Ubuntu16.04+cuda9.0+cudnn7.3+tensorflow
Ubuntu16.04+cuda9.0+cudnn7.3+tensorflow1.12
实验室服务器出问题了。。重新配置环境记录
1 安装 Ubuntu16.04
直接在ubuntu官网上下载(之前一直都用的16.04也就一直用了),通过rufus(无比简单好用)制作启动盘,分区类型选择了GPT。用了下rufus官网(https://rufus.ie/) 上的图:
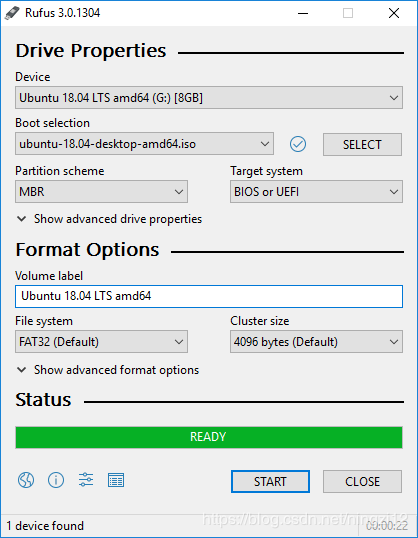
制作好启动盘之后,直接安装系统,由于只需要安装ubuntu一个系统,安装类型里选择清除整个磁盘安装ubuntu。等待一会就直接安装好了。
2 安装Nvidia驱动
2.1 先查看推荐的显卡驱动
ubuntu-drivers devices
推荐的是NVIDIA 384,所以服务器选择此版本。
2.2 禁用nouveau驱动
先在终端运行
$ lsmod | grep nouveau
如果有输出,代表nouveau驱动正在运行需要我们禁用。
先在终端中输入:
sudo vim /etc/modprobe.d/blacklist.conf
然后在文件最后输入(如果出现not commend,先安装vim;如果不知道怎么输入,百度如何在vim下操作):
blacklist nouveau
options nouveau modeset=0
接着执行:
$ sudo update-initramfs -u
最后重启,此时服务器已经无法进入图形化界面(显示一个字体很大的界面)然后按住[CTRL + ALT + F1]三个键进入命令行模式),输入账户名以及账户密码就可以进入命令行了。此时可以再次输入:
$ lsmod | grep nouveau
如果没有输出了,则已经禁用了nouveau驱动。
ps:看到有些教程重启之后好像还可以进入图形化界面,然后需要$ sudo service lightdm stop关闭图形化界面再进入命令行模式,可能是电脑不同吧。
2.3 安装NVIDIA驱动
在命令行模式下输入:
# 将系统中存在的nvidia驱动全部卸载掉(如果有的话)
sudo apt-get purge nvidia*
# 添加ppa源并更新(看到有的教程有,但我当时没有输入)
sudo add-apt-repository ppa:graphics-drivers/ppa
sudo apt-get update
# 安装nvidia-384版本
sudo apt-get install nvidia-384
然后重启:
$ sudo reboot
此时已经能进入图形化界面了,然后查看驱动状态:
$ sudo nvidia-smi
$ sudo nvidia-settings
3 安装cuda9.0
3.1 下载cuda
从NVIDIA官网上下载对应版本的cuda的runfile文件

3.2 安装cuda
关闭图形化界面:
$ sudo service lightdm stop
然后按Ctrl+Alt+F1进入命令行界面,然后cd到cuda的目录下:
sudo sh cuda_9.0.176_384.81_linux.run
借用下别人的图(后面给参考的CSDN链接)
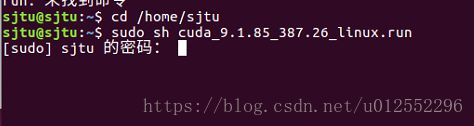
然后一直回车或者空格刷到底部:
然后出现各种是否同意的选项:
第一个accept,然后询问是否安装NVIDIA驱动,由于之前安装过所以填no,其他的都填yes就可以,并且安装到默认路径就可以。
恢复到图形化界面:
$ sudo service lightdm start
3.3 设置环境变量
sudo gedit ~/.bashrc
然后在打开的profile末尾加上:
export PATH="$PATH:/usr/local/cuda-9.0/bin"
export LD_LIBRARY_PATH="/usr/local/cuda-9.0/lib64"
关闭profile,然后输入:
source ~/.bashrc
3.4 验证cuda是否安装成功
$ cd /home/user_name/NVIDIA_CUDA-9.1_Samples
$ make
然后系统自动编译,大概需要十几到二十几分钟,如果编译成功会提示:Finished building CUDA samples
接着输入:
$ cd bin/x86_64/linux/release
$ ./deviceQuery
Result = PASS代表成功,若失败 Result = FAIL
最后检查下系统和CUDA-Capable device的连接情况:
$ ./bandwidthTest
Reslut=PASS则表示成功
4 安装cudnn
注册NVIDIA的账号,然后从NVIDIA官网上下载cudnn7.3 for cuda9.0,我下载的是:

然后cd进入cudnn文件下:
$ cd /home/your_name
将三个deb文件依次安装:
$ sudo dpkg -i libcudnn7_7.3.0.29-1+cuda9.0_amd64.deb
$ sudo dpkg -i libcudnn7-dev_7.3.0.29-1+cuda9.0_amd64.deb
$ sudo dpkg -i libcudnn7-doc_7.3.0.29-1+cuda9.0_amd64.deb
然后官方安装方法里有验证教程:
$ cp -r /usr/src/cudnn_samples_v7 $HOME
$ cd $HOME/cudnn_samples_v7/mnistCUDNN
$ make clean && make
$ ./mnistCUDNN
安装成功会提示:Test passed
如果提示缺少库,可以参考:
$ sudo cp /usr/local/cuda-9.1/lib64/libcudart.so.9.1 /usr/local/lib/libcudart.so.9.1 && sudo ldconfig
$ sudo cp /usr/local/cuda-9.1/lib64/libcublas.so.9.1 /usr/local/lib/libcublas.so.9.1 && sudo ldconfig
$ sudo cp /usr/local/cuda-9.1/lib64/libcurand.so.9.1 /usr/local/lib/libcurabd.so.9.1 && sudo ldconfig
$ sudo cp /usr/local/cuda-9.1/lib64/libcudnn.so.7 /usr/local/lib/libcudnn.so.7 && sudo ldconfig
参考:https://blog.csdn.net/youngping/article/details/84207234
参考:https://blog.csdn.net/guicai1647855685/article/details/82561138
参考:https://blog.csdn.net/u012552296/article/details/79831542
5 安装anaconda
5.1 下载anaconda
在官网上下载anaconda:Anaconda3-2019.03-Linux-x86_64.sh,anaconda的安装以及新建环境都很简单。
5.2 安装anaconda
cd进入anaconda所在的文件夹
bash Anaconda3-2019.03-Linux-x86_64.sh
然后一直回车,根据自己的要求输入其安装位置。最后是否添加到用户环境变量中,其实都可以。
5.3 新建环境
新建环境:
conda create -n env_name python=3.x
启动环境:
conda activate env_name
关闭环境:
conda deactivate
5.4 安装模块
查看安装模块:
conda list
等等还有很多conda命令就不介绍了。。
参考:https://blog.csdn.net/xin_101/article/details/88624726
6 安装tensorflow
在anaconda的自己的环境中安装tensorflow1.12
pip install tensorflow-gpu==1.12
看到有的博客中说:原来是tensorflow1.10.0需要更新到1.11.0,此时因tensorflow-gpu版本和cudnn(7.0.5)版本不一样产生冲突,报错。因为tensorflow-gpu1.11.0是基于cudnn7.2的,故需要升级cudnn7.2以上版本。
参考:https://blog.csdn.net/qq_15258623/article/details/84986720