论文笔记——SqueezeNet
会议:ICLR 2017
标题:《SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE》
论文链接:https://arxiv.org/abs/1602.07360
代码链接:https://github.com/DeepScale/SqueezeNet
概要
- 提出了新的网络架构Fire Module,通过减少参数来进行模型压缩
- 归纳了缩小模型尺寸时的设计思路,使用其他方法对提出的SqueezeNet模型进行进一步压缩,模型缩小510倍
- 对参数空间进行了探索,主要研究了压缩比和3x3卷积比例的影响
Abstract
本文提出SqueezeNet。它在ImageNet上实现了和AlexNet相同的正确率,但是只使用了1/50的参数。更进一步,使用模型压缩技术,可以将SqueezeNet压缩到0.5MB,这是AlexNet的1/510。
1 Introduction and Motivation
近年来,CNNs的主要研究方向是提高目标检测器的精准性。对于一个给定的正确率,通常可以找到多种CNN架构来实现与之相近的正确率。对于相同的正确率,参数数量更少的CNN架构有如下优势:
(1)更高效的分布式训练
服务器间的通信是分布式CNN训练的重要限制因素。对于分布式数据并行训练方式,通信需求和模型参数数量正相关。小模型对通信需求更低,训练更快。
(2)减小下载模型到客户端的额外开销
在自动驾驶中,需要周期性更新客户端模型。目前的CNN / DNN模型的过度更新可能需要大量数据传输。更小的模型参数更少,从云端下载模型的数据量小,可以减少通信的额外开销,使得更新更加容易。
(3)便于在FPGA和嵌入式硬件上的部署
FPGA通常只有不到10MB的片上存储器,并且没有片外存储器或存储器。 对于预测,一个足够小的模型可以直接存储在FPGA上,而不是受到内存带宽的限制,同时还可以在FPGA上实时预测。 此外,当在应用专用集成电路(ASIC)上部署CNN时,可以将一个足够小的模型直接存储在片上存储器上,而较小的模型可以使ASIC能够安装在更小的芯片上。
考虑到这些优点,直接关注CNN架构的问题,该架构具有较少的参数,但与众所周知的模型相比具有相同的精度,称之为SqueezeNet。此外,尝试采用更加规范的方法来搜索新颖的CNN架构的设计空间。首先,描述并评估了SqueezeNet架构。之后,研究CNN架构设计对模型尺寸和准确性的影响。然后,设计了CNN微体系结构的空间探索,将其定义为单个层和模块的组织和维度;设计了CNN宏体系结构的空间探索,将其定义为CNN中层的高级组织。最后,进行了讨论。
2 Related Work
2.1 Model Compression
主要目标是确定一个参数非常少但同时保持准确性的模型。为了解决这个问题,一个明智的方法是采用现有的CNN模型并以有损的方式压缩它。
(1)奇异值分解(Singular value decomposition (SVD))
(2)网络剪枝(Network pruning):使用网络剪枝和稀疏矩阵
(3)深度压缩(Deep compression):使用网络剪枝,数字化和huffman编码
(4)硬件加速器(Hardware accelerator):EIE
2.2 CNN Microarchitecture
卷积已经在人工神经网络中使用了至少25年。LeCun等人的早期工作使用5x5滤波器;VGG架构广泛使用3x3滤波器;Network-in-Network和GoogLeNet系列架构等模型在某些层中使用1x1过滤器。
在设计深度网络架构的过程中,如果手动选择每一层的滤波器显得过于繁复。通常先构建由几个卷积层组成的小模块,再将模块堆叠形成完整的网络。使用术语CNN微体系结构来指代各个模块的特定组织和维度。例如,GoogLeNet提供了Inception模块,其中包括不同的过滤器数量,通常包括1x1和3x3,有时还有5x5,有时是1x3和3x1。
2.3 CNN Macroarchitecture
与模块相对应,定义完整的网络架构为CNN宏体系结构。在完整的网络架构中,深度是一个重要的参数。 VGG有12到19个层,表明更深的网络会有更高精度预测。 跨多层或模块的连接选择是CNN宏观架构研究的新兴领域。ResNet和Highway Networks建议使用跳过多个层的连接,例如将层3的激活附加连接到层6的激活,将这些连接称为bypass connection。 ResNet的作者提供了34层CNN的包括和不包括bypass connection的比较,添加bypass connection可以提高Top-5 ImageNet精度的2个百分点。
2.4 Neural Network Design Space Exploration
神经网络(包括DNNs和CNNs)具有很大的设计空间,有许多微体系结构,宏体系结构,求解器和其他超参数选项。想要了解这些因素如何影响神经网络的准确性(即设计空间的形状)。 神经网络的设计空间探索(DSE)的大部分工作都集中在开发自动化方法,以发现提供更高精度的神经网络架构。
通常进行设计空间探索的方法有:
(1)贝叶斯优化
(2)模拟退火
(3)随机搜索
(4)遗传算法
然而,这些方法的论文并未提供关于神经网络设计空间形状的尝试。在本文的后面,我们避开了自动化方法,相反,我们以这样一种方式重构CNN,即我们可以进行有原则的A/B比较,以研究CNN架构决策如何影响模型的大小和准确性。在以下部分中,我们首先提出并评估带有和不带模型压缩的SqueezeNet架构。然后,我们探讨了微架构和宏体系结构中的设计选择对类似SqueezeNet的CNN架构的影响。
3 SqueezeNet:Preserving Accuracy With Few Parameters
在本节中,首先概述参数很少的CNN的架构设计策略。 然后,介绍Fire模块,新的构建块用于构建CNN架构。 最后,使用设计策略来构建SqueezeNet,主要由Fire模块组成。
3.1 Architectural Design Strategies
使用以下三个策略来减少SqueezeNet设计参数:
1.使用1x1卷积代替3x3卷积:参数减少为原来的1/9
2.减少3x3卷积的输入通道数量:在一个完全由3x3滤波器组成的卷积层中,参数的总量是(输入通道数)x(滤波器数)x(3x3)。为了减少CNN的参数,不仅要减少3x3滤波器的数量,还要减少3x3滤波器的输入通道数量。这一部分使用squeeze layers来实现。
3.将欠采样操作延后,可以给卷积层提供更大的激活图:更大的激活图保留了更多的信息,可以提供更高的分类准确率。 在卷积网络中,每个卷积层产生一个输出激活图,其空间分辨率至少为1x1,通常远大于1x1。这些激活图的高度和宽度由以下控制:(1)输入数据的大小(例如256×256图像);(2)在CNN架构中下采样层的选择。最常见的是,通过在一些卷积或汇集层中设置(步幅> 1)来将下采样设计到CNN架构中。如果网络中的早期3层具有较大的步幅,则大多数层将具有小的激活映射。相反,如果网络中的大多数层具有1的步幅,并且大于1的步幅集中在网络的第4位,则网络将具有大的激活图。大型激活图(由于延迟下采样)可以获得更高的分类精度。
策略1和2是在尝试保持准确性的同时减少CNN中的参数数量。策略3是在有限的参数预算上最大化准确性。接下来,我们将介绍Fire模块,它是CNN架构的构建模块,使我们能够成功应用策略1,2和3。
3.2 The Fire Module
Fire Module是SqueezeNet中的基础构建模块,如下定义 Fire Module:

图1 fire module结构
- squeeze layer:只使用1x1卷积filter,即以上提到的策略1。
- expand layer:使用1x1和3x3卷积filter的组合。
- fire module中使用3个可调的超参数:
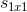 (squeeze中1x1filter的个数)、
(squeeze中1x1filter的个数)、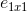 (expand中1x1filter的个数)、
(expand中1x1filter的个数)、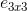 (expand中3x3filter的个数)。
(expand中3x3filter的个数)。 - 使用fire module的过程中,令 < + ,这样squeeze layer可以限制输入通道数量,即以上提到的策略2。
3.3 The SqueezeNet Architecture
SqueezeNet从一个独立的卷积层(conv1)开始,接着是8个Fire模块(fire2-9),最终以conv层(conv10)结束。 每个fire module中的filter数量逐渐增加,并且在conv1, fire4, fire8, 和 conv10这几层之后使用步长为2的max-pooling,即将池化层放在相对靠后的位置,这使用了以上的策略3。

图2 SqueezeNet结构(左:SqueezeNet,中:简单bypass,右:复杂bypass)

图3 完整的SqueezeNet架构
参数数量的计算方法:
以fire2模块为例:maxpool1层的输出为55x55x96,一共有96个通道。之后紧接着的Squeeze层有16个1x1x96的卷积filter.这一层的输出尺寸为55x55x16,之后将输出分别送到expand层中的1x1x16(64个)和3x3x16(64个)进行处理,注意这里不对16个通道进行切分。为了得到大小相同的输出,对3x3x16的卷积输入进行尺寸为1的zero padding。分别得到55x55x64和55x55x64大小相同的两个feature map。将这两个feature map连接到一起得到55x55x128大小的feature map。考虑到bias参数(一般为1),这里的参数总数为:
(1x1x96+1)x16+(1x1x16+1)x64+(3x3x16+1)x64 = 11920
可以看出,Squeeze层由于使用1x1卷积极大地压缩了参数数量,并且进行了降维操作,但是对应的代价是输出特征图的通道数(维数)也大大减少。之后的expand层使用不同尺寸的卷积模板来提取特征,同时将两个输出连接到一起,又将维度升高。但是,3x3x16的卷积模板参数较多,远超1x1卷积的参数,对减少参数十分不利,所以作者又针对3x3x16卷积进行了剪枝操作,以减少参数数量。从网络整体来看,feature map的尺寸不断减小,通道数不断增加,最后使用平均池化将输出转换成1x1x1000完成分类任务。
3.3.1 Other SqueezeNet Details
SqueezeNet网络的一些要点:
- 在expand中,为了使1x1和3x3filter输出的结果有相同的尺寸,给3x3filter的原始输入添加一个像素的边界(zero-padding)。
- squeeze和expand都用ReLU作为激活函数 。
- 在fire9 module之后,使用Dropout,比例取50% 。
- SqueezeNet没有全连接层,这借鉴了Network in Network的思想
- 训练过程中,初始学习率设置为0.04,在训练过程中线性降低学习率。
- 由于Caffe中不支持使用两个不同尺寸的filter,在expand中实际上是使用了两个单独的卷积层(1x1filter和3x3filter),最后将这两层的输出连接在一起,这在数值上等价于使用包含两个不同尺寸filter的单层。
在github上还有SqueezeNet在其他框架下的实现:MXNet、Chainer、Keras、Torch。
4 Evaluation of SqueezeNet

SVD方法能将预训练的AlexNet模型压缩为原先的1/5,top1正确率略微降低。网络剪枝的方法能将模型压缩到原来的1/9,top1和top5正确率几乎保持不变。深度压缩能将模型压缩到原先的1/35,正确率基本不变。
与AlexNet相比,SqueezeNet的模型尺寸缩小到1/50,同时达到或超过了AlexNet的Top-1和Top-5精度。如果将深度压缩(Deep Compression)方法用在SqueezeNet上,使用33%的稀疏表示和8位精度,会得到一个仅有0.66MB的模型。进一步,如果使用6位精度,会得到仅有0.47MB的模型,同时正确率不变。
结果表明,深度压缩不仅对包含庞大参数的CNN网络起作用,对于较小的网络,比如SqueezeNet,也是有用的。将SqueezeNet的网络架构创新和深度压缩结合起来可以将原模型压缩到1/510。
5 CNN Microarchitecture Design Space Exploration
在SqueezeNet中,每一个Fire module有3个维度的超参数,即![]() ,
,![]() 和
和![]() 。SqueezeNet一共有8个fire modules,即一共24个超参数。下面讨论其中一些重要的超参数的影响。为方便研究,定义如下更高级元参数:
。SqueezeNet一共有8个fire modules,即一共24个超参数。下面讨论其中一些重要的超参数的影响。为方便研究,定义如下更高级元参数:
 :第一个fire module中expand filter的个数
:第一个fire module中expand filter的个数 :fire module的个数
:fire module的个数 :在每个fire module之后增加的expand filter个数
:在每个fire module之后增加的expand filter个数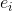 :第i个fire module中,expand filters的个数,
:第i个fire module中,expand filters的个数,![e_{i}=base_{e} + (incr_{e} * [\frac{i}{freq}]) = e_{i,1x1} + e_{i,3x3}](http://img.e-com-net.com/image/info8/9dc5cec6196448e59e87195c2c504b78.gif)
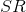 :压缩比(the squeeze ratio) ,即squeeze layer中filter个数除以expand layer中filter个数得到的一个比例
:压缩比(the squeeze ratio) ,即squeeze layer中filter个数除以expand layer中filter个数得到的一个比例 :在expand layer中,3x3卷积个占其卷积总个数的比例
:在expand layer中,3x3卷积个占其卷积总个数的比例
SqueezeNet元参数设置:![]() =128,
=128,![]() =2,
=2,![]() =128,
=128,![]() =0.125,
=0.125,![]() =0.5
=0.5

从实验结果可以看出,压缩比小于0.25时,正确率开始显著下降。
expand中3x3卷积比例小于25%时,正确率开始显著下降,此时模型大小约为原先的44%。超过50%后,模型大小显著增加,但是正确率不再上升。
6 CNN Macroarchitecture Design Space Exploration
受ResNet启发,这里探究bypass connection对模型大小和正确率的影响。

7 Conclusions
在这篇论文中,提出了对卷积神经网络的设计空间探索的建议。构建了一种新的CNN架构——SqueezeNet,其参数比AlexNet少50倍,并在ImageNet上保持AlexNet级的精度。将SqueezeNet压缩到小于0.5MB,比没有压缩的AlexNet小510倍。在SqueezeNet提出后,使用了新的方法Dense-Sparse-Dense (DSD)来进行压缩,同时提高了精度。Gschwend开发了SqueezeNet的变体并在FPGA上实现,能够将完全类似于SqueezeNet的模型的参数存储在FPGA内,并且无需片外存储器访问来加载模型参数。
优秀博文分享:【网络优化】超轻量级网络SqueezeNet算法详解