Ubuntu16.04上搭建Hadoop2.7.2的单机模式和伪分布式模式
hadoop的单机模式和伪分布式模式可以说是学习hadoop的入门搭建环境,主要通过简单环境的搭建,对hadoop的MapReduce和HDFS有一个基础的认识。为分布式集群的搭建和学习起到引领的作用。
对于搭建所需的平台和软件如下:Ubuntu16.04、Hadoop2.7.2、java、sshd。以上软件都是到目前为止最新的版本。以下由于只是单机学习的目的,不考虑系统使用上的安全性,因此直接使用root用户进行操作,不再新建用户。
一、安装
1、Ubuntu16.04安装:我们通常使用虚拟机安装linux系统,可以选择VMware或者virtualbox,通过个人使用后感觉virtualbox更轻量一些,同时汉化也比较好,个人偏爱virtualbox一些。Ubuntu系统可在官网自行下载。Ubuntu官网下载地址:http://www.ubuntu.com/download/desktop。具体安装不在详述。唯一要说明的就是在使用virtualbox安装linux系统后需要设置共享文件夹,最后需要执行命令mount -t vboxsf shared /mnt/shared,其中shared文件夹为你在windows系统下建立的需要与linux系统共享的文件夹,而/mnt/shared为linux系统下选定的可以挂载的目录。
2、java安装:Ubuntu16.04默认安装后并不安装java,由于hadoop是java语言写的,需要使用java的运行环境,因此必须要先安装java。在终端中使用"sudo su -"命令切换到root用户,再使用"apt-get install openjdk-9-jre-headless"安装最新的java包。
3、sshd安装:同样,Ubuntu16.04默认安装后并不安装sshd。使用命令"apt-get install openssh-server"安装。安装后使用"ps aux | grep sshd"命令查看sshd是否启动,如果有如下信息"root 7093 0.0 0.2 65612 6116 ? Ss 22:22 0:00/usr/sbin/sshd -D",表明sshd已启动,如果没有启动,则使用命令"/etc/init.d/ssh start"启动sshd进程。
4、hadoop安装:在hadoop官网:http://www.apache.org/dyn/closer.cgi/hadoop/common/选择最新版本的hadoop下载,截止到目前,最新稳定版本为Hadoop2.7.2。将下载的hadoop放到windows共享文件夹shared中,就可以在linux的/mnt/shared目录中看到hadoop了,使用命令"cp -a /mnt/shared/hadoop-2.7.2.tar.gz /home/manyu"将hadoop拷贝到目录/home/manyu下。通过"tar -xvzf hadoop-2.7.2.tar.gz"解压文件到当前目录。由于linux系统软件安装在/usr/local目录下,所以使用命令"mv hadoop-2.7.2 /usr/local"将hadoop移动到/usr/local目录下。后者直接在解压时指定解压的目录为/usr/local,命令如下"tar -xvzf hadoop-2.7.2.tar.gz -C /usr/local"。
二、配置
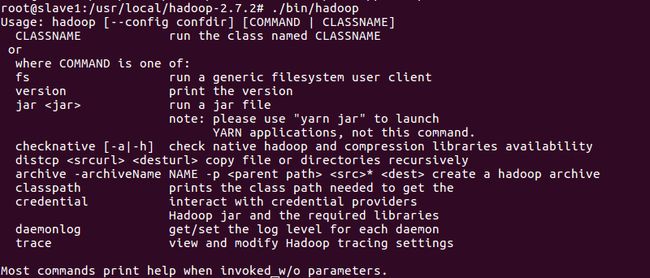
在安装完hadoop后使用命令"./bin/hadoop",会有如下提示,需要我们先配置JAVA_HOME。使用vim的话,请用"apt-get install vim"命令安装。
![]()
编辑文件"vim etc/hadoop/hadoop-env.sh"中定义的JAVA_HOME参数。首先通过命令"update-alternatives --config java"查看java的安装路径为/usr/lib/jvm/java-9-openjdk-amd64/bin/java。因此在配置文件中设置java安装的根目录如下:export JAVA_HOME=/usr/lib/jvm/java-9-openjdk-amd64。在使用命令"./bin/hadoop"后出现如下提示说明配置成功:
至此,前期准备已基本完成,下面我们先进行单机模式的测试,再进行伪分布式模式的配置测试。
1、单机模式
默认情况下,hadoop配置为运行在非分布式模式下的,作为一个单独的java进程。这对于调试是非常有用的。操作如下:
$ mkdir input
$ cd input
$ echo "hello world" > test1.txt
$ echo "hello hadoop" > test2.txt
$ cd ..
$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount input output
执行如上命令后如下所示:
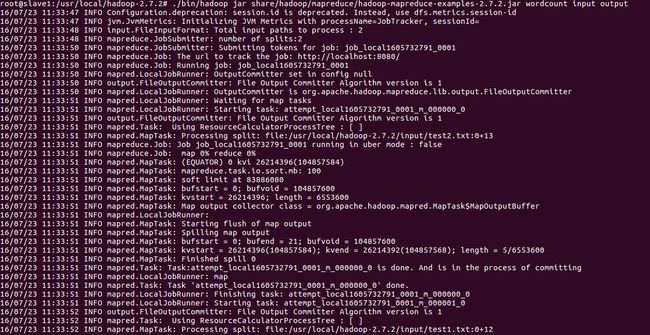
可以看到hadoop已经执行,执行结束后通过命令"cat output/*"查看结果如下:

可以看到执行结果是正确的。即有一个单词hadoop、一个单词world、两个单词hello。至此单机模式验证完毕。
2、伪分布式模式
hadoop可以在单节点上运行伪分布式模式,首先进行hadoop的配置文件的设置。
配置文件"etc/hadoop/core-site.xml":
配置文件"etc/hadoop/hdfs-site.xml":
接下来配置ssh:首先编辑"vim /etc/ssh/sshd_config",取消"AuthorizedKeysFile %h/.ssh/authorized_keys"选项的注释,如下图所示:

接下来设置自动登陆,操作如下:
$ ssh-keygen
之后一路回车使用系统提供的默认值即可。
$ cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
接下来通过"ssh localhost"命令验证登陆,第一次需要输入“yes”,之后就可以直接免密码登陆。如下图所示:
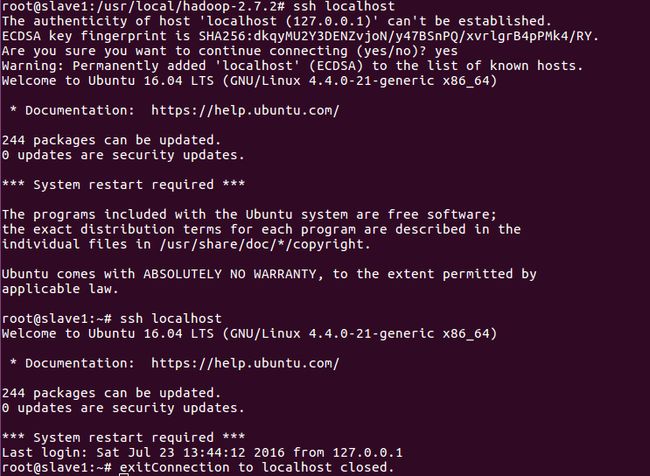
当输入"exit"时可退出登陆,如上图所示,显示"Connectino to localhost closed."
接下来在本地启动MapReduce任务。首先格式化文件系统
$ ./bin/hdfs namenode -format
看到如下标红的部分就表示格式化文件系统成功。

启动NameNode守护进程和DataNode守护进程。
$ ./sbin/start-dfs.sh
接下来使用jps命令来查看节点守护进程启动情况,当敲入jps后发现需要安装openjdk-8-jdk-headless和openjdk-9-jdk,因此我们使用apt-get安装这两个安装包。安装后:
$ jps

我们可以使用浏览器查看 NameNode节点,在浏览器中输入:http://localhost:50070/
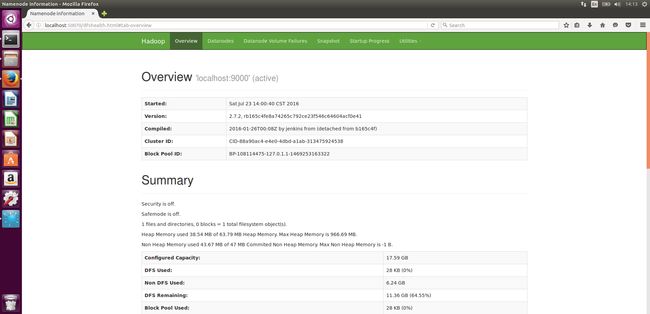
接下来创建hdfs文件系统的目录:
$ ./bin/hdfs dfs -mkdir /user
$ ./bin/hdfs dfs -mkdir /user/root
然后我们将之前input文件夹拷贝到hdfs文件系统中:
$ ./bin/hdfs dfs -put input /user/root
我们可以使用如下命令查看,是否将input文件夹拷贝到了hdfs文件系统中:
./bin/hdfs dfs -ls /user/root/input/*
以上操作如下图所示:

接下来让我们将当前文件系统中的input和output文件夹删除:
$ rm -rf input output
再运行hadoop命令:
$ ./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar wordcount input output
同样检查输出文件,将hdfs文件系统中的输出复制到本地文件系统,命令如下:
$ ./bin/hdfs dfs -get /user/root/output ouput
$ cat output/*
或者直接查看hdfs文件系统中的输出结果,而不用先复制到本地文件系统中,命令如下:
$ ./bin/hdfs dfs -cat output/*
可看到运行结果与之前单机模式时相同。当你做完测试,记得关闭服务,使用如下命令:
$ ./sbin/stop-dfs.sh
3总结
以上都是最简单的单机模式和伪分布式模式的配置,希望对大家有那么一点的帮助。
参考:http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/SingleCluster.html