Hive高级
Hive是一个客户端的概念,不存在集群的概念。所以没有概念说Hive有集群。不过可以部署一台两台的Hive Service 2,用来让客户端连接,提交Hive的作业。
一、Hive的操作的方式
1.1 HiveService 2
HiveService2是一个服务,使得客户端可以查询提交作业。客户端有哪写呢?beeline/webui/Java API等等。
启动方式:
nohup hiveserver2 &
这样就在后台启动了一个HiveService2的服务,默认端口是10000,如果想要更改这个端口可以:
nohup hiveserver2 --hiveconf hive.service2.thrift.port=14000 &
这样服务端口就可以改成14000。可以看到这用的是thrift。
1.2 beeline
beeline可以作为一个客户端工具直接连接上面的提到的HiveService2服务。
连接方式:
两种启动连接方式:
1、启动beeline,然后去连接
beeline
!connect jdbc:hive2://localhost:10000 hadoop
2、启动连接
beeline -u jdbc:hive2://localhost:10000/default -n hadoop -w password
1.3 Java API
Java API 也是可以连接HiveService2的,这样方便提交代码和测试。
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
public static void main(String[] args) throws SQLException {
try {
Class.forName(driverName);
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
System.exit(1);
}
Connection con = DriverManager.getConnection("jdbc:hive2://192.168.5.145:10000/default", "hadoop", "");
Statement stmt = con.createStatement();
ResultSet res = stmt.executeQuery("select * from city_info ");
while (res.next()) {
System.out.println(res.getString(1)+" "+ res.getString(2)+" "+ res.getString(3));
}
}
需要Maven加载几个jar包。hive-exec、hive-jdbc、hadoop-common包。
1.4 WebUI
你也可以使用WebUI的方式,在Web中提交查询语句,Web显示结果,好处是随时随地可以使用,只要能打开web就可以,超级方便。
Hive官方也有WebUI,但是不推荐使用,推荐使用hue(官网:gethue.com)。或者Zeppelin,这个与spark结合使用的有点多。
二、Hive复杂数据类型
Hive中数据类型常用的有Int,string。但也有复杂的数据类型,比如:array、map、struct。复杂数据类型现在的要求就是能创建数据表,能导入,能查询,就可以了。
2.1 array数据类型
假设某个数据是如下这个样子(array.txt):
zhangsan beijing,shanghai,hangzhou,tianjin
lisi changchu,chengdu,wuhan,beijing
创建数据表:
create table IF NOT EXISTS hive_array(name string, work_locations array<string>)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
COLLECTION ITEMS TERMINATED BY ',';
导入数据:
load data local inpath '/home/hadoop/data/arraytest.txt' overwrite into table hive_array;
查询数据:
查询全部数据:
select * from hive_array;
查询数组大下:
select size(work_locations) from hive_array;
取值数组数据:
select work_locations[0] from hive_array;
求在tianjin上班的人:
select * from hive_array where array_contains(work_locations,'tianjin');
2.2 map
hive中数据元素也可以是map类型。
假设某个数据是如下这个样子(map.txt):
1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28
2,lisi,father:mayun#mother:huangyi#brother:guangyu,22
3,wangwu,father:wangjianlin#mother:ruhua#sister:jingtian,29
4,mayun,father:mayongzhen#mother:angelababy,26
创建数据表:
create table IF NOT EXISTS hive_map(id int, name string, family map<string,string>, age int)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '#'
MAP KEYS TERMINATED BY ':';
导入数据:
load data local inpath '/home/hadoop/data/map.txt' overwrite into table hive_map;
查询数据:
查询父亲:
select name, family['father'] as father from hive_map;
查询主键信息、值信息:
select map_keys(family), map_values(family) from hive_map;
查询有兄弟,兄弟是谁
select family['brother'] as brother from hive_map where array_contains(map_keys(family), 'brother');
2.3 struct
存放各种乱七八糟的东西。假设某个数据是如下这个样子(struct.txt):
192.168.1.1#zhangsan:40
192.168.1.2#lisi:50
192.168.1.3#wangwu:60
192.168.1.4#zhaoliu:70
创建数据表:
create table IF NOT EXISTS hive_struct(ip string, userinfo struct<name:string,age:int>)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '#'
COLLECTION ITEMS TERMINATED BY ':';
导入数据:
load data local inpath '/home/hadoop/data/struct.txt' overwrite into table hive_struct;
查询数据:
查询名字信息:
select ip, userinfo.name from hive_struct;
三、元数据
Hive的元数据是存放在mysql中的,如何找到这个存放的地址,${HIVE_HOME}/conf/hive-site.xml中connectionURL指明的mysql库中。
常用的表:version(存放Hive版本,有且只有一条数据)、DBS(Hive上对应数据库)、database_params(Hive数据库相关参数的信息)、tabls(Hive数据表相关信息)、COLUMNS_V2(Hive数据表列的信息)、partitions(分区表)、partition_keys(分区表主键表)、partition_key_vals(分区表顺序表)
后续还要整理元数据表和Hive的Hdfs中和元数据表各个关联关系。
四、Hive执行
Hive中可以不执行结果,而是显示执行计划,就是在Sql前加上explain,如果想要的信息再多一点:explain + extended + sql。
Hive 执行计划:
explain extended sql:
抽象语法树,将sql字符串转化成sql语法树
- ABSTRACT SYNTAX TREE
执行计划的依赖关系,会将步骤转化成作业流,每个作业流会依赖别的作业流
- STAGE DEPENDENCIES
执行步骤,可以看做mapreduce作业
- STAGE PLANS
扫描表,获取字段信息
--TableScan
五、Hive的优化
5.1 Join
在Hive中有Join大致分成两类:
common join/shuffle join/reduce join 普通的Join,带有shuffle功能
map join/broadcast join 没shuffle的join
什么是shuffle,shuffle是在reduce中,字面含义就是洗牌,就是将map中相同的key丢到一个reduce中。
因为shuffle常常需要从本地磁盘或者分发获取作业,所以通常性能会比只有map的作业性能差。
select e.empno, e.name, d.dname from emp e join dept d on e.DEPTNO=d.DEPTNO;
执行上面的sql,通过上面的Hive执行流程的介绍,首先Hive要读取HDFS上表的数据信息。
emp:
empno, ename, deptno
dept:
dname, deptno
可想而知,需要map导入两张表上诉的内容。Join的时候,map流程肯定拿deptno做key,其他做内容。
经过shuffle,shuffle是将相同的key分发到一个reduce上做处理。所以join的过程就是将相同的key(就是相同deptno)分发在一起。
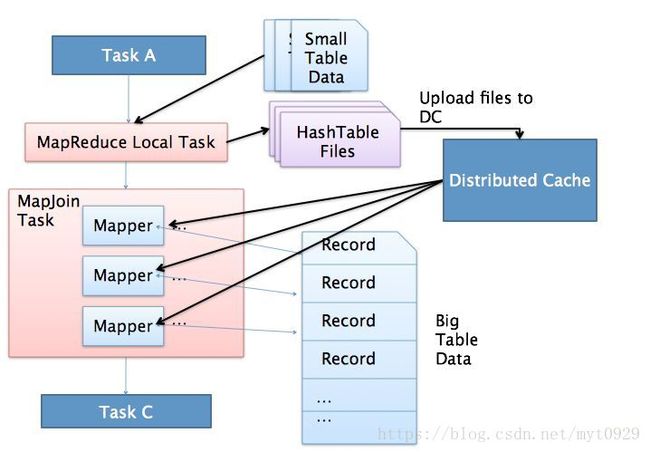
优化:就是不进行shuffle。如何才能bushuffle,就是只有Map作业,如果事先将一个表现导入到内存中,在另个表map过程中结合内存,处理完数据就不用shuffle了。
在高版本的Hive中(我使用的hive1.1.0版本中有了这个功能),已经有这个功能,而且默认是打开的,就是将小表数据进行缓存中(先将小标缓存到本地,生成一个HashTable文件,然后再进行分布式缓存),在大表map过程中,两个中做mapJoin。Hive这个参数(hive.auto.convert.join)默认为true。
mapJoin是有前提的:一个大表Join一个小表,才可以。什么小表这个和他能缓存的大小有关系(hive.mapjoin.smalltable.filesize or hive.smalltable.filesize)。
5.2 压缩
为什么要压缩?节省空间、方便传输、减少文件大小、减少IO操作。Hive的数据是在HDFS上,Hive的压缩就是HDFS存储数据的压缩。压缩要占用大量CPU,所以在CPU高的集群中就不要用压缩。
压缩分为有损压缩、无损压缩。有损常用于图片、视频。字节数据的压缩用的是无损。
压缩用于大数据的场景:map输入、map输出、reduce输出。涉及到HDFS压缩,map本地缓存,reduce的shuffle读入。
常用的压缩:
| Compression Format | Tool | algorithm | File extention | 压缩比 | 压解速度 | 支持分割 |
|---|---|---|---|---|---|---|
| gzip | gzip | DEFLATE | .gz | 较好 | 压缩一般,解压一般 | NO |
| bzip2 | bzip2 | bzip2 | .bz2 | 最好,大约30% | 压缩较慢,解压最慢 | Yes |
| LZO | lzop | LZO | .lzo | 一般,大约50% | 压缩较快,解压最快 | 有索引就可以分割 |
| Snappy | N/A | Snappy | .snappy | 较次,大约50% | 压缩最快,解压较快 | No |
压缩比好坏:bzip2 > gzip > lzo=snappy,压缩解压时间长短:bzip2 > gzip > lzo=snappy。
什么是分割。举个例子,一个没有压缩的1G数据用Map多少个MapTask,Mapredice中一个MapTask数量等于一个block数量,也就是1024M/128M=8个。如果是一个压缩的1G数据,用的是snappy压缩就只能有一个MapTask去处理,因为他不能被分割,只能一整块做处理,用Bzip2就可以用8个Task处理,因为他支持分割。
所以压缩分割,就是提高并行化处理压缩后的数据处理的能力。压缩的选型很重要,在MapReduce中压缩可以使用在3个方面:数据输入的压缩,Shuffle传输和中间态落地的压缩,结果输出的压缩。
数据读入的压缩,MR是从HDFS上读取,如果数据量大,建议使用可以分割的压缩方式,如bzip2,因为可以并行化处理MapTask。同时HDFS的存储格式建议使用ORC,parquet,Sequence(过时),RC(过时)等方式。
第二种压缩是MapReduce的shuffle传输和磁盘落地。因为这里的压缩主要是提高作业传输性能,所以建议使用压缩比不高的,但是压缩速度更快的snappy和LZO。
最后一种是Reduce输出。MR作业的结果是结果的落地或者是MR chaining 的传输。如果是用于归档,就是用压缩比高的;如果是MR chaining,就要使用可分割的压缩方式。
前面说压缩的为什么选择序列化文件存储方式。这样可以提高压缩效率,同时存储方式配合压缩可以更好的分片处理等。
5.2.1 如何配置压缩
如何查看你当前的hadoop版本有没有支持那种压缩格式。使用hadoop checknative,就能知道。
hadoop在使用压缩要在配置文件中配置,在conf/core-site.xml中配置你所要使用的压缩方式:
<property>
<name>io.compression.codecsname>
<value>
org.apache.hadoop.io.compress.GzipCodec,
org.apache.hadoop.io.compress.DefaultCodec,
org.apache.hadoop.io.compress.BZip2Codec,
org.apache.hadoop.io.compress.SnappyCodec
value>
property>
其次要让MR设置3个过程可以使用那些压缩方式,在mapred-site.xml配置:
<property>
<name>mapreduce.output.fileoutputformat.compressname>
<value>truevalue>
property>
<property>
<name>mapreduce.output.fileoutputformat.compress.codecname>
<value>org.apache.hadoop.io.compress.BZip2Codecvalue>
property>
<property>
<name>mapreduce.map.output.compressname>
<value>truevalue>
property>
<property>
<name>mapreduce.map.output.compress.codecname>
<value>org.apache.hadoop.io.compress.DefaultCodecvalue>
property>
5.2.2 Hive进行压缩
通常hive创建表的方式是
create table data(
id int,
name string
) row format delimited fields terminated by ',';
load data inpath '/1.txt' overwrite into table data;
这种方式的数据hive是不会压缩到hdfs上的。所以hdfs上数据大小:
hadoop fs -du -s -h /user/hive/warehouse/data - > 146.2 K
那hive进行压缩的方式,如果说所有的hive操作都是用压缩,可以将采用压缩的配置写到hive-site.xml中,但不建议,因为不同用户不同场景并不场景需要。
SET hive.exec.compress.output=true;
SET mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.BZip2Codec;
create table data_bzip2
row format delimited fields terminated by ','
as select * from data;
SET hive.exec.compress.output=false;
看下hdfs上数据大小:
hadoop fs -du -s -h /user/hive/warehouse/data_bzip2 -> 59 K
六、Hive的Storage Format
前面提到的,Hadoop中的文件存储格式,默认情况下,这个格式是文本形式。如果配合压缩则希望使用SequenceFile文件格式,那可以在创建表的时候指定:
create table data_a(
id int,
name string
)
row format delimited fields terminated by ','
stored as PARQUET;
//查看
desc formatted data_a;
如果创建其他格式的表,导入数据时导入的格式与创建时候格式不一致,那就会报错,解决这一方法很简单,先创建与导入数据一样格式的表然后将表中数据导入到目标格式的表中:
insert into target select * from a;
介绍两个压缩与存储格式的文件格式:orc和parquet。
6.1 ORC
ORC文件格式如果创建时,默认是带压缩格式的zlib压缩的,如果要去除压缩,则在创建的时候使用:
create table data_a(
id int,
name string
)
row format delimited fields terminated by ','
stored as ORC tblproperties ("orc.compress"="NONE");
这样就不会使用压缩,这样子的大小也比源文件大小小。
6.2 parquet
parquet可以在创建表的时候指定压缩方式。
set parquet.compression=GZIP;
create table data_a(
id int,
name string
)
row format delimited fields terminated by ','
stored as PARQUET;