关系抽取综述
1引言
关系抽取是信息抽取的重要子任务,其主要目的是将非结构化或半结构化描述的自然语言文本转化成结构化数据,关系抽取主要负责从文本中识别出实体,抽取实体间的语义关系。现有主流关系抽取技术分为有监督关系抽取,无监督关系抽取,和半监督关系抽取三种方法。这里,我们主要对有监督的关系抽取方法进行介绍。
有监督的学习方法将关系抽取任务当做分类问题,根据训练数据设计有效的特征,从而学习各种分类模型,然后使用训练好的分类器预测关系。有监督的学习方法是目前关系抽取较为主流也是表现最好的方法,但其最大的缺点就是需要大量的人工标注语料。如何获得大量的有标注语料就成为了我们工作的重点,远程监督方法就由此孕育而生。远程监督方法[1],将已有的知识库对应到丰富的非结构化数据中,从而生成大量的训练数据,从而训练关系抽取器。但是其也存在着非常明显的缺点:
1)生成大量的训练数据必然存在着准确率问题,如何解决错误训练数据的问题是我们工作的一个重点。
2)NLP工具带来的误差,比如NER,parsing等,越多的特征工程就会带来越多的误差,在整个任务的 pipeline 上会产生误差的传播和积累,从而影响后续关系抽取的精度。
2 attention
对于一个知识库难免会有一些错误的label,而使用远程监督方法扩充数据集更是会引入大量的噪声数据,我们使用attention机制就是来解决问题1中错误训练数据问题的。给定一个实体对和其对应的关系,传统的方法在无标签的语料集中提取所有包含该实体对的句子,并认为这样的句子中实体也存在同样的关系。很明显,这种方法会因为一些噪音语料而影响训练效果,所以引入attention机制[2],给不同的语料赋予不同的权重,尽量减轻错误label的负面影响,以此来提升分类器的性能。
这是未来我们工作中的一个改进点,目前我认为使用attention机制来减缓错误标签对分类器的影响是可行的。但是使用何种级别的attention机制,目前我还没有一个很明确的想法,将会再以后的工作中逐渐完善。
3 feature
关于问题2中特征工作的错误传播问题,用深度学习的思路来替代特征工程一个非常自然的想法,用word embedding 来表示句子中的 entity 和 word,用CNN或者是RNN对句子进行建模,将训练句子表示成一个 sentence vector,然后进行分类。
综上所述,我们的工作已经转变为一个关系分类问题了,在此任务中我们给定一个输入句子我们只需找出其所对应的关系类别就可以了,而不是对句子中的每一个词进行序列标注。因此我们所需要的是利用所有的局部信息去正确的预测出一个全局关系,所以我们在特征工作中选择卷积神经网络来对句子进行建模。
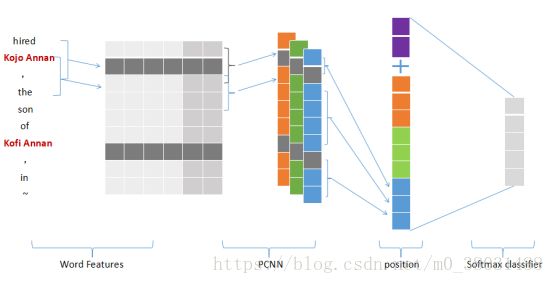
3.1 Word Features
分布式假设理论指出,一个词在相同的语境(上下文)中往往表达的是较为相似的含义。故我们在词的向量化表示中添加了上下文信息,例如我们有以下一
S : [People]0 have1 been2 moving3 back4 into5 [downtown]6
句话。正常情况下我们利用词嵌入技术将其表示为一组向量的集合形式,(x0, x1, · · · , x6)。但我们将上下文信息融入到词嵌入技术中[3],使得句子中第i个单词的向量化表示是由周围若干个词的特征融合而成的。其S就变成了{[xs, x0, x1], [x0, x1, x2], · · · , [x5, x6, xe]}。
3.2 PCNN
词嵌入技术已经能很好的表达词语之间的相关性。但是不能很好的捕捉远距离的词汇之间的关系,不能让计算机对于一个很长的句子表达有正确的理解。因此我们在句子级别的特征提取中使用卷积神经网络,希望能够结合所有的局部特征、提取句子中远距离的语法信息,最后生成我们的句子级别的特征向量。
传统卷积神经网络中我们对句子级别的特征向量进行卷积操作后直接对其进行最大池化操作,选取最大的值作为整个句子的特征提取。而McDonald 和Nivre(2007)指出关系类别预测的准确率随着句子长度的增加而出现了明显的下降,而根据Riedel的统计,我们常用于关系抽取方面的公开数据集中的句子有一多半是超出40词的长度的。这就说明我们只对卷积操作后的句子进行最大池化操作是不够的,换句话说,我们对一个句子只提取一个特征是不足以代表整个句子的。
所以学者提出了PCNN[4],即分段CNN(Piecewise Convolutional Neural Networks )。在PCNN中我们对卷积后的特征向量C进行分段,根据原始数据中实体1和实体2的位置我们将其分成三段,然后对每段分别进行最大池化操作,最后再对三段的特征数值进行维度相加,这样我们用三个数值来代表一个句子的向量化表示,来弥补句子太长对于关系分类的影响
3.3 position
通常,我们在进行关系分类时会再word embeding层面为其加上每个词的位置信息,我们这里所说的位置信息是指,句子中每个词语距离实体1和实体2的距离。而(Zeng et al. 2018)的工作中 [5],他们的模型中引入的位置信息不单单只是在word embeding层面,而是指在句子向量进行过卷积、池化操作后,再为句子向量级联上实体1和实体2的位置信息,其实验结果的提升很可能是来源于此。宏观上我们来看关系抽取,抽取的是一个句子中已经标注好的两实体之间的关系,所以两个实体所携带的任何信息都显得至关重要,故我们在池化层之后再对实体的位置信息进行倚重,应该对实验效果是有所提升的。
参考文献
[1] Mintz, Mike, et al. "Distant supervision for relation extraction without labeled data." Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2-Volume 2. Association for Computational Linguistics, 2009.
[2] Lin, Yankai, et al. "Neural relation extraction with selective attention over instances." Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). Vol. 1. 2016.
[3] Zeng, Daojian, et al. "Relation classification via convolutional deep neural network." Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers. 2014.
[4] Zeng, Daojian, et al. "Distant supervision for relation extraction via piecewise convolutional neural networks." Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. 2015.
[5] Zeng, Xiangrong,et al. "Large Scaled Relation Extraction with Reinforcement Learning." Relation 2 (2018): 3.