数据仓库(二)之维度建模篇
-
概述
维度建模是一种将数据结构化的逻辑设计方法,它将客观世界划分为度量和上下文。度量是常常是以数值形式出现,事实周围有上下文包围着,这种上下文被直观地分成独立的逻辑块,称之为维度。它与实体-关系建模有很大的区别,实体-关系建模是面向应用,遵循第三范式,以消除数据冗余为目标的设计技术。维度建模是面向分析,为了提高查询性能可以增加数据冗余,反规范化的设计技术。
-
维度建模优点
-
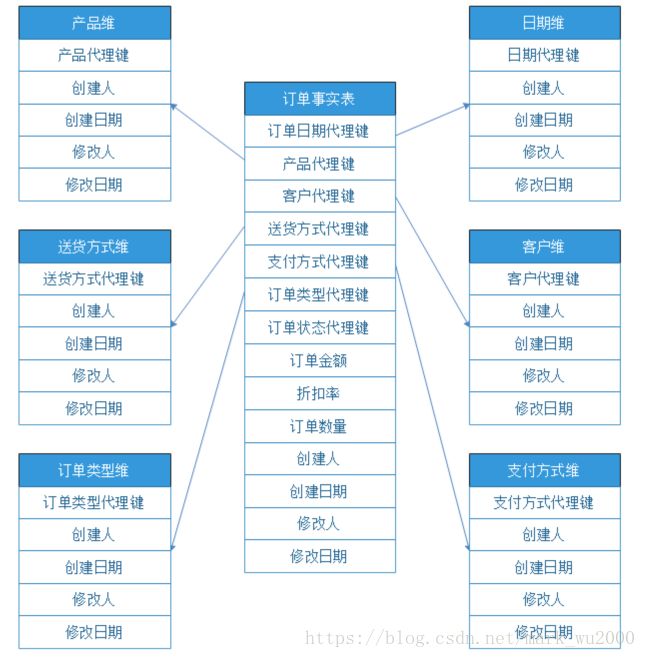
事实表
事实表存储了从业务活动或事件提炼出来的性能度量,它主要包含维度表的外键和连续变化的可加性数值或半可加事实。事实表产生于业务过程中而不是业务过程的描述性信息。它一般是行多列少,占了数据仓库的90%的空间。在维度模型中也有表示多对多关系的事实,其他都是维度表。
事实表粒度
事实表的粒度是产生事实行的度量事件的业务定义。粒度确定了事实表的业务主键, 事实表的所有度量值必须具有相同的粒度。
事实表类型
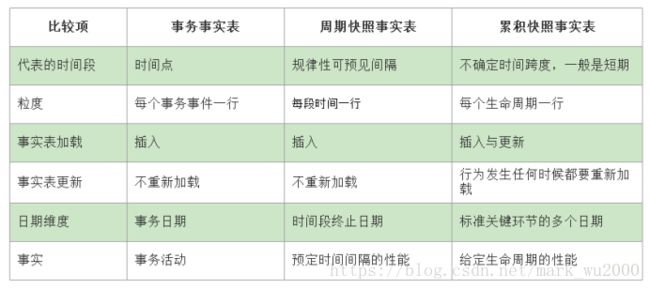
1.事务事实表
它是面向事务的,其粒度是每一行对应一个事务,它是最细粒度的事实表。
2.周期快照事实表
它是按照良好的时间周期间隔(每天,每月)来捕捉业务活动的执行情况,一旦装入事实表就不会再去更新,它是事务事实表的补充,而非替代品。
3.累积快照事实表
它用于描述业务过程中某个不确定时间跨度里的活动,它随着业务活动的发生会不断的更新。
事实表区别:
-
维度表
维度表是对业务过程的上下文描述,主要包含代理键、文本信息和离散的数字。它是进入事实表的入口,丰富的维度属性给出了对事实表的分析切割能力,它一般是行少列多。如果属性值是离散的,用于过滤和标记的,就放到维度表里,如果是属性值是连续取值,用于计算的,就放到事实表中。
维度表类型
缓慢变化维
1.类型1
字段值发生变化时覆盖原来的值。
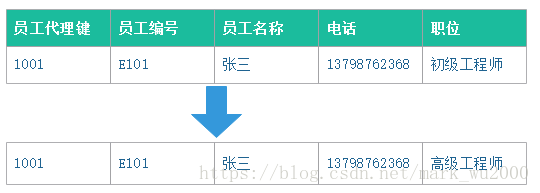
2.类型2
字段值发生变化时会新增一行,重新分配代理键,每一行添加开始日期,结束日期,版本号,是否当前值。

3.类型3
每条记录会新增一列来标识变化前的值,发生变化时,把旧值放到新增的列中,把新值覆盖旧值。

4.混合类型
把上面的三种类型混合来使用。
日期维
它是数据仓库必须有的维度,包含日期,日期所属的周,月,季度,年等信息。
角色维
相同的维度表在维度模型中扮演不中的逻辑角色,一般通过创建视图来表示。
杂项维
如果每个属性值都很少,可以把这些维度的组合起来生成一个维度表。

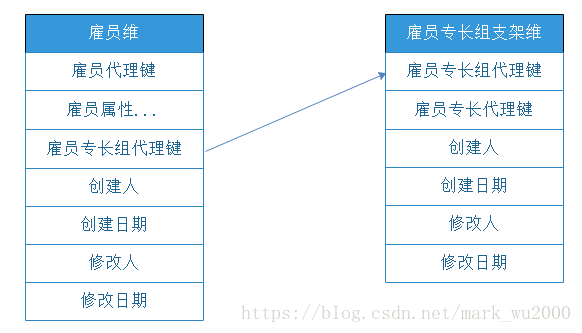
支架维
如果维度之间是一对多的关系或区别于原维度的多个描述性维度属性,可以建雪花型支架维度。
多值维度桥接维
如果二个维度表是多对多的关系,可以使用多值维度设计。

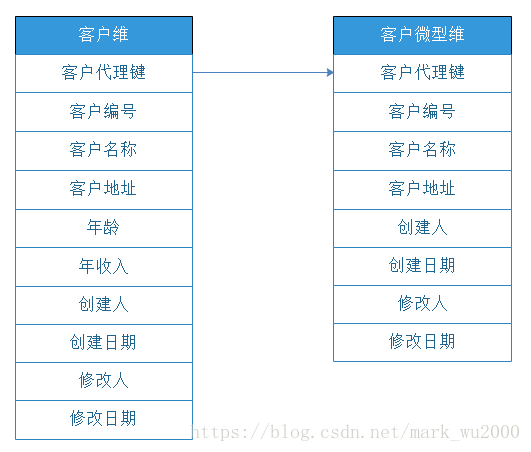
微型维
一个大型维有些属性变化比较频繁,把这些属性单独生成一个微型维度表。
缩小维
它是维度表的一个子集或部分属性。
查找维
系统里代码表里维度信息。
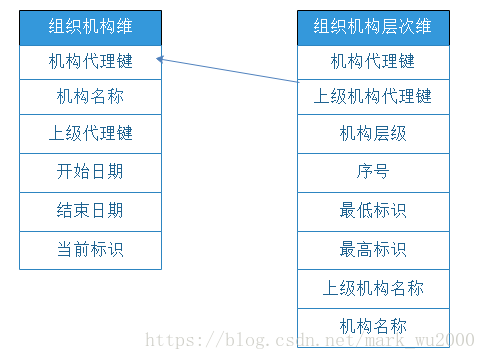
层次维
有些维度表是有层次结构的,可以通过视图生成树形结构的维度表。
手工维护的维表
有些数据不在业务系统里,需要业务用户手工维护的维度表。
-
企业数据仓库总线架构
企业价值链
每家机构都有一个关键业务过程组成的潜在价值链,这个价值链确定机构主体活动的自然逻辑流程。数据仓库建设就是围绕着价值链建立一致化的维度和事实。

数据总线
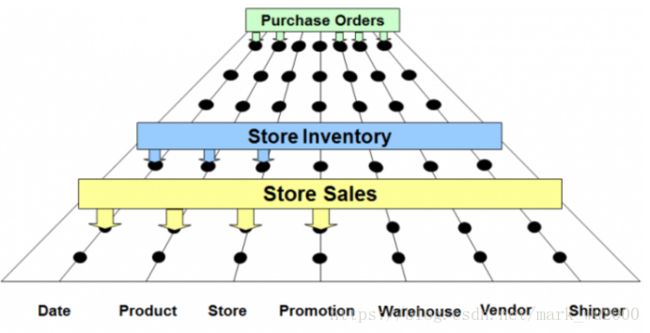
这些业务过程都会共用一些维度,形成了企业数据仓库的总线,一致化维度和事实看作一组标准的应用程序连接口,可以看作一个数据仓库的总线架构。它可以将新的业务过程引入数据仓库中,该业务过程从总线获得动力,并且和其他已经存在的业务过程和谐共存。
数据总线矩阵
矩阵的每一行对应都对应机构中的一个业务过程,每一列都和一个业务维度相对应,用叉号填充显示的是和每一行相关的列。业务过程应该先从单个数据源系统开始,然后再进行多数据源的合并。
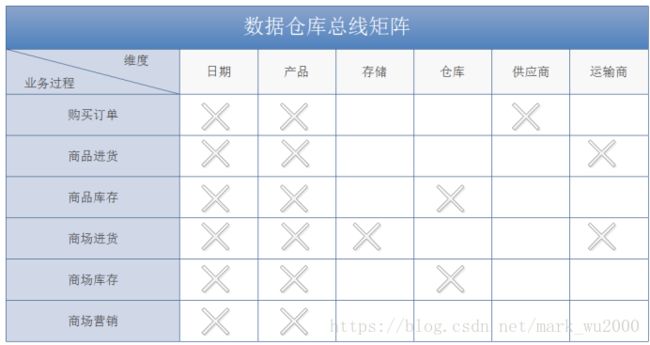
企业数据仓库总线矩阵是DW/BI系统的一个总体数据架构,提供了一种可用于分解企业数据仓库规划任务的合理方法,开发团队可以独立的,异步的完成矩阵的各个业务过程,迭代地去建立一个集成的企业数据仓库。
-
一致性维度和事实
企业数据仓库应该建立一个一致性维度和事实,而不是为每个部门建立维度和事实。
一致性维度
具有一致的维度关键字,一致的属性列名称,一致的属性定义和一致的属性值。一致性维度要么是统一的,要么是维度表的一个子集。
一致性事实
指每个度量在整个数据仓库中都是唯一的统计口径,为了避免歧义,一个度量只有唯一的业务术语。
-
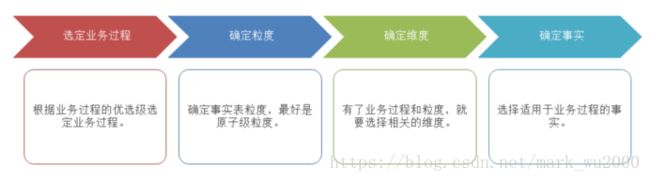
维度模型设计方法
-
维度模型设计流程图

-
维度模型设计步骤
1.需求调研
2.数据探查
根据总线矩阵,确定业务过程的优先级,就要对候选数据源进行可行性评估,产出文档有源系统跟踪报告,数据评估报告。主要内容有:

3.高层模型设计
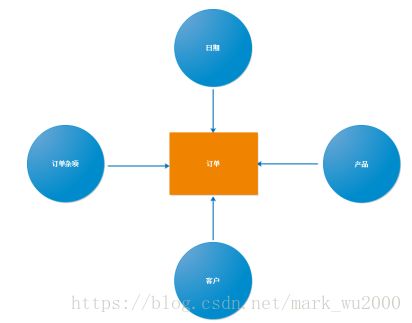
4.识别维度和度量
有了高层模型,就要设计维度和度量,维度和度量清单不仅仅是业务用户所关心,还要从业务过程出发,自上而下的设计所涉及的维度和度量。防止业务用户的需求变化带来的冲击。
5.确定命名规范
在详细设计之前,为DW/BI系统制定规范,主要包含源系统、主题、业务术语、报表,物理设计命名、调度任务、文档方面的规范。
6.编写详细设计映射文档
详细设计文档包括从源系统到维度模型的每个数据层的物理映射文档。
7.审查和验证模型
详细设计文档出来后,要和业务用户和团队成员进行评审,记录下来评审过程中的问题,形成问题清单。
8.完成设计文档
最后确定设计文档,进行下一步的ETL开发。