VINS-Mono代码阅读笔记(六):vins_estimator中图像处理1
引言
VINS-Mono代码阅读笔记(四):vins_estimator中process线程代码分析 中讲process函数的时候,说到了一段设置重定位帧的代码,但是没有做分析,本篇笔记先把这部分代码进行梳理,接着分析图像处理这个重头戏的代码逻辑。
1.设置重定位帧
// set relocalization frame 设置重定位帧
sensor_msgs::PointCloudConstPtr relo_msg = NULL;
while (!relo_buf.empty())
{
relo_msg = relo_buf.front();
relo_buf.pop();
}
if (relo_msg != NULL)
{
vector match_points;
double frame_stamp = relo_msg->header.stamp.toSec();
//遍历relo_msg中的points特征点
for (unsigned int i = 0; i < relo_msg->points.size(); i++)
{
Vector3d u_v_id;
u_v_id.x() = relo_msg->points[i].x;
u_v_id.y() = relo_msg->points[i].y;
u_v_id.z() = relo_msg->points[i].z;
match_points.push_back(u_v_id);
}
//获取平移向量
Vector3d relo_t(relo_msg->channels[0].values[0], relo_msg->channels[0].values[1], relo_msg->channels[0].values[2]);
//获取旋转矩阵
Quaterniond relo_q(relo_msg->channels[0].values[3], relo_msg->channels[0].values[4], relo_msg->channels[0].values[5], relo_msg->channels[0].values[6]);
Matrix3d relo_r = relo_q.toRotationMatrix();
int frame_index;
//该relos中匹配的特征点所在的帧id
frame_index = relo_msg->channels[0].values[7];
//设置重定位帧
estimator.setReloFrame(frame_stamp, frame_index, match_points, relo_t, relo_r);
} relo_buf中存储收到的match_points消息,从relo_buf中取出relo_msg后,从relo_msg中解析出匹配的特征点对应的时间戳和特征点的坐标。同时,获取这些匹配的特征点所对应的图像帧的平移向量、旋转矩阵和图像帧index。然后调用setReloFrame,设置重定位帧。setReloFrame函数代码如下:
void Estimator::setReloFrame(double _frame_stamp, int _frame_index, vector &_match_points, Vector3d _relo_t, Matrix3d _relo_r)
{
//记录重定位帧的时间戳
relo_frame_stamp = _frame_stamp;
//记录重定位帧的index
relo_frame_index = _frame_index;
match_points.clear();
//匹配点
match_points = _match_points;
//平移向量和旋转矩阵记录
prev_relo_t = _relo_t;
prev_relo_r = _relo_r;
//遍历滑动窗口,将当前传入的重定位帧的时间戳和滑动窗口中的进行对比
for(int i = 0; i < WINDOW_SIZE; i++)
{
//时间戳进行比较
if(relo_frame_stamp == Headers[i].stamp.toSec())
{
relo_frame_local_index = i;
relocalization_info = 1;
//SIZE_POSE值为7,para_Pose为11*7的二维数组
for (int j = 0; j < SIZE_POSE; j++)
//把两个匹配的帧的位置和旋转四元数存储起来
relo_Pose[j] = para_Pose[i][j];
}
}
} 2.processImage函数调用前的工作
进行图像处理,其实“分析”的就是图像帧中能够检测到的每个特征点。vins_estimator中收到的是包含了检测出的图像特征点的message,然后从这个message中解析出每个特征点的属性:也就是特征点id、camera_id(哪个camera拍的)、该特征点在三维世界中的x,y,z坐标值、该特征点在二维图像帧中的像素坐标值u,v、该特征点在像素坐标上x,y方向上的速度。将这些属性组织起来按照特征点的id值为index存放在map类型的image变量中,然后调用processImage的时候将image作为参数传入。
TicToc t_s;
map>>> image;
//遍历img_msg中的特征点
for (unsigned int i = 0; i < img_msg->points.size(); i++)
{
int v = img_msg->channels[0].values[i] + 0.5;
int feature_id = v / NUM_OF_CAM;
int camera_id = v % NUM_OF_CAM;
//获取img_msg中第i个点的x,y,z坐标,这个是归一化后的坐标值
double x = img_msg->points[i].x;
double y = img_msg->points[i].y;
double z = img_msg->points[i].z;
//获取像素的坐标值
double p_u = img_msg->channels[1].values[i];
double p_v = img_msg->channels[2].values[i];
//获取像素点在x,y方向上的速度
double velocity_x = img_msg->channels[3].values[i];
double velocity_y = img_msg->channels[4].values[i];
ROS_ASSERT(z == 1);
Eigen::Matrix xyz_uv_velocity;
xyz_uv_velocity << x, y, z, p_u, p_v, velocity_x, velocity_y;
//建立每个特征点的image map,索引为feature_id
//image中每个特征点在帧中的位置信息和坐标轴上的速度信息按照feature_id为索引存入image中
image[feature_id].emplace_back(camera_id, xyz_uv_velocity);
}
//图像特征处理,包括初始化和非线性优化
estimator.processImage(image, img_msg->header); 3.processImage函数框架
先上一幅图看一下processImage中都做了哪些事情吧。

从这幅图中可以看到processImage的整体轮廓,一共做了下面四件事情:
1)视差检测。
2)外参初始化。
3)线性初始化。
4)非线性初始化。
本篇笔记先来分析一下视差检测部分的代码逻辑。
4.特征点加入和视差检测函数addFeatureCheckParallax
VINS中为了控制优化计算量,只对当前帧之前的某一部分帧进行优化,这里的一部分其实就是滑动窗口大小的关键帧数(系统中设置的值为10)。那么问题来了?当新的关键帧加入的时候,滑动窗口中的关键帧个数就会增加,为了保持窗口大小不变,就需要删除旧的帧后再添加新帧,这就是所谓的边缘化marginalization。那么,到底要删除哪个帧?是删除最旧的帧还是删除倒数第二帧,这就是addFeatureCheckParallax中需要判断的。
addFeatureCheckParallax代码如下:
/**
* 添加特征并检测视差
* 参考VINS 估计器之检查视差进行理解: https://www.cnblogs.com/easonslam/p/8872706.html
*/
bool FeatureManager::addFeatureCheckParallax(int frame_count, const map>>> &image, double td)
{
ROS_DEBUG("input feature: %d", (int)image.size());
ROS_DEBUG("num of feature: %d", getFeatureCount());
// 用于记录所有特征点的视差总和
double parallax_sum = 0;
// 记录满足某些条件的特征点个数
int parallax_num = 0;
// 被跟踪点的个数
last_track_num = 0;
//遍历图像image中所有的特征点,和已经记录了特征点的容器feature中进行比较
for (auto &id_pts : image)
{
//特征点管理器,存储特征点格式:首先按照特征点ID,一个一个存储,每个ID会包含其在不同帧上的位置
//这里id_pts.second[0].second获取的信息为:xyz_uv_velocity << x, y, z, p_u, p_v, velocity_x, velocity_y
FeaturePerFrame f_per_fra(id_pts.second[0].second, td);
//获取feature_id
int feature_id = id_pts.first;
//在feature中查找该feature_id的feature是否存在
auto it = find_if(feature.begin(), feature.end(), [feature_id](const FeaturePerId &it)
{
return it.feature_id == feature_id;
});
if (it == feature.end())
{
//没有找到该feature的id,则把特征点放入feature的list容器中
feature.push_back(FeaturePerId(feature_id, frame_count));
//feature是个list类型,里边每个元素类型为FeaturePerId,feature_per_frame表示每个FeaturePerId类型元素
feature.back().feature_per_frame.push_back(f_per_fra);
}
else if (it->feature_id == feature_id)
{
/**
* 如果找到了相同ID特征点,就在其FeaturePerFrame内增加此特征点在此帧的位置以及其他信息,
* it的feature_per_frame容器中存放的是该feature能够被哪些帧看到,存放的是在这些帧中该特征点的信息
* 所以,feature_per_frame.size的大小就表示有多少个帧可以看到该特征点
* */
it->feature_per_frame.push_back(f_per_fra);
//last_track_num,表示此帧有多少个和其他帧中相同的特征点能够被追踪到
last_track_num++;
}
}
//frame_count<2,也就是说加入到窗口中的帧个数取值为0或者1的时候
//last_track_num说明能够跟踪到的特征点数量少于20个
if (frame_count < 2 || last_track_num < 20)
return true;
//遍历每一个feature
for (auto &it_per_id : feature)
{
//计算能被当前帧和其前两帧共同看到的特征点视差
//it_per_id.feature_per_frame.size()表示该特征点能够被多少帧共视
if (it_per_id.start_frame <= frame_count - 2 &&
it_per_id.start_frame + int(it_per_id.feature_per_frame.size()) - 1 >= frame_count - 1)
{
//计算特征点it_per_id在倒数第二帧和倒数第三帧之间的视差,并求所有视差的累加和
parallax_sum += compensatedParallax2(it_per_id, frame_count);
parallax_num++;
}
}
if (parallax_num == 0)
{
return true;
}
else
{
ROS_DEBUG("parallax_sum: %lf, parallax_num: %d", parallax_sum, parallax_num);
ROS_DEBUG("current parallax: %lf", parallax_sum / parallax_num * FOCAL_LENGTH);
//视差总和除以参与计算视差的特征点个数,表示每个特征点的平均视差值
return parallax_sum / parallax_num >= MIN_PARALLAX;//MIN_PARALLAX=10.0/460.0
}
} 遍历图像中的每一个特征点,获取特征点对应的属性:x, y, z, p_u, p_v, velocity_x, velocity_y,存放在f_per_fra中。
然后在list类型的feature数据结构中按照feature_id来查找该feature,如果查不到该feature,则直接将该特征点信息加入到feature数据结构中。如果能查到的话,则在feature中和当前特征点对应的it中增加f_per_fra,并对跟踪到的特征点数进行累加(也就是代码中last_track_num++;)。
这里list类型的feature数据结构需要重点关注一下,其结构如下图所示:
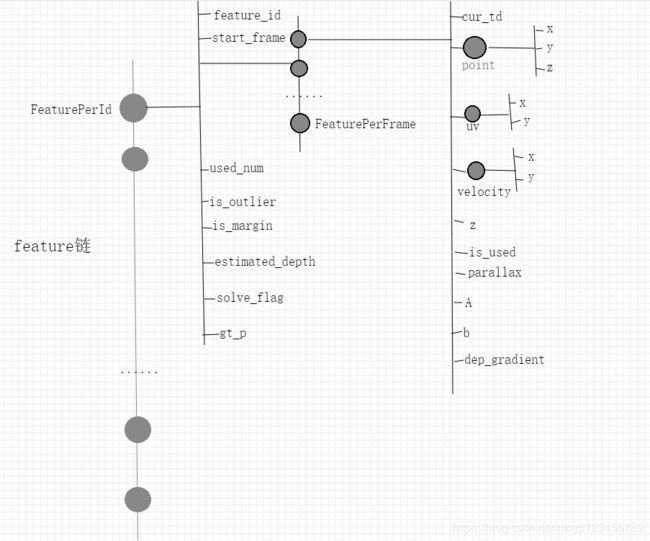
接下来,代码中判断如果当前图像帧数<2,那么返回true;如果当前传入图像中能跟踪到的特征点数<20也返回true。返回true后,在processImage中会将marginalization_flag设置为MARGIN_OLD,我们后边可以重点关注一下marginalization_flag值为MARGIN_OLD时的代码操作。
遍历feature中每个特征,计算特征在倒数第二和第三帧之间的视差,求解所有符合要求的特征点的总数和其视差和,用于后边计算平均视差。
compensatedParallax2函数是用于计算视差的函数。代码如下:
/**
* it_per_id 从特征点list上取下来的一个feature
* frame_count 当前滑动窗口中的frame个数
*/
double FeatureManager::compensatedParallax2(const FeaturePerId &it_per_id, int frame_count)
{
//check the second last frame is keyframe or not
//parallax betwwen seconde last frame and third last frame
//计算该特征点在倒数第二帧和倒数第三帧之间的视差
const FeaturePerFrame &frame_i = it_per_id.feature_per_frame[frame_count - 2 - it_per_id.start_frame];
const FeaturePerFrame &frame_j = it_per_id.feature_per_frame[frame_count - 1 - it_per_id.start_frame];
double ans = 0;
Vector3d p_j = frame_j.point;
double u_j = p_j(0);
double v_j = p_j(1);
Vector3d p_i = frame_i.point;
Vector3d p_i_comp;
//int r_i = frame_count - 2;
//int r_j = frame_count - 1;
//p_i_comp = ric[camera_id_j].transpose() * Rs[r_j].transpose() * Rs[r_i] * ric[camera_id_i] * p_i;
p_i_comp = p_i;
//p_i中存放的是该point的x,y,z的坐标值,p_i(2)就是z,也就是深度值
double dep_i = p_i(2);
double u_i = p_i(0) / dep_i;
double v_i = p_i(1) / dep_i;
/**
* 但是没有明白这里为什么对u_j、v_j不需要做除去深度的操作呢???
*/
double du = u_i - u_j, dv = v_i - v_j;
double dep_i_comp = p_i_comp(2);
double u_i_comp = p_i_comp(0) / dep_i_comp;
double v_i_comp = p_i_comp(1) / dep_i_comp;
double du_comp = u_i_comp - u_j, dv_comp = v_i_comp - v_j;
//视差距离计算。难道这里min中的两个平方距离的计算值不一样吗???
ans = max(ans, sqrt(min(du * du + dv * dv, du_comp * du_comp + dv_comp * dv_comp)));
return ans;
}如果parallax_num == 0,说明没有符合要求的特征点,也就是上边的计算视差和的代码并未执行,此时返回true。
如果平均视差>=MIN_PARALLAX(值为10.0/460.0),则返回true;
如果平均视差
我的理解是:当平均视差大于等于最小视差的情况下,删除滑动窗口中最旧的帧;当平均视差小于最小视差的情况下,删除滑动窗口中第倒数第二帧图像。