基于深度学习的语音分类识别(附代码)
音频与我们生活有着十分联系。 我们的大脑不断处理和理解音频数据,并为您提供有关环境的信息。 一个简单的例子就是你每天与人交谈。 这个演讲被另一个人看出来进行讨论。 即使你认为自己处于一个安静的环境中,你也会听到更微妙的声音,比如树叶的沙沙声或雨水的飞溅。 这是您与音频连接的程度。所以你能以某种方式抓住你周围的音频,做一些有建设性的事情吗? 当然是! 有一些设备可以帮助您捕获这些声音并以计算机可读格式表示。 这些格式是:
-
wav(波形音频文件)格式
-
mp3(MPEG-1 Audio Layer 3)格式
-
WMA(Windows Media Audio)格式
音频处理的是目前深度学习应用做火热的方向之一,虽然我们讨论过音频数据可用于分析。 但是音频处理的潜在应用是什么? 在这里,我将列出其中的一些:
-
根据音频功能索引音乐集
-
推荐用于广播频道的音乐
-
相似性搜索音频文件(又名Shazam)
-
语音处理和合成 - 为会话代理生成人工语音
当我们对音频数据进行采样时,我们需要更多的数据点来表示整个数据,并且采样率应该尽可能高。另一方面,如果我们在频域中表示音频数据,则需要更少的计算空间。
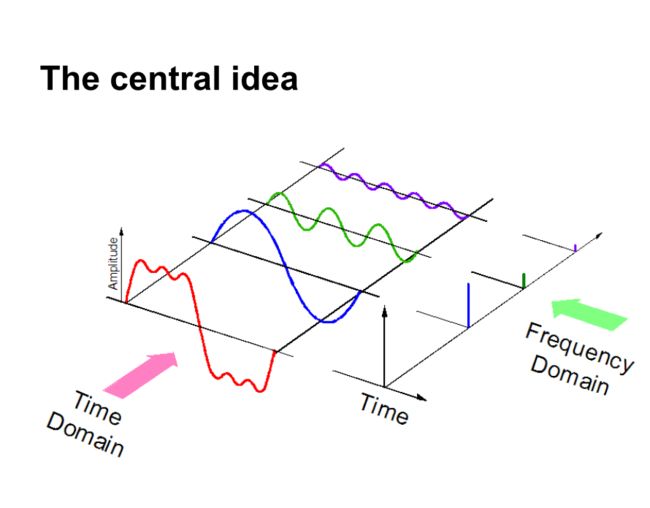
还有一些方法可以表示音频数据。 使用MFC(Mel-Frequency cepstrums.PS:我们将在后面的文章中介绍这一点)。 这些只是表示数据的不同方式。现在,下一步是从此音频表示中提取功能,以便我们的算法可以处理这些功能并执行其设计的任务,这是可以提取的音频功能类别的直观表示。

下面让我们实战UrbanSound数据集
让我们在现实生活项目Urban Music挑战中有一个更好的实用概述。 此练习题旨在向您介绍通过神经网络来解决通常的分类场景中的音频处理。该数据集包含来自10个类别的城市声音的8732个声音摘录(<= 4s),即:
-
冷气机
-
汽车喇叭
-
孩子声音
-
狗皮
-
钻孔
-
发动机怠速
-
枪击
-
手持式凿岩机
-
警笛
-
街头音乐
实验步骤
第1步:加载音频文件
第2步:从音频中提取功能
第3步:转换数据以在我们的深度学习模型中传递它
第4步:运行深度学习模型并获得结果
完整代码
% pylab inline
import os
import pandas as pd
import librosa
import glob
plt.figure(figsize=(12, 4))
librosa.display.waveplot(data, sr=sampling_rate)
i = random.choice(train.index)
audio_name = train.ID[i]
path = os.path.join(data_dir, 'Train', str(audio_name) + '.wav')
print('Class: ', train.Class[i])
x, sr = librosa.load('../data/Train/' + str(train.ID[i]) + '.wav')
plt.figure(figsize=(12, 4))
librosa.display.waveplot(x, sr=sr)
train.Class.value_counts()
test = pd.read_csv('../data/test.csv')
test['Class'] = 'jackhammer'
test.to_csv(‘sub01.csv’, index=False)
def parser(row):
# function to load files and extract features
file_name = os.path.join(os.path.abspath(data_dir), 'Train', str(row.ID) + '.wav')
# handle exception to check if there isn't a file which is corrupted
try:
# here kaiser_fast is a technique used for faster extraction
X, sample_rate = librosa.load(file_name, res_type='kaiser_fast')
# we extract mfcc feature from data
mfccs = np.mean(librosa.feature.mfcc(y=X, sr=sample_rate, n_mfcc=40).T,axis=0)
except Exception as e:
print("Error encountered while parsing file: ", file)
return None, None
feature = mfccs
label = row.Class
return [feature, label]
temp = train.apply(parser, axis=1)
temp.columns = ['feature', 'label']
from sklearn.preprocessing import LabelEncoder
X = np.array(temp.feature.tolist())
y = np.array(temp.label.tolist())
lb = LabelEncoder()
y = np_utils.to_categorical(lb.fit_transform(y))
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras.optimizers import Adam
from keras.utils import np_utils
from sklearn import metrics
num_labels = y.shape[1]
filter_size = 2
# build model
model = Sequential()
model.add(Dense(256, input_shape=(40,)))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(256))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(num_labels))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy', metrics=['accuracy'], optimizer='adam')
model.fit(X, y, batch_size=32, epochs=5, validation_data=(val_x, val_y))
实验结果
Train on 5435 samples, validate on 1359 samples
Epoch 1/10
5435/5435 [==============================] - 2s - loss: 12.0145 - acc: 0.1799 - val_loss: 8.3553 - val_acc: 0.2958
Epoch 2/10
5435/5435 [==============================] - 0s - loss: 7.6847 - acc: 0.2925 - val_loss: 2.1265 - val_acc: 0.5026
Epoch 3/10
5435/5435 [==============================] - 0s - loss: 2.5338 - acc: 0.3553 - val_loss: 1.7296 - val_acc: 0.5033
Epoch 4/10
5435/5435 [==============================] - 0s - loss: 1.8101 - acc: 0.4039 - val_loss: 1.4127 - val_acc: 0.6144
Epoch 5/10
5435/5435 [==============================] - 0s - loss: 1.5522 - acc: 0.4822 - val_loss: 1.2489 - val_acc: 0.6637
微信公众号:python语音识别
更多机器学习算法的学习欢迎关注我们。对机器学习感兴趣的同学欢迎大家转发&转载本公众号文章,让更多学习机器学习的伙伴加入公众号《python语音识别》,在实战中成长。同时欢迎在公众号内留言;
