使用3台虚拟机搭建Hadoop HA集群(1)
系列博客目录链接:Hadoop权威指南学习笔记:总章
基础环境搭建:使用3台虚拟机搭建Hadoop HA集群(1)
HA环境搭建:使用3台虚拟机搭建Hadoop HA集群(2)
工欲善其事,必先利其器,要学好大数据,就必须首先学会自己动手搭建Hadoop集群。本文章仅介绍搭建方法,因为资源有限,有些部署策略可能不适合实际应用。
本节包含如下内容
- 集群架构设计
- 配置DNS环境
- 搭建DNS服务器
- 配置集群间免密
- 配置Java环境
- 配置时间同步服务
- 修改文件最大打开数
一. 计划
由于手头只有一台笔记本,因此选择在一台笔记本上搭建三台虚拟机来模拟集群。
1. 节点资源分配
| IP | Hostname | 系统环境 | username | 内存 | 储存 | CPU核数 |
|---|---|---|---|---|---|---|
| 192.168.46.128 | cloud1 | ubuntu 16.04 | hadoop | 1GB | 50GB | 1 |
| 192.168.46.129 | cloud2 | ubuntu 16.04 | hadoop | 1GB | 50GB | 1 |
| 192.168.46.130 | cloud3 | ubuntu 16.04 | hadoop | 1GB | 50GB | 1 |
2. 集群架构
| IP | zkfc | zookeeper | Namenode | DataNode | journalNode | ResourceManager | NodeManager | DNS服务器 | DNS域名 | NTP |
|---|---|---|---|---|---|---|---|---|---|---|
| 192.168.46.128 | √ | √ | √ | × | √ | × | × | √ | a.cloud.ha | √ |
| 192.168.46.129 | √ | √ | √ | √ | √ | √ | √ | × | b.cloud.ha | × |
| 192.168.46.130 | × | √ | × | √ | √ | √ | √ | × | c.cloud.ha | × |
注意:
- 按照Hadoop高可用原理,NameNode和RM都建议配为一主一备。
- 本集群基于域名解析,如果不想配置域名服务,也可直接使用IP地址映射。后者缺点是后期更换机器时比较麻烦,需要修改所有节点hosts文件,而域名解析仅需修改域名服务器配置即可
- 一般情况下DataNode与NodeManager部署在一起,尽量使“计算”靠近“数据”。
- 在HA集群中,Standby NameNode同时也完成了namespace的checkpoint工作,所以不需要在运行Secondary NameNode, CheckpointNode, or BackupNode。实际上如果你运行这些服务的话会出错。
- zkfc负责主从切换,journalNode负责存储元数据。
- NTP指时间同步服务器的位置。
二. 搭建基础环境
搭建基础环境包含配置DNS环境、搭建DNS服务、配置免密、配置JAVA环境四部分。除搭建DNS服务操作仅需要在cloud1节点上操作外,其余三部分皆需要在所有节点操作。
1. 配置DNS环境
操作节点:cloud1、cloud2、cloud3
该部分包含配置节点静态IP、DNS IP。请将eth0替换为您所在主机的网卡名。注意,不要在该文件中的网关、静态IP、DNS相关配置项后增加注释,否则会导致网卡启动失败或DNS域名解析出现问题。
vim /etc/network/interfaces
修改文件如下,请将address 后的地址改为指定节点对应的IP。由于将要cloud1节点搭建DNS服务,在DNS服务器搭建完成之前配置未知的DNS服务器会导致无法上网,因此在下面的配置行中,我们需要把cloud1节点的最后两行注释掉,待DNS可用后再打开注释。
auto eth0
iface eth0 inet static
address 192.168.46.128
netmask 255.255.255.0
gateway 192.168.46.2
# dns-* options are implemented by the resolvconf package, if instatlled
dns-nameservers 192.168.46.128
dns-search pcat
编辑完成后,重启网卡并关闭防火墙:
sudo /etc/init.d/networking restart
sudo ufw disable
如果重启后发现网卡IP没有改变,请注意使用Ubuntu桌面删除系统原有配置。删除方法如图:
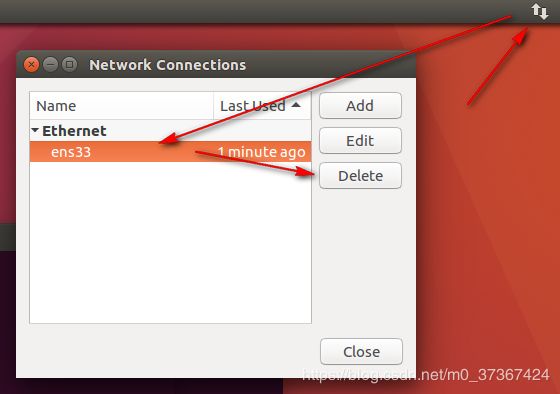
删除后重启服务即可。
附:vmvare虚拟机查看网关、IP地址范围方法如图:

查看子网范围:

查看网关:

2. 搭建DNS服务
操作节点:cloud1
a. 下载DNS服务软件:bind9。如果遇到依赖问题,可选择更换阿里源。
sudo apt update
sudo apt install bind9 bind9utils bind9-doc
b. 配置local文件
编辑named.conf.local文件
sudo vim /etc/bind/named.conf.local
写入如下:
zone "cloud.ha" {
type master;
file "/var/cache/bind/db.cloud.ha.zone";
};
其中zone后的“cloud.ha”为域名,type表示注DNS服务器。file指向区域配置文件位置(文件名及路径自定义)。
c. 配置conf文件
编辑named.conf.options文件。在options内,directory表示区域文件存放位置,一般为local文件的上一级目录;forwarders表示继承的dns,当你的dns未找到域名后,会使用该选项所指向的DNS地址。以下代码中dns为阿里云DNS。
sudo vim /etc/bind/named.conf.options
请参照修改为如下内容
options {
// change -edit-
directory "/var/cache/bind";
// change++
forwarders {
223.5.5.5;
223.6.6.6;
};
// change ++
allow-query-cache { any; };
// change -edit-
dnssec-enable no;
dnssec-validation no;
auth-nxdomain no; # conform to RFC1035
listen-on-v6 { any; };
};
d. 创建区域文件
区域文件存放位置与我们local中指定的文件对应,本例为/var/cache/bind/db.cloud.ha.zone。
sudo vim /var/cache/bind/db.cloud.ha.zone
填入如下内容:
$TTL 1D
@ IN SOA ns.cloud.ha. 1594287557.qq.com. (200 1H 15M 1W 1D )
@ IN NS ns.cloud.ha.
ns.cloud.ha. IN A 192.168.46.128
a IN A 192.168.46.128
b IN A 192.168.46.129
c IN A 192.168.46.130
简单介绍以下配置文件中的相关参数含义:
- SOA表示起始授权机构。在指令
@ IN SOA ns.cloud.ha. 1594287557.qq.com.中,指定了负责解析cloud.ha域(由local文件定义,@表示引用)的授权主机名是ns.cloud.ha.,授权主机名称将在区域文件中解析为IP地址,1594287557.qq.com.表示负责该区域的管理员的E-mail地址,文件中不允许使用@符号,因此使用.表示@。 @ IN NS ns.cloud.ha.是一条NS(Name Server)资源记录,定义了域cloud.ha由DNS服务器ns.cloud.ha.负责解析,NS资源记录定义的服务器称为区域权威名称服务器。权威名称服务器负责维护和管理所管辖区域中的数据,被其他服务器或客户端当作权威的来源,并且能肯定应答区域内所含名称的查询。这里的配置要求和SOA记录配置一致。- A定义了域名到IP地址的映射。在上面的例子中,使用了两种方式来定义A资源记录,一种是使用相对名称,即在名称的末尾没有加".",另外一种是使用完全规范域名FQDN(Fully Qualified Domain Name),即名称的最后以".“结束。对于相对名称a, b等,Bind会自动在相对名称的后面加上后缀”.cloud.ha."。
e. 检查配置文件及区域文件合法性
named-checkconf;named-checkzone cloud.ha /var/cache/bind/db.cloud.ha.zone
结果如图表示校验完成:

然后打开/etc/network/interfaces中的如下注释(删除前面的#)
# dns-nameservers 192.168.46.128
# dns-search pcat
打开注释后重启节点
sudo reboot
重启完成后,查看DNS服务器配置如图:
cat /etc/resolv.conf

重启bind9服务并设为开机自启服务
sudo systemctl restart bind9;sudo systemctl enable bind9
然后运行下面命令,结果如图即表示DNS服务搭建成功
nslookup c.cloud.ha
ping a.cloud.ha

至此,DNS搭建完成。关于区DNS相关的更详细的资料见:
- DNS BIND之区域数据文件
- 常用域名记录解释:A记录、MX记录、CNAME记录、TXT记录、AAAA记录、NS记录
- DNS解析过程
3. 搭建免密
操作节点:cloud1,cloud2,cloud3
以下以cloud1为例,其余两台参考此节点进行操作。进行此步骤之前,需保证节点已经安装openssh服务,如果未安装,执行sudo apt install ssh
a. 创建空密码的秘钥
执行以下命令后一路回车即可
ssh-keygen -t rsa
b. 去掉初始询问
vim /etc/ssh/ssh_config
找到StrictHostKeyChecking更改为no
# StrictHostKeyChecking ask
StrictHostKeyChecking no
c. 添加至cloud1、cloud2、cloud3节点
ssh-copy-id a.cloud.ha;ssh-copy-id b.cloud.ha;ssh-copy-id c.cloud.ha
其他节点同此操作。完成后即完成免密操作。测试时ssh到任何主机不需要输入密码即表示集群间免密成功。
4. 配置Jdk
操作节点:cloud1、cloud2、cloud3
本次以cloud1为例,其他节点参考操作。
a. 将解压后的java文件夹移动到/user/java/下,如图
![]()
b. 创建链接文件
sudo ln -s jdk jdk jdk1.8.0_111
c. 配置java环境
sudo vim /etc/profile
文件末尾加入如下内容
export JAVA_HOME=/usr/java/jdk
export JRE_HOME=$JAVA_HOME/jre
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
加载环境变量
source /etc/profile
如下图即表示正确配置。
java -version
which java

三. 搭建NTP服务器(时间同步)
集群之间的时间同步是一个非常常见的问题,当然也十分重要,因此我们需要在cloud1上搭建一个NTP时间服务器,其余两个节点以此为一句进行同步。
1. 更改节点时区
操作节点:cloud1、cloud2、cloud3
由于我们的机器位于东八区,因此我们需要将机器所在时区改为上海时间Asia/Shanghai。(针对Ubuntu)
cp -f /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
2. 搭建时钟服务器
操作节点:cloud1
此时钟服务器用于给集群其他节点提供时间同步服务。下面介绍安装过程。
a. 安装ntp
sudo apt install ntp
b. 编辑配置文件/etc/ntp.conf。以下提出配置文件的全部内容,修改的部分在注释中说明。
# /etc/ntp.conf, configuration for ntpd; see ntp.conf(5) for help
driftfile /var/lib/ntp/ntp.drift
# Enable this if you want statistics to be logged.
#statsdir /var/log/ntpstats/
statistics loopstats peerstats clockstats
filegen loopstats file loopstats type day enable
filegen peerstats file peerstats type day enable
filegen clockstats file clockstats type day enable
# Specify one or more NTP servers.
# Use servers from the NTP Pool Project. Approved by Ubuntu Technical Board
# on 2011-02-08 (LP: #104525). See http://www.pool.ntp.org/join.html for
# more information.
# 注释掉该部分
# pool 0.ubuntu.pool.ntp.org iburst
# pool 1.ubuntu.pool.ntp.org iburst
# pool 2.ubuntu.pool.ntp.org iburst
# pool 3.ubuntu.pool.ntp.org iburst
# 注释掉该部分
# Use Ubuntu's ntp server as a fallback.
# pool ntp.ubuntu.com
# Access control configuration; see /usr/share/doc/ntp-doc/html/accopt.html for
# details. The web page
# might also be helpful.
#
# Note that "restrict" applies to both servers and clients, so a configuration
# that might be intended to block requests from certain clients could also end
# up blocking replies from your own upstream servers.
# 增加了该部分
restrict 127.0.0.1
# 增加了该部分
server 127.127.1.0
fudge 127.127.1.0 stratum 10
# 增加了该部分,使用了阿里云NTP服务
server ntp.aliyun.com iburst minpoll 4 maxpoll 10
restrict ntp.aliyun.com nomodify notrap nopeer noquery
# By default, exchange time with everybody, but don't allow configuration.
restrict -4 default kod notrap nomodify nopeer noquery limited
restrict -6 default kod notrap nomodify nopeer noquery limited
# 添加了客户端节点
restrict b.cloud.ha
restrict c.cloud.ha
# Local users may interrogate the ntp server more closely.
restrict 127.0.0.1
restrict ::1
# Needed for adding pool entries
restrict source notrap nomodify noquery
# Clients from this (example!) subnet have unlimited access, but only if
# cryptographically authenticated.
#restrict 192.168.123.0 mask 255.255.255.0 notrust
# If you want to provide time to your local subnet, change the next line.
# (Again, the address is an example only.)
#broadcast 192.168.123.255
# If you want to listen to time broadcasts on your local subnet, de-comment the
# next lines. Please do this only if you trust everybody on the network!
#disable auth
#broadcastclient
#Changes recquired to use pps synchonisation as explained in documentation:
#http://www.ntp.org/ntpfaq/NTP-s-config-adv.htm#AEN3918
#server 127.127.8.1 mode 135 prefer # Meinberg GPS167 with PPS
#fudge 127.127.8.1 time1 0.0042 # relative to PPS for my hardware
#server 127.127.22.1 # ATOM(PPS)
#fudge 127.127.22.1 flag3 1 # enable PPS API
详细参数解析见:https://www.cnblogs.com/276815076/p/6397994.html
c. 重启ntp服务
sudo systemctl restart ntp
d. 验证服务ntpq -p。如图表示正确

3. 设置客户端时间同步
操作节点:cloud2、cloud3
a. 安装ntp
sudo apt install ntp
b. 编辑/etc/ntp.conf,注释掉服务器配置中注释掉的部分,然后再文件中添加时间服务器地址。此处为a.cloud.ha
server a.cloud.ha
# 允许上游主动修改本地时间
restrict a.cloud.ha nomodify notrap noquer
c. 同步时间
sudo ntpdate -u a.cloud.ha
d. 启动ntp服务。
systemctl start ntpd
systemctl enable ntpd
至此,时间同步搭建完成。
4. 设置文件最大打开数
若不设置文件最大打开数,则可能会报Too many open files错误。修改方法如下
a. 修改/etc/security/limits.d/20-nproc.conf,将*那列后的1024修改为65535
[root@HDTEST01 ~]# cat /etc/security/limits.d/20-nproc.conf
# Default limit for number of user's processes to prevent
# accidental fork bombs.
# See rhbz #432903 for reasoning.
* soft nproc 65535
root soft nproc unlimited
b. 在/etc/security/limits.conf文件末尾添加最大打开文件数,记得把hadoop改为本次部署hadoop服务的用户。
[root@HDTEST01 ~]# tail /etc/security/limits.conf
#@faculty soft nproc 20
#@faculty hard nproc 50
#ftp hard nproc 0
#@student - maxlogins 4
# edit by zhaopy
hadoop soft nofile 65535
hadoop hard nofile 65535
c. 最后在/etc/profile末尾添加如下语句
# set ulimit
ulimit -n 65535
d. 注销终端重新登录hadoop用于查看最大打开文件数
[hadoop@HDTEST01-/hadoop]ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 127967
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 65535
pipe size (512 bytes, -p) 8
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 8192
cpu time (seconds, -t) unlimited
max user processes (-u) 65535
virtual memory (kbytes, -v) unlimited
file locks (-x) unlimited
四. 本节小结
本节主要进行了基础环境的部署,下一小节将部署hadoop相关组件。