Hadoop2.8集群安装详细教程
一、网络及主机名配置
| 192.168.1.2 | master.hadoop |
| 192.168.1.3 | slave1.hadoop |
| 192.168.1.4 | slave2.hadoop |
1.修改主机名
[root@master /]# vi /etc/hostname #主机名
master.hadoop[root@master ~]# hostname master.hadoop
[root@master ~]# hostname
master.hadoop其余结点一样的操作
[root@master ~]# cd /etc/hosts
192.168.1.2 master.hadoop
192.168.1.3 slave1.hadoop
192.168.1.4 slave2.hadoop
[root@master ~]# scp /etc/hosts 192.168.1.3:/etc
[root@master ~]# scp /etc/hosts 192.168.1.4:/etc2.修改网卡配置
硬件配置:取消动态ip地址,使用固定的
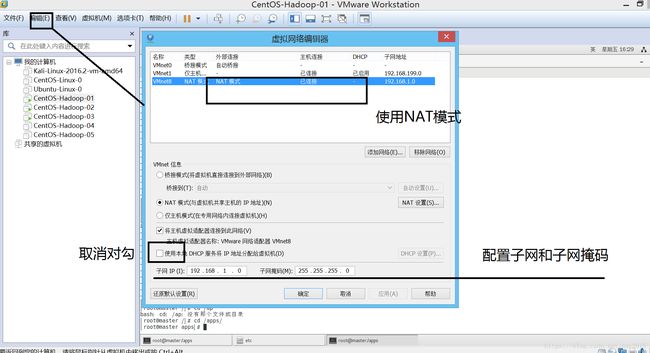
[root@master network-scripts]# cd /etc/sysconfig/network-scripts/
[root@master network-scripts]# ll
总用量 244
-rw-r--r--. 1 root root 363 7月 6 08:09 ifcfg-ens33
-rw-r--r--. 1 root root 254 5月 3 2017 ifcfg-lo
lrwxrwxrwx. 1 root root 24 4月 27 06:30 ifdown -> ../../../usr/sbin/ifdown
-rwxr-xr-x. 1 root root 654 5月 3 2017 ifdown-bnep
-rwxr-xr-x. 1 root root 6571 5月 3 2017 ifdown-eth
-rwxr-xr-x. 1 root root 6190 8月 4 2017 ifdown-ib
[root@master network-scripts]# vi ifcfg-ens33
[root@master network-scripts]# TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=none
DEFROUTE=yes
IPV4_FAILURE_FATAL=yes
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=ens33
UUID=f090a391-d137-4d93-8594-03baeada0d1f
DEVICE=ens33
ONBOOT=yes
IPADDR=192.168.1.2
PREFIX=24
GATEWAY=192.168.1.1
IPV6_PRIVACY=no
DNS1=192.168.1.13.重启网卡
[root@master network-scripts]# service network restart
#查看网络配置
[root@master network-scripts]# ifconfig
ens33: flags=4163 mtu 1500
inet 192.168.1.2 netmask 255.255.255.0 broadcast 192.168.1.255
inet6 fe80::5d8a:5d86:d69a:1d54 prefixlen 64 scopeid 0x20
ether 00:0c:29:be:6c:d6 txqueuelen 1000 (Ethernet)
RX packets 2787 bytes 199847 (195.1 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1488 bytes 96410 (94.1 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73 mtu 65536
inet 127.0.0.1 netmask 255.0.0.0
inet6 ::1 prefixlen 128 scopeid 0x10
loop txqueuelen 1 (Local Loopback)
RX packets 1477 bytes 143901 (140.5 KiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 1477 bytes 143901 (140.5 KiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
virbr0: flags=4099 mtu 1500
inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255
ether 52:54:00:a0:aa:ad txqueuelen 1000 (Ethernet)
RX packets 0 bytes 0 (0.0 B)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 0 bytes 0 (0.0 B)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 二、安装JDK
1、下载linux版本的jdk
jdk1.8下载地址

2、解压配置并环境变量
[root@master apps]# tar -zxvf jdk-8u171-linux-x64.tar.gz
[root@master apps]# vi /etc/profile
在其中添加一下内容:
export JAVA_HOME=/apps/jdk1.8.0_171
export JRE_HOME=/apps/jdk1.8.0_171/jre
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin然后更新配置文件
[root@master apps]# source /etc/profile3、测试安装
[root@master apps]# java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)三、配置SSH免密登录
1、每台机器生成自己的私钥和公钥
[root@master apps]# cd /root/.ssh/
[root@master .ssh]# ssh-keygen -t rsa
然后一直回车什么也不输入,直到结束。
[root@master .ssh]# touch authorized_keys
[root@master .ssh]# ll
总用量 16
-rw-r--r--. 1 root root 2000 7月 4 20:48 authorized_keys
-rw-------. 1 root root 1679 6月 19 15:17 id_rsa
-rw-r--r--. 1 root root 400 6月 19 15:17 id_rsa.pub
-rw-r--r--. 1 root root 935 7月 4 20:54 known_hosts
[root@master .ssh]# cat id_rsa.pub >> authorized_keys2、将每个节点的公钥都追加到一个名为(authorized_keys)的文件中
在另外两台机器同样的执行以下操作:
[root@slave apps]# cd /root/.ssh/
[root@salve .ssh]# ssh-keygen -t rsa
[root@slave .ssh]# ll
-rw-------. 1 root root 1679 6月 19 15:17 id_rsa
-rw-r--r--. 1 root root 400 6月 19 15:17 id_rsa.pub
-rw-r--r--. 1 root root 935 7月 4 20:54 known_hosts
将自己机器上的id_rsa.pub追加到主节点的authorized_keys文件中。
[root@slave .ssh]# scp id_rsa.pub 192.168.1.2:/
去主节点追加
[root@master .ssh]# cd /
[root@master .ssh]# cat id_rsa.pub >> /root/.ssh/authorized_keys3、将主节点上的authorized_keys分发给每一个从节点,测试登录
[root@master .ssh]# scp authorized_keys 192.168.1.3:$PWD
[root@master .ssh]# scp authorized_keys 192.168.1.4:$PWD
[root@master .ssh]# ssh 192.168.1.3
Last login: Fri Jul 6 16:02:23 2018
[root@slave1 ~]# 四、hadoop分布式集群安装
1、下载hadoop安装包
hadoop下载地址
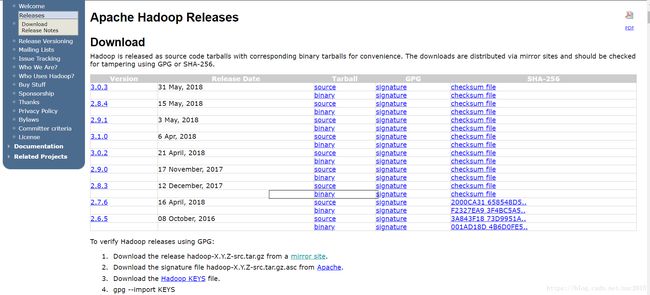
2、解压安装包,并修改配置文件
[root@master apps]# tar -zxvf hadoop-2.8.0.tar.gz
[root@master apps]# mkdir hdptmp
在两台从节点上建立相同的目录(hdfs初始化的时候会用到)1)配置hadoop-env.sh
# set java environment(添加jdk环境变量)
export JAVA_HOME=/apps/jdk1.8.0_1712)配置core-site.xml文件
修改Hadoop核心配置文件core-site.xml,这里配置的是HDFS的地址和端口号。
hadoop.tmp.dir
/apps/hdptmp
fs.defaultFS
hdfs://master.hadoop:9000
3)配置hdfs-site.xml文件
修改Hadoop中HDFS的配置,配置的备份方式默认为3。
dfs.replication
1
4)配置mapred-site.xml文件
修改Hadoop中MapReduce的配置文件,配置的是JobTracker的地址和端口。
mapreduce.framework.name
yarn
5) 配置yarn-site.xml文件
yarn.resouremanager.hostname
master.hadoop
yarn.nodemanager.aux-services
mapreduce_shuffle
6)配置slaves文件
[root@master /]# vi slaves
master.hadoop
slave1.hadoop
slave2.hadoop7) 配置hadoop环境变量
[root@master /]# vi /etc/profile
#set hadoop enviroment
export HADOOP_HOME=/apps/hadoop-2.8.0/
export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin#生效
[root@master /]# source /etc/profile3、将主节点上的文件复制到从节点上
[root@master /]# scp /apps 192.168.1.3:/
[root@master /]# scp /apps 192.168.1.4:/
[root@master /]# scp /etc/hosts 192.168.1.3:/etc
[root@master /]# scp /etc/hosts 192.168.1.4:/etc
[root@master /]# scp /etc/profile 192.168.1.3:/etc
[root@master /]# scp /etc/profile 192.168.1.4:/etc4、初始化HDFS
[root@master /]# hadoop namenode -format5、初始化完毕,启动测试
1)启动HDFS
[root@master /]# start-dfs.sh
Starting namenodes on [master.hadoop slave1.hadoop]
master.hadoop: starting namenode, logging to /apps/hadoop-2.8.0/logs/hadoop-root-namenode-master.hadoop.out
slave1.hadoop: starting namenode, logging to /apps/hadoop-2.8.0/logs/hadoop-root-namenode-slave1.hadoop.out
slave1.hadoop: starting datanode, logging to /apps/hadoop-2.8.0/logs/hadoop-root-datanode-slave1.hadoop.out
master.hadoop: starting datanode, logging to /apps/hadoop-2.8.0/logs/hadoop-root-datanode-master.hadoop.out
slave2.hadoop: starting datanode, logging to /apps/hadoop-2.8.0/logs/hadoop-root-datanode-slave2.hadoop.out
[root@master /]# jps
37984 DataNode
38470 Jps
37871 NameNode2)启动YARN
[root@master /]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /apps/hadoop-2.8.0/logs/yarn-root-resourcemanager-master.hadoop.out
slave2.hadoop: starting nodemanager, logging to /apps/hadoop-2.8.0/logs/yarn-root-nodemanager-slave2.hadoop.out
slave1.hadoop: starting nodemanager, logging to /apps/hadoop-2.8.0/logs/yarn-root-nodemanager-slave1.hadoop.out
master.hadoop: starting nodemanager, logging to /apps/hadoop-2.8.0/logs/yarn-root-nodemanager-master.hadoop.out
[root@master /]# jps
37984 DataNode
38832 Jps
38625 ResourceManager
38748 NodeManager
37871 NameNode