Keras卷积神经网络补充
1. keras.layers.Conv2D(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
- dilation_rate,空洞卷积或膨胀卷积的控制参数。
(1)参数初始化
参数初始化的目的是为了让神经网络在训练过程中学习到有用的信息,这意味着参数梯度不应该为0。则初始化的必要条件是:各层激活层不出现饱和现象;各层激活值不为0。
Xavier 初始化方法(又称作 Glorot 正态分布初始化),优秀的初始化应该使得各层的激活值和状态梯度的方差在传播过程中的方差保持一致。通过使用这种初始化方法,我们能够保证输入变量的变化尺度不变,从而避免变化尺度在最后一层网络中爆炸或者弥散。
2. 池化层
keras.layers.MaxPooling2D(pool_size=(2, 2), strides=None, padding='valid', data_format=None)
keras.layers.AveragePooling2D(pool_size=(2, 2), strides=None, padding='valid', data_format=None)
keras.layers.GlobalMaxPooling2D(data_format=None)
keras.layers.GlobalAveragePooling2D(data_format=None)
Global 系列的池化操作大多用于最后一层卷积层,可将每一个 feature_map 池化为一个特征,避免了全连接的参数增加,例如输入为 8*8*10 输出为 1*1*10
3. keras.layers.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
keras.layers.Flatten(data_format=None),将输入除了 batch 维展平为一维。
keras.layers.Dropout(rate, noise_shape=None, seed=None)
- rate,表示需要丢弃的比例。
keras.layers.SpatialDropout2D(rate, data_format=None),丢弃整个特征图。
4. 激活函数(大多两种表示方法,参数形式和层的形式),keras.layers.Activation(activation)
linear、Softmax、tanh、Sigmoid、hard_sigmoid、ReLU、ELU、SeLU、LeakyReLU、PReLU。
keras.layers.ReLU(max_value=None)
keras.layers.LeakyReLU(alpha=0.3)
keras.layers.PReLU(alpha_initializer='zeros', alpha_regularizer=None, alpha_constraint=None, shared_axes=None)
5. keras.layers.BatchNormalization(axis=-1, momentum=0.99, epsilon=0.001, center=True, scale=True, beta_initializer='zeros', gamma_initializer='ones', moving_mean_initializer='zeros', moving_variance_initializer='ones', beta_regularizer=None, gamma_regularizer=None, beta_constraint=None, gamma_constraint=None)
(1)Internal Covariate Shift 问题,指的是训练过程中隐层的输入分布不断变化问题。
(2)BatchNorm 就是在深度神经网络训练过程中使得每一层神经网络的输入保持相同分布的。
BN就是通过一定的规范化手段,把每层神经网络任意神经元这个输入值的分布强行拉回到均值为0方差为1的标准正态分布,其实就是把越来越偏的分布强制拉回比较标准的分布。这样使得激活输入值落在非线性函数对输入比较敏感的区域,避免梯度消失问题产生,而且梯度变大意味着学习收敛速度快,能大大加快训练速度。
BN是针对一个 Batch 进行的操作。
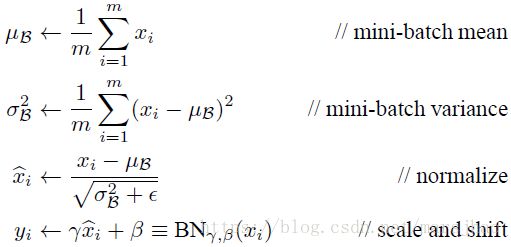

(3)BN层的作用,加速训练过程;控制过拟合(可移除 dropout和L2正则项);使得网络对初始化权重不敏感;允许使用较大的学习率。
(4)关于BN层的位置,论文中是 weights - batchnorm - activation 的顺序,认为这样可以利用好激活函数的有效区间。在激活层之前添加BN层,BN层可以将前一层的输出变换到更接近高斯分布,使得输入到激活层的值分布更加稳定。
对于将BN放置于激活函数之前还是之后,应当取决于不同的激活函数,对于上面讨论的,像 Sigmoid 和 tanh,BN放置于之前可以缓解梯度衰减。但对于 ReLU,倾向于将BN置于其后。若BN在ReLU之前,ReLU会截断BN输出后的数据。
6. ImageDataGenerator 类 https://keras.io/zh/preprocessing/image/
用以生成一个batch的图像数据,支持实时数据提升。训练时该函数会无限生成数据,直到达到规定的epoch次数为止。
(1)使用 .flow(x,y) 的例子
datagen = ImageDataGenerator()
datagen.fit(x_train) # 计算特征归一化所需的数量,如果应用 ZCA 白化,将计算标准差均值主成分
# 使用实时数据增益的批数据对模型进行拟合
model.fit_generator(datagen.flow(x_train, y_train, batch_size=32),
steps_per_epoch=len(x_train) / 32, epochs=epochs)
(2)使用 .flow_from_directory(directory) 的例子
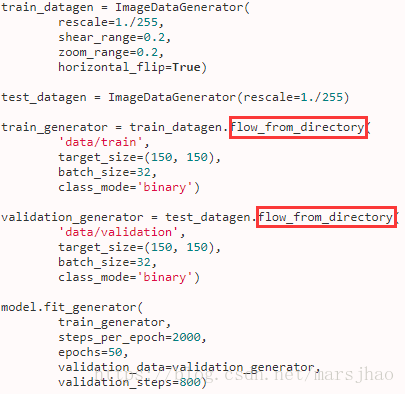
7. keras.applications https://keras.io/zh/applications/#applications
Keras 的应用模块(keras.applications)提供了带有预训练权值的深度学习模型,这些模型可以用来进行预测、特征提取和微调(fine-tuning)。
均可通过参数 include_top 控制是否需要全连接层,进而可直接输出 Bottleneck Features;亦可通过截取原始模型中的任意层来获取中间层特征输出,如:
base_model = VGG19(weights='imagenet')
model = Model(inputs=base_model.input, outputs=base_model.get_layer('block4_pool').output)