch("score/pred_y").run() .get(0); long[] rshape = result.shape(); int nlabels = (int) rshape[1]; int batchSize = (int) rshape[0]; float[][] logits = result.copyTo(new float[batchSize][nlabels]); if (nlabels > 1 && batchSize > 0) { return logits[0][0]; } return 0.0; }
启动service: