OpneCV3特征提取与目标检测之SURF算法(二)——使用SURF、SVM、BOW对图像进行分类
前言
1.按图像中的内容给图像分类是计算机视觉中比较适合初学者的项目,好多手机相册都有这一个功能,比如把美食归为一个标签,蓝天白云归为一个标签等等。还有我之前做过的车牌识别的项目都用到图像分类这个功能。
2.项目的环境:Winwods7 ,vs2015,OpenCV3.3加opencv_contrib库,boost库,实现语言是C++.
3.项目用到的知识点有OpenCV的SURF特征提取、BOW(Bag-of-words model-词袋模型),SVM分类器等,boost是用来操作文件。
4.项目的是功能是先对一些已经手动归类好的图像样本进行输入并训练,把训练好的结果保存,然后使用训练好的结果对未知的图像进行预测判断并分类,我使用的样本每个种类只有120张,特性提取的SURF的hessianThreshold取值从400到2000,准确率在70%到80%之间。
一.数据收集与处理
1.图像数据是从ZOL壁纸网站下载,里面有分类好的壁纸,可以整个系列下载。下载之后新建文件夹放同类型的图像,我收集了四个类型图像,新建一个data/train的文件夹,然后手工分类并放到相关的文件夹里再放到该目录下,每个种类收集了差不多120张图像。

2.图像不能太大,也不能太小,试过在训练集放了全是几M以上的图像,跑特征聚类时跑了一天没有跑出来,如果图像太小只有几B,到特征提取那里有可能会报错,认为是空的图像矩阵。从网上收集的图像太大可以编写python脚本把每个文件夹下的图像改成统一大小的像素的,该脚本把所有图像改成宽384和高256的图像。
resize.ipynb
from PIL import Image
import glob, os
w,h = 384,256 #更改成的分辨率
def timage():
for files in glob.glob('E:/caffe/5/*.jpg'): #原文件路径
filepath,filename = os.path.split(files)
filterame,exts = os.path.splitext(filename)
opfile = r'E:/caffe/data/5/' #保存的文件路径
if (os.path.isdir(opfile)==False):
os.mkdir(opfile)
im=Image.open(files)
im_ss=im.resize((int(w), int(h)))
try:
im_ss.save(opfile+filterame+'.jpg')
except:
print (filterame)
os.remove(opfile+filterame+'.jpg')
if __name__=='__main__':
timage()
3.在data目录再创建一个test的文件夹,用来放测试时用的图像,就是放训练种类相关的图像,图像大小随便,没有尺寸要求。

4.可以从这里下载我分好类的正样本和测试样本,下载地址:https://download.csdn.net/download/matt45m/11044699
二.项目流程与步骤
1.训练代码流程图

2.测试代码流程

三.代码示例
1.初始化与读取相关文件夹,如果第一次运行,创建要用到的文件夹,有放模板的文件夹、放测试训练结果的文件夹、放训练好的文件的文件夹。然后从训练集每个文件夹拿出一张图像放到模板文件夹里并按类型命名。
创建相关文件夹
/*创建相关文件夹*/
if (create_file)
{
fs::create_directory(temp_path);
fs::create_directory(result_path);
fs::create_directory(xml_path);
vector temp_name = getFileNameFromDir(TRAIN_FOLDER);
for (size_t i = 0; i < temp_name.size(); i++)
{
fs::path dir(temp_name.at(i));
fs::directory_iterator itEnd;
fs::directory_iterator itDir(dir);
int last_index = temp_name.at(i).find_last_of("\\");
string name = temp_name.at(i).substr(last_index + 1);
// 遍历路径下所有文件
for (; itDir != itEnd; itDir++)
{
string file_name = itDir->path().string();
// 判断文件是否是文件夹
fs::path file(file_name);
if (file.extension().string() == ".jpg")
{
fs::copy_file(file_name, temp_path + name + ".jpg");
fs::remove(file_name);
break;
}
}
}
}
3.遍历训练集文件夹下的所有图像文件,保存multimap容器。
(1).循环遍历train文件夹下的训练文件夹
fs::recursive_directory_iterator begin_iter(TRAIN_FOLDER);
fs::recursive_directory_iterator end_iter;
//递归迭代rescursive 直接定义两个迭代器:begin_iter为迭代起点(有参数),end_iter迭代终点
for (; begin_iter != end_iter; ++begin_iter)
{
string file_path = begin_iter->path().string();
fs::path file_name(file_path);
//判断是否为目录
if (fs::is_directory(file_name))
{
// 将类目名称设置为目录的名称
categor = file_name.filename().string();
category_name.push_back(categor);
}
else
{
string filename = string(TRAIN_FOLDER) + categor + string("/") + begin_iter->path().filename().string();
Mat temp = imread(filename, CV_LOAD_IMAGE_GRAYSCALE);
string name = begin_iter->path().filename().string();
if (temp.empty())
{
continue;
}
pair p(categor, temp);
std::cout << "开始读取训练集" << categor << "下的" << name << std::endl;
//加到multimap,键名可重复出现
train_set.insert(p);
}
}
(2)multimap的存储方式如下图:

4.提取训练集里每张图像的特征点,得出BOW词典,并保存BOW文件。
// 对于每一幅模板,提取SURF算子,存入到vocab_descriptors中
multimap ::iterator i = train_set.begin();
for (; i != train_set.end(); i++)
{
vectorkeypoints;
Mat temp = (*i).second;
Mat descrip;
//detect函数检测SURF/SIFT特征的关键点,并保存在vector容器中,最后使用drawKeypoints函数绘制出特征点。
feature_decter->detect(temp, keypoints);
//用视觉词典计算图像特征描述子
descriptor_extractor->compute(temp, keypoints, descrip);
//把特征点加到矩阵
vocab_descriptors.push_back(descrip);
}
5.构造与保存BOW文件。
// 对于每一幅模板,提取SURF算子,存入到vocab_descriptors中
multimap ::iterator i = train_set.begin();
for (; i != train_set.end(); i++)
{
//定义关键点
vectorkey_point;
//从容器里读出文件绝对路径
string cate_name = (*i).first;
//从容器里读出图片
Mat temp_image = (*i).second;
Mat imageDescriptor;
//detect函数检测SURF/SIFT特征的关键点,并保存在vector容器中,最后使用drawKeypoints函数绘制出特征点。
feature_decter->detect(temp_image, key_point);
//用视觉词典计算图像特征描述子
bow_descriptor_extractor->compute(temp_image, key_point, imageDescriptor);
//push_back(Mat);在原来的Mat的最后一行后再加几行,元素为Mat时, 其类型和列的数目 必须和矩阵容器是相同的
allsamples_bow[cate_name].push_back(imageDescriptor);
}
6.训练分类器并保存训练好的文件,训练完成。
for (int i = 0; i < categories_size; i++)
{
//在创建对象同时,提供矩阵行数、列数、存储类型
Mat tem_Samples(0, allsamples_bow.at(category_name[i]).cols,allsamples_bow.at(category_name[i]).type());
//新行一个0行一列的矩阵
Mat responses(0, 1, CV_32SC1);
//把上面包含特征点的矩阵加到新建的矩阵后面
tem_Samples.push_back(allsamples_bow.at(category_name[i]));
//新建一个跟特征模板行数一样,1列,并全部初始化为1的矩阵
Mat posResponses(allsamples_bow.at(category_name[i]).rows, 1, CV_32SC1, Scalar::all(1));
//把数据压入矩阵
responses.push_back(posResponses);
//遍历容器
for (auto itr = allsamples_bow.begin(); itr != allsamples_bow.end(); ++itr)
{
if (itr->first == category_name[i])
{
continue;
}
//压入数据
tem_Samples.push_back(itr->second);
Mat response(itr->second.rows, 1, CV_32SC1, Scalar::all(-1));
responses.push_back(response);
}
//samples是训练样本特征的矩阵,layout参数有ROW_SAMPLE和COL_SMAPLE两个选择,
//说明了样本矩阵中一行还是一列代表一个样本,response矩阵和samples矩阵相对应,说明了样本的标记
Ptr t_tdata = TrainData::create(tem_Samples,ROW_SAMPLE, responses);
//开始训练
stor_svms.at(i)->train(t_tdata);
//存储svm
string svm_filename = xml_path + category_name[i] + string("SVM.xml");
stor_svms.at(i)->save(svm_filename.c_str());
}
四、测试
1.测试代码
for (int i = 0; i st_svm = Algorithm::load(svm_path.c_str());
if (sign == 0)
{
float score_Value = st_svm->predict(test, noArray(), true);
float class_Value = st_svm->predict(test, noArray(), false);
sign = (score_Value < 0.0f) == (class_Value < 0.0f) ? 1 : -1;
}
cur_confidence = sign * st_svm->predict(test, noArray(), true);
}
else
{
if (sign == 0)
{
float scoreValue = stor_svms[i]->predict(test, noArray(), true);
float classValue = stor_svms[i]->predict(test, noArray(), false);
sign = (scoreValue < 0.0f) == (classValue < 0.0f) ? 1 : -1;
}
cur_confidence = sign * stor_svms[i]->predict(test, noArray(), true);
}
if (cur_confidence>best_score)
{
best_score = cur_confidence;
prediction_category = class_name;
}
}
2.测试结果
卡通这个类别的,可以看到有几张是错误的。

花这个类别的,也有几张误判的:

结语:
1.同样的数据,使用opencv进行预测时,所有的时间和准确率和caffe训练成模型之后调用,完全不是一个级别的,caffe的模型预测速度比opencv这个项目要快差不多3倍。
caffe预测一张图像所花的时间:

SVM分类预测一张图像所花的时间:
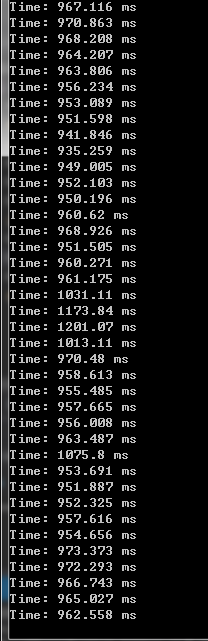
2.准确率也不一样,如果样本数量少,caffe还可使用迁移学习来提高准确率,caffe预测能达到97%上,但SVM分类器只能达到80%左右,也许是代码优化的问题吧。
3.关于工程的源码,运行程序时的bug,都可以加这个群(487350510)互相讨论学习。