基于keras的resnet的详细解析
转载链接:https://blog.csdn.net/qq_25491201/article/details/78405549
前言:
yolo3里面涉及到了shortcut的概念,最初提出这个概念的是15年resnet,本篇主要介绍shortcut以及resnet的keras的实现
ResNet网络详解与keras实现
- ResNet网络详解与keras实现
-
- Resnet网络的概览
- Pascal_VOC数据集
- 第一层目录
- 第二层目录
- 第三层目录
- 梯度退化
- Residual Learning
- Identity vs Projection Shortcuts
- Bottleneck architecture
- Resnet网络构建表
- ResNet论文结果
- 为了搭建Resnet网络我们使用了以下策略
- 整个代码的流程如下
- 实验结果
- 实验结果分析
- 本博客相关引用
-
本博客旨在给经典的ResNet网络进行详解与代码实现,如有不足或者其他的见解,请在本博客下面留言。
Resnet网络的概览
- 为了解决训练很深的网络时候出现的梯度退化(gradient degradation)的问题,Kaiming He提出了Resnet结构。由于使用了残差学习的方法(Resuidal learning),使得网络的层数得到了大大的提升。
- ResNet由于使用了shortcut,把原来需要学习逼近的未知函数H(x)恒等映射(Identity mapping),变成了逼近F(x)=H(x)-x的一个函数。作者认为这两种表达的效果相同,但是优化的难度却并不相同,作者假设F(x)的优化会比H(x)简单的多。这一想法也是源于图像处理中的残差向量编码,通过一个reformulation,将一个问题分解成多个尺度直接的残差问题,能够很好的起到优化训练的效果。
- ResNet针对较深(层数大于等于50)的网络提出了BottleNeck的结构,这个结构可以减少运算的时间复杂度。
- ResNet里存在两种shortcut,Identity shortcut & Projection shortcut。Identity shortcut使用零填充的方式保证其纬度不变,而Projection shortcut则具有下面的形式y=F(x,Wi)+Wsx
- 来匹配纬度的变换。
- ResNet这个模型在图像处理的相关任务中具有很好的泛化性,在2015年的ImageNet Recognization,ImageNet detection,ImageNet localization,COCO detection,COCO segmentation等等任务上取得第一的成绩。
在本篇博客中,将对Resnet的结构进行详细的解释,并用代码实现ResNet的网络结构。同时,本文还将引入另一篇论文<>,来更加深入的理解Resnet。本文使用VOC2012的数据集进行网络的训练,验证,与测试。为了快速开发,本次我们把Keras作为代码的框架。
Pascal_VOC数据集
Pascal VOC为图像识别,检测与分割提供了一整套标准化的优秀的数据集,每一年都会举办一次图像识别竞赛。下面是VOC2012,训练集(包括验证集)的下载地址。
VOC2012里面有20类物体的图片,图片总共有1.7万张。我把数据集分成了3个部分,训练集,验证集,测试集,比例为8:1:1。
下面是部分截图:
第一层目录

第二层目录
第三层目录
接着我们使用keras代码来使用这个数据集,代码如下:
IM_WIDTH=224 #图片宽度
IM_HEIGHT=224 #图片高度
batch_size=32 #批的大小
# train data
train_datagen = ImageDataGenerator(
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
rescale=1./255
)
train_generator = train_datagen.flow_from_directory(
train_root,
target_size=(IM_WIDTH, IM_HEIGHT),
batch_size=batch_size,
shuffle=True
)
# vaild data
vaild_datagen = ImageDataGenerator(
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
rescale=1./255
)
vaild_generator = train_datagen.flow_from_directory(
vaildation_root,
target_size=(IM_WIDTH, IM_HEIGHT),
batch_size=batch_size,
)
# test data
test_datagen = ImageDataGenerator(
rescale=1./255
)
test_generator = train_datagen.flow_from_directory(
test_root,
target_size=(IM_WIDTH, IM_HEIGHT),
batch_size=batch_size,
)
我使用了3个ImageDataGenerator,分别来使用训练集,验证集与测试集的数据。使用ImageDataGenerator需要导入相应的模块,==from keras.preprocessing.image import ImageDataGenerator==。ImageDataGenrator可以用来做数据增强,提高模型的鲁棒性.它里面提供了许多变换,包括图片旋转,对称,平移等等操作。里面的flow_from_directory方法可以从相应的目录里面批量获取图片,这样就可以不用一次性读取所有图片(防止内存不足)。
梯度退化
按照我们的惯性思维,一个网络越深则这个网络就应该具有更好的学习能力,而梯度退化是指下面一种现象:随着网络层数的增加,网络的效果先是变好到饱和,然后立即下降的一个现象。在这里,我们引用一幅来自Resnet里面的图片,更加直观的理解这个现象: 
从上图我们可以看出,一个56层的网络的训练误差和测试误差都大于一个20层的网络。
Residual Learning
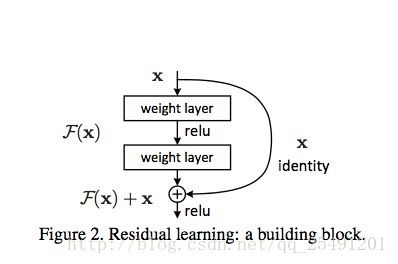
为了解决梯度退化的问题,论文中提出了Residual learning这个方法,它通过构造一个Residual block来完成。如图Figure 2所示,引入残差结构以后,把原来需要学习逼近的未知函数H(x)恒等映射(Identity mapping),变成了逼近F(x)=H(x)-x的一个函数。作者认为这两种表达的效果相同,但是优化的难度却并不相同,作者假设F(x)的优化会比H(x)简单的多。这一想法也是源于图像处理中的残差向量编码,通过一个reformulation,将一个问题分解成多个尺度直接的残差问题,能够很好的起到优化训练的效果。
上图的恒等映射,是把一个输入x和其堆叠了2次后的输出F(x)的进行元素级和作为总的输出。因此它没有增加网络的运算复杂度,而且这个操作很容易被现在的一些常用库执行(e.g.,Caffe,tensorflow)。
下面是一张没有使用普通图(plain,即没有加入恒等映射的图),与一张有shortcut图的对比: 
最左边的图为经典的VGG-19图的网络结构,中间的图是一个类似于VGG-19的34层的普通图,最右边的图是34层的带有恒等映射的Resnet网络图。其中黑色的实线代表的是同一纬度(即卷积核的个数相同)下的恒等映射。而虚线指的是不同维度间(卷积核的个数不同)的恒等映射。
Identity vs Projection Shortcuts
除了最简单的Identity shortcuts(直接进行同纬度的元素级相加),论文还研究了Projection shortcuts($ y=F(x,{W_i})+W_sx$).论文研究了以下3种情况:
i. 对于纬度没有变化的连接进行直接相连,对于纬度增加的连接则通过补零填充后进行连接。由于shortcuts是恒等的,因此这个连接本身不会带来额外的参数。
ii. 对于纬度没有变化的连接进行直接相连,对于纬度增加的连接则通过投影相连,投影相连会增加参数。
iii. 对于所有的连接都采取投影相连。
作者对以上三种情况都进行了研究,发现iii的效果比ii好一点点点(marginly better),发现ii的效果比i的效果好一点。这是因为$W_s$中带来的额外参数所带来的效果。
Bottleneck architecture
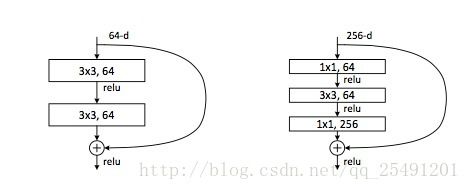
如上图右边所示,作者在研究更深层次(层数大于50)的网络的时候,使用了Bottleneck这个网络结构。我觉得作者可能是参考了goolenet里面的Inception结构。我们可以看到在Bottleneck中,第一个1x1的卷积层用来在降低纬度(用来降低运算复杂度),而后一个的1x1的卷积层则用来增加纬度,使其保持与原来的输入具有相同的纬度。(从而可以进行恒等映射)。
Resnet网络构建表
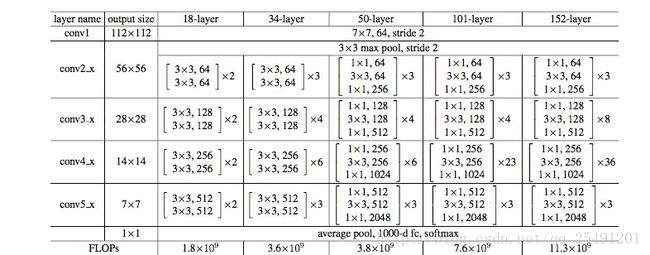
上图是一个Resnet的网络构建表,它显示了resnet是怎么构成的。同时这个表还提供了各个网络的运算浮点数,虽然resnet的层数比较深,但是它的运算量都小于VGG-19(19.6x10的9次方)。
ResNet论文结果:

上图左边是普通的网络,右边是残差网络,较细的线代表验证误差,较粗的线则代表训练误差。我们可以看到普通的网络存在梯度退化的现象,即34层网络的训练和验证误差都大于18层的网络,而残差网络中则不存在这个现象。可见残差网络解决了梯度退化的问题。
为了搭建Resnet网络,我们使用了以下策略:
- 使用identity_block这个函数来搭建Resnet34,使用bottleneck这个函数来搭建Resnet50。
- 每个卷积层后都使用BatchNormalization,来防止模型过拟合,并且使输出满足高斯分布。
- 具体网络搭建可以参考Tabel.1,可以边看表里面的具体参数边搭网络。
整个代码的流程如下:
graph TD
A(导入相应库) --> Z[模型参数设置以及其它配置]
Z --> B[生成训练集,测试集,验证集的三个迭代器]
B --> C[identity_block函数的编写]
C --> D[bottleneck_block函数的编写]
D --> F[根据resnet网络构建表来构建网络]
F --> G[模型训练与验证]
G --> H[模型保存]
H --> I(模型在测试集上测试)
# coding=utf-8
from keras.models import Model
from keras.layers import Input, Dense, Dropout, BatchNormalization, Conv2D, MaxPooling2D, AveragePooling2D, concatenate, \
Activation, ZeroPadding2D
from keras.layers import add, Flatten
from keras.utils import plot_model
from keras.metrics import top_k_categorical_accuracy
from keras.preprocessing.image import ImageDataGenerator
from keras.models import load_model
import os
# Global Constants
NB_CLASS=20
IM_WIDTH=224
IM_HEIGHT=224
train_root='/home/faith/keras/dataset/traindata/'
vaildation_root='/home/faith/keras/dataset/vaildationdata/'
test_root='/home/faith/keras/dataset/testdata/'
batch_size=32
EPOCH=60
# train data
train_datagen = ImageDataGenerator(
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
rescale=1./255
)
train_generator = train_datagen.flow_from_directory(
train_root,
target_size=(IM_WIDTH, IM_HEIGHT),
batch_size=batch_size,
shuffle=True
)
# vaild data
vaild_datagen = ImageDataGenerator(
width_shift_range=0.1,
height_shift_range=0.1,
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
rescale=1./255
)
vaild_generator = train_datagen.flow_from_directory(
vaildation_root,
target_size=(IM_WIDTH, IM_HEIGHT),
batch_size=batch_size,
)
# test data
test_datagen = ImageDataGenerator(
rescale=1./255
)
test_generator = train_datagen.flow_from_directory(
test_root,
target_size=(IM_WIDTH, IM_HEIGHT),
batch_size=batch_size,
)
def Conv2d_BN(x, nb_filter, kernel_size, strides=(1, 1), padding='same', name=None):
if name is not None:
bn_name = name + '_bn'
conv_name = name + '_conv'
else:
bn_name = None
conv_name = None
x = Conv2D(nb_filter, kernel_size, padding=padding, strides=strides, activation='relu', name=conv_name)(x)
x = BatchNormalization(axis=3, name=bn_name)(x)
return x
#对于identity_Block的nb_filter以及bottleneck_Block的nb_filters进行说明:如上图所示:resNet34里面,每一个卷积层当中的nb_filter仅仅是一种,而resnet50里面每一层的filter有多种
def identity_Block(inpt, nb_filter, kernel_size, strides=(1, 1), with_conv_shortcut=False):
x = Conv2d_BN(inpt, nb_filter=nb_filter, kernel_size=kernel_size, strides=strides, padding='same')
x = Conv2d_BN(x, nb_filter=nb_filter, kernel_size=kernel_size, padding='same')
if with_conv_shortcut:#shortcut的含义是:将输入层x与最后的输出层y进行连接,如上图所示
shortcut = Conv2d_BN(inpt, nb_filter=nb_filter, strides=strides, kernel_size=kernel_size)
x = add([x, shortcut])
return x
else:
x = add([x, inpt])
return x
def bottleneck_Block(inpt,nb_filters,strides=(1,1),with_conv_shortcut=False):
k1,k2,k3=nb_filters
x = Conv2d_BN(inpt, nb_filter=k1, kernel_size=1, strides=strides, padding='same')
x = Conv2d_BN(x, nb_filter=k2, kernel_size=3, padding='same')
x = Conv2d_BN(x, nb_filter=k3, kernel_size=1, padding='same')
if with_conv_shortcut:
shortcut = Conv2d_BN(inpt, nb_filter=k3, strides=strides, kernel_size=1)
x = add([x, shortcut])
return x
else:
x = add([x, inpt])
return x
def resnet_34(width,height,channel,classes):
inpt = Input(shape=(width, height, channel))
x = ZeroPadding2D((3, 3))(inpt)
#conv1
x = Conv2d_BN(x, nb_filter=64, kernel_size=(7, 7), strides=(2, 2), padding='valid')
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same')(x)
#conv2_x
x = identity_Block(x, nb_filter=64, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=64, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=64, kernel_size=(3, 3))
#conv3_x
x = identity_Block(x, nb_filter=128, kernel_size=(3, 3), strides=(2, 2), with_conv_shortcut=True)
x = identity_Block(x, nb_filter=128, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=128, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=128, kernel_size=(3, 3))
#conv4_x
x = identity_Block(x, nb_filter=256, kernel_size=(3, 3), strides=(2, 2), with_conv_shortcut=True)
x = identity_Block(x, nb_filter=256, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=256, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=256, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=256, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=256, kernel_size=(3, 3))
#conv5_x
x = identity_Block(x, nb_filter=512, kernel_size=(3, 3), strides=(2, 2), with_conv_shortcut=True)
x = identity_Block(x, nb_filter=512, kernel_size=(3, 3))
x = identity_Block(x, nb_filter=512, kernel_size=(3, 3))
x = AveragePooling2D(pool_size=(7, 7))(x)
x = Flatten()(x)
x = Dense(classes, activation='softmax')(x)
model = Model(inputs=inpt, outputs=x)
return model
def resnet_50(width,height,channel,classes):
inpt = Input(shape=(width, height, channel))
x = ZeroPadding2D((3, 3))(inpt)
x = Conv2d_BN(x, nb_filter=64, kernel_size=(7, 7), strides=(2, 2), padding='valid')
x = MaxPooling2D(pool_size=(3, 3), strides=(2, 2), padding='same')(x)
#conv2_x
x = bottleneck_Block(x, nb_filters=[64,64,256],strides=(1,1),with_conv_shortcut=True)
x = bottleneck_Block(x, nb_filters=[64,64,256])
x = bottleneck_Block(x, nb_filters=[64,64,256])
#conv3_x
x = bottleneck_Block(x, nb_filters=[128, 128, 512],strides=(2,2),with_conv_shortcut=True)
x = bottleneck_Block(x, nb_filters=[128, 128, 512])
x = bottleneck_Block(x, nb_filters=[128, 128, 512])
x = bottleneck_Block(x, nb_filters=[128, 128, 512])
#conv4_x
x = bottleneck_Block(x, nb_filters=[256, 256, 1024],strides=(2,2),with_conv_shortcut=True)
x = bottleneck_Block(x, nb_filters=[256, 256, 1024])
x = bottleneck_Block(x, nb_filters=[256, 256, 1024])
x = bottleneck_Block(x, nb_filters=[256, 256, 1024])
x = bottleneck_Block(x, nb_filters=[256, 256, 1024])
x = bottleneck_Block(x, nb_filters=[256, 256, 1024])
#conv5_x
x = bottleneck_Block(x, nb_filters=[512, 512, 2048], strides=(2, 2), with_conv_shortcut=True)
x = bottleneck_Block(x, nb_filters=[512, 512, 2048])
x = bottleneck_Block(x, nb_filters=[512, 512, 2048])
x = AveragePooling2D(pool_size=(7, 7))(x)
x = Flatten()(x)
x = Dense(classes, activation='softmax')(x)
model = Model(inputs=inpt, outputs=x)
return model
def acc_top2(y_true, y_pred):
return top_k_categorical_accuracy(y_true, y_pred, k=2)
def check_print():
# Create a Keras Model
model = resnet_50(IM_WIDTH,IM_HEIGHT,3,NB_CLASS)
model.summary()
# Save a PNG of the Model Build
plot_model(model, to_file='resnet.png')
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['acc',top_k_categorical_accuracy])
print 'Model Compiled'
return model
if __name__ == '__main__':
if os.path.exists('resnet_50.h5'):
model=load_model('resnet_50.h5')
else:
model=check_print()
model.fit_generator(train_generator,validation_data=vaild_generator,epochs=EPOCH,steps_per_epoch=train_generator.n/batch_size
,validation_steps=vaild_generator.n/batch_size)
model.save('resnet_50.h5')
loss,acc,top_acc=model.evaluate_generator(test_generator, steps=test_generator.n / batch_size)
print 'Test result:loss:%f,acc:%f,top_acc:%f' % (loss, acc, top_acc)实验结果
| Data | Loss | Acc | Top5-acc |
|---|---|---|---|
| Training set | 1.85 | 39.9% | 85.3% |
| Vaildation set | 2.01 | 36.6% | 82.0% |
| Testing set | 2.08 | 35.7% | 78.1% |
| Dataset | VOC2012 | Classes | 20 |
| Model | ResNet | Framework | Keras |
实验结果分析
我们可以发现模型最后在测试集上的效果与训练集上的效果有一定程度上的差距,模型出现了一点过拟合。为了防止过拟合,而且为了加速收敛,本文在每一层之间都是用了BatchNormalization层。由于本文只训练了60个epoch,每个epoch差不多迭代500次,由于训练的次数太少,故效果并未具体显现。
本博客相关引用
以下是本博客的引用,再次本人对每个引用的作者表示感谢。读者如果对Resnet这个网络仍然存在一些疑虑,或者想要有更深的理解,可以参考以下的引用。
引用博客1
引用博客2
引用文献1:Deep Residual Learning for Image Recognition
引用文献2:Residual Networks are Exponential Ensembles of Relatively Shallow Networks