Weka初体验——中文文本分类
最近在公司实习做电商评论相关的数据分析,需要调几个分类器,组里的代码一贯用Java编写,为了提高工作效率,找了找Java环境下的机器学习工具库,发现了Weka这个神奇的东西。
Weka介绍及下载
Weka是一个Java编写的具有10几年历史的开源机器学习与数据挖掘软件,曾获得SIGKDD颁发的数据挖掘领域内最高服务奖。

上面这张图就是Weka的主页面,GUI做得很简陋,但它的功能的确非常强大。而且它不仅可以通过GUI操作,还有CLI(command-line interface)命令行模式,而且因为它的源码使用java编写,所有它的jar包还可以导入java的工程中,直接调用api。
我们今天先简单分享一下在使用GUI的过程中遇到的一些问题。
我下载的是Weka官网上的3-7-12 64位不带Java VM的版本,大家可以点击这里直接下载这个版本的,也可以点击Weka官网去寻找更新版本的。简单解释一下各个版本的区别,Weka官网上有Stable Version(稳定版)和Developer Version(开发版)两种,开发版修复了之前发现的bug并增加了一些新的特性,所以我选择了下载最新的开发版。(weka-3-7-12jre-x64.exe; 62.1 MB)这个是包含Java 虚拟机的,如果大家不确定自己电脑里是否有Java虚拟机环境,就下载这个。
修改配置文件,使其支持中文
安装成功之后,点击进入就会看到第一张图的界面。但Weka默认是不支持中文的,需要改一下配置文件,也很简单。
配置文件是在Weka安装后的目录下,比如我的是在C:\Program Files\Weka-3-7\RunWeka.ini,打开这个文件,找到fileEncoding=Cp1252这一行,改成fileEncoding=utf-8即可。如下:
# The file encoding; use "utf-8" instead of "Cp1252" to display UTF-8 characters in the
# GUI, e.g., the Explorer
fileEncoding=utf-8如果是在C盘,可能会提示没有权限保存,这时可以把这个配置文件复制到桌面,修改完了再替换回去。
有些同学,改完配置文件,中文依然乱码,可能因为源文件不是utf8编码格式的,可以用notepad++把arff文件打开,然后选择格式->转为UTF-8编码格式,保存。
使用Weka进行文本分类
数据格式
Weka使用的数据格式是它自己规定的,arff格式,大概就是这个样子:
@relation e__dd_data2
@attribute text string
@attribute @@class@@ {0,1}
@data
'三年 上门服务 有 优势',0
'开机 电脑 硬盘 有异 响',1
'配置 很 高 办公 用 很 合适',0
'对得起 这个 价格',0可以看到这是一个二分类的语料,我们需要事先把每条中文语料分词, 将各词以空格连接好,再存到每个文件中,每条语料(就是上面的每行)是一个文件。
这个arff文件是由Weka自己生成的,我们需要提供的是一个包含数据的文件夹。
我的文件夹名为data,其中包含两个子文件夹,名字分别为“0”和“1”,就是两个分类的类名(如果是3个分类就3个子文件夹)。每个子文件夹中包含多个文件,每个文件中的内容就是一条语料。
比如上面的例子,名字为“0”的子文件夹中就包含3个文件,“1”中就包含1个文件。
在Weka的Simple CLI中运行下面这条命令,我的data文件夹是在e盘根目录下,运行成功后,将生成e:/data.arff这个文件。
java weka.core.converters.TextDirectoryLoader -dir e:/data > e:/data.arff进行分类训练
- 进入Weka的Explorer页面,Open file..选中这个e:/data.arff文件
在Filter中点击Choose
选择 weka->filters->unsupervised->attribute->StringToWordVector
点击Apply之后,Weka将自动统计词频,将词转成特征。在StringToWordVector中可以配置是否使用TFIDF特征,词频是否只使用
0,1统计(outputWordCounts=false)进入Classify面板,在Start按钮上面的下拉框中,选中
(Nom)@@class@@这个表示分类的标签属性列点Choose按钮选择trees中的J48,然后点击Start,Weka便开始进行训练。只要数据格式正确了,可以使用这里面的各个分类器进行训练,比如
RandomForest,NaiveBayes,比较分类效果。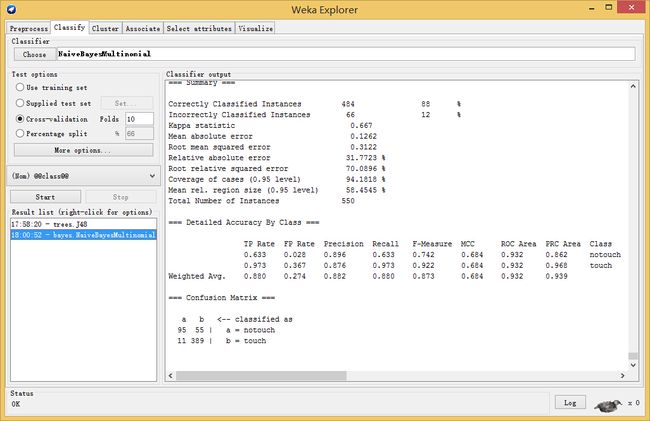
使用libsvm
Weka的安装包中没有libsvm.jar,所以libsvm一直是灰色的,需要我们自己下载libsvm的包
下载地址:http://www.csie.ntu.edu.tw/~cjlin/libsvm/libsvm-3.20.zip
下载完解压,我的是解压到了C:\Program Files\libsvm-3.20
还需要一步操作,把C:\Program Files\libsvm-3.20\java\libsvm.jar加入环境变量CLASSPATH中,注意是在最后追加,用英文的;号隔开,别把原来的值给删没了。
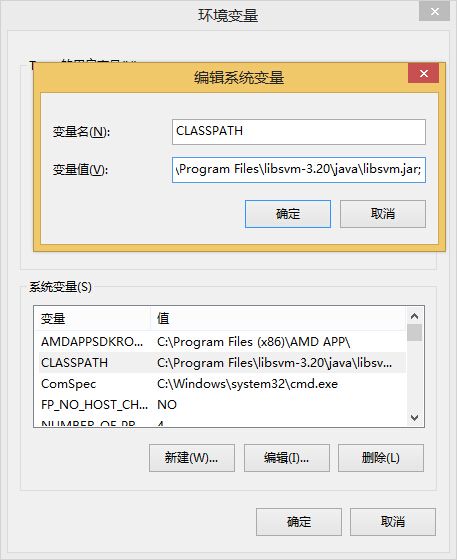
重启Weka,就可以使用libsvm了。
看来Weka真的很强大,只要我们整理出一份符合要求的数据格式,导入到Weka里,就可以通过GUI的操作比较不同分类算法的效果了。下一篇将继续探索Weka在Java程序中的使用,毕竟还是用编程语言控制更灵活一些。通过阅读源码,也让我们能够理解得更加深入。