聚类之详解FCM算法原理及应用
【之前】 该文的pdf清晰版已被整理上传,方便保存学习,下载地址:
https://download.csdn.net/download/on2way/10394655
(一)原理部分
模糊C均值(Fuzzy C-means)算法简称FCM算法,是一种基于目标函数的模糊聚类算法,主要用于数据的聚类分析。理论成熟,应用广泛,是一种优秀的聚类算法。本文关于FCM算法的一些原理推导部分介绍等参考下面视频,加上自己的理解以文字的形式呈现出来,视频参考如下,比较长,看不懂的可以再去看看:
FCM原理介绍
FCM分析1
FCM分析2
FCM分析3
首先介绍一下模糊这个概念,所谓模糊就是不确定,确定性的东西是什么那就是什么,而不确定性的东西就说很像什么。比如说把20岁作为年轻不年轻的标准,那么一个人21岁按照确定性的划分就属于不年轻,而我们印象中的观念是21岁也很年轻,这个时候可以模糊一下,认为21岁有0.9分像年轻,有0.1分像不年轻,这里0.9与0.1不是概率,而是一种相似的程度,把这种一个样本属于结果的这种相似的程度称为样本的隶属度,一般用u表示,表示一个样本相似于不同结果的一个程度指标。
基于此,假定数据集为X,如果把这些数据划分成c类的话,那么对应的就有c个类中心为C,每个样本j属于某一类i的隶属度为 uij u i j ,那么定义一个FCM目标函数(1)及其约束条件(2)如下所示:
看一下目标函数(式1)而知,由相应样本的隶属度与该样本到各个类中心的距离相乘组成的,m是一个隶属度的因子,个人理解为属于样本的轻缓程度,就像 x2 x 2 与 x3 x 3 这种一样。式(2)为约束条件,也就是一个样本属于所有类的隶属度之和要为1。观察式(1)可以发现,其中的变量有 uij、ci u i j 、 c i ,并且还有约束条件,那么如何求这个目标函数的极值呢?
这里首先采用拉格朗日乘数法将约束条件拿到目标函数中去,前面加上系数,并把式(2)的所有j展开,那么式(1)变成下列所示:
现在要求该式的目标函数极值,那么分别对其中的变量 uij、ci u i j 、 c i 求导数,首先对 uij u i j 求导。
分析式(3),先对第一部分的两级求和的 uij u i j 求导,对求和形式下如果直接求导不熟悉,可以把求和展开如下:
这个矩阵要对 uij u i j 求导,可以看到只有 uij u i j 对应的 umij||xj−ci||2 u i j m | | x j − c i | | 2 保留,其他的所有项中因为不含有 uij u i j ,所以求导都为0。那么 umij||xj−ci||2 u i j m | | x j − c i | | 2 对 uij u i j 求导后就为 m||xj−ci||2um−1ij m | | x j − c i | | 2 u i j m − 1 。
再来看后面那个对 uij u i j 求导,同样把求和展开,再去除和 uij u i j 不相关的(求导为0),那么只剩下这一项: λj(uij−1) λ j ( u i j − 1 ) ,它对 uij u i j 求导就是 λj λ j 了。
那么最终J对 uij u i j 的求导结果并让其等于0就是:
这个式子化简下,将 uij u i j 解出来就是:
进一步:
uij=(−λjm||xj−ci||2)1m−1=(−λjm)1m−1(1||xj−ci||(2m−1))(4) (4) u i j = ( − λ j m | | x j − c i | | 2 ) 1 m − 1 = ( − λ j m ) 1 m − 1 ( 1 | | x j − c i | | ( 2 m − 1 ) )
要解出 uij u i j 则需要把 λj λ j 去掉才行。这里重新使用公式(2)的约束条件,并把算出来的 uij u i j 代入式(2)中有:
1=∑i=1cuij=∑i=1c(−λjm)1m−1(1||xj−ci||(2m−1))=(−λjm)1m−1∑i=1c(1||xj−ci||(2m−1)) 1 = ∑ i = 1 c u i j = ∑ i = 1 c ( − λ j m ) 1 m − 1 ( 1 | | x j − c i | | ( 2 m − 1 ) ) = ( − λ j m ) 1 m − 1 ∑ i = 1 c ( 1 | | x j − c i | | ( 2 m − 1 ) )
这样就有(其中把符号i换成k):
(−λjm)1m−1=(1∑i=1c(1||xj−ci||(2m−1)))=(1∑k=1c(1||xj−ck||(2m−1))) ( − λ j m ) 1 m − 1 = ( 1 ∑ i = 1 c ( 1 | | x j − c i | | ( 2 m − 1 ) ) ) = ( 1 ∑ k = 1 c ( 1 | | x j − c k | | ( 2 m − 1 ) ) )
把这个重新代入到式(4)中有:
uij=(1∑k=1c(1||xj−ck||(2m−1)))(1||xj−ci||(2m−1))=(1∑k=1c(||xj−ci||(2m−1))||xj−ck||(2m−1)))=1∑k=1c(||xj−ci||||xj−ck||)(2m−1)(5) (5) u i j = ( 1 ∑ k = 1 c ( 1 | | x j − c k | | ( 2 m − 1 ) ) ) ( 1 | | x j − c i | | ( 2 m − 1 ) ) = ( 1 ∑ k = 1 c ( | | x j − c i | | ( 2 m − 1 ) ) | | x j − c k | | ( 2 m − 1 ) ) ) = 1 ∑ k = 1 c ( | | x j − c i | | | | x j − c k | | ) ( 2 m − 1 )
好了,式子(5)就是最终的 uij u i j 迭代公式。
下面在来求J对 ci c i 的导数。由公式(2)可以看到只有 ∑i=1c∑j=1numij||xj−ci||2 ∑ i = 1 c ∑ j = 1 n u i j m | | x j − c i | | 2 这一部分里面含有 ci c i ,对其二级求和展开如前面所示的,那么它对 ci c i 的导数就是:
∂J∂ci=∑j=1n(−umij∗2∗(xj−ci))=0 ∂ J ∂ c i = ∑ j = 1 n ( − u i j m ∗ 2 ∗ ( x j − c i ) ) = 0
即:
∑j=1n(umijci)=∑j=1n(xjumij) ∑ j = 1 n ( u i j m c i ) = ∑ j = 1 n ( x j u i j m ) ci=∑j=1n(xjumij)∑j=1numij(6) (6) c i = ∑ j = 1 n ( x j u i j m ) ∑ j = 1 n u i j m
好了,公式(6)就是类中心的迭代公式。
我们发现 uij u i j 与 ci c i 是相互关联的,彼此包含对方,有一个问题就是在fcm算法开始的时候既没有 uij u i j 也没有 ci c i ,那要怎么求解呢?很简单,程序开始的时候我们随便赋值给 uij u i j 或者 ci c i 其中的一个,只要数值满足条件即可。然后就开始迭代,比如一般的都赋值给 uij u i j ,那么有了 uij u i j 就可以计算 ci c i ,然后有了 ci c i 又可以计算 uij u i j ,反反复复,在这个过程中还有一个目标函数J一直在变化,逐渐趋向稳定值。那么当J不在变化的时候就认为算法收敛到一个比较好的结了。可以看到 uij u i j 和 ci c i 在目标函数J下似乎构成了一个正反馈一样,这一点很像EM算法,先E在M,有了M在E,在M直至达到最优。
公式(5),(6)是算法的关键。现在来重新从宏观的角度来整体看看这两个公式,先看(5),在写一遍
假设看样本集中的样本1到各个类中心的隶属度,那么此时j=1,i从1到c类,此时上述式中分母里面求和中,分子就是这个点相对于某一类的类中心距离,而分母是这个点相对于所有类的类中心的距离求和,那么它们两相除表示什么,是不是表示这个点到某个类中心在这个点到所有类中心的距离和的比重。当求和里面的分子越小,是不是说就越接近于这个类,那么整体这个分数就越大,也就是对应的 uij u i j 就越大,表示越属于这个类,形象的图如下:
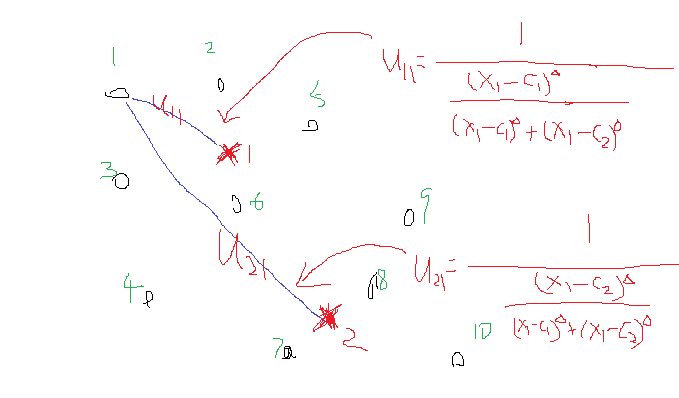
再来宏观看看公式(6),考虑当类i确定后,式(6)的分母求和其实是一个常数,那么式(6)可以写成:
这是类中心的更新法则。说这之前,首先让我们想想kmeans的类中心是怎么更新的,一般最简单的就是找到属于某一类的所有样本点,然后这一类的类中心就是这些样本点的平均值。那么FCM类中心怎么样了?看式子可以发现也是一个加权平均,类i确定后,首先将所有点到该类的隶属度u求和,然后对每个点,隶属度除以这个和就是所占的比重,乘以 xj x j 就是这个点对于这个类i的贡献值了。画个形象的图如下:
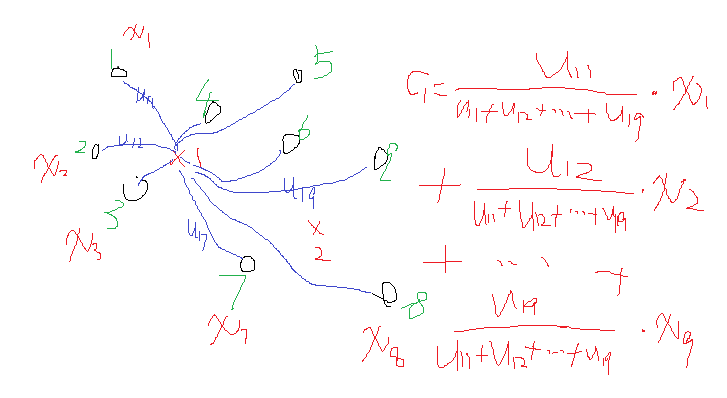
由上述的宏观分析可知,这两个公式的迭代关系式是这样的也是可以理解的。
(二)简单程序实现
下面我们在matlab下用最基础的循环实现上述的式(5)与式(6)的FCM过程。首先,我们需要产生可用于FCM的数据,为了可视化方便,我们产生一个二维数据便于在坐标轴上显示,也就是每个样本由两个特征(或者x坐标与y坐标构成),生成100个这样的点,当然我们在人为改变一下,让这些点看起来至少属于不同的类。生成的点画出来如下:

那么我们说FCM算法的一般步骤为:
(1)确定分类数,指数m的值,确定迭代次数(这是结束的条件,当然结束的条件可以有多种)。
(2)初始化一个隶属度U(注意条件—和为1);
(3)根据U计算聚类中心C;
(4)这个时候可以计算目标函数J了
(5)根据C返回去计算U,回到步骤3,一直循环直到结束。
还需要说一点的是,当程序结束后,怎么去判断哪个点属于哪个类呢?在结束后,肯定有最后一次计算的U吧,对于每一个点,它属于各个类都会有一个u,那么找到其中的最大的u就认为这个点就属于这一类。基于此一个基础的程序如下:
clc
clear
close all
%% create samples:
for i=1:100
x1(i) = rand()*5; %人为保证差异性
y1(i) = rand()*5;
x2(i) = rand()*5 + 3; %人为保证差异性
y2(i) = rand()*5 + 3;
end
x = [x1,x2];
y = [y1,y2];
data = [x;y];
data = data';%一般数据每一行代表一个样本
%plot(data(:,1),data(:,2),'*'); %画出来
%%---
cluster_n = 2;%类别数
iter = 50;%迭代次数
m = 2;%指数
num_data = size(data,1);%样本个数
num_d = size(data,2);%样本维度
%--初始化隶属度u,条件是每一列和为1
U = rand(cluster_n,num_data);
col_sum = sum(U);
U = U./col_sum(ones(cluster_n,1),:);
%% 循环--规定迭代次数作为结束条件
for i = 1:iter
%更新c
for j = 1:cluster_n
u_ij_m = U(j,:).^m;
sum_u_ij = sum(u_ij_m);
sum_1d = u_ij_m./sum_u_ij;
c(j,:) = u_ij_m*data./sum_u_ij;
end
%-计算目标函数J
temp1 = zeros(cluster_n,num_data);
for j = 1:cluster_n
for k = 1:num_data
temp1(j,k) = U(j,k)^m*(norm(data(k,:)-c(j,:)))^2;
end
end
J(i) = sum(sum(temp1));
%更新U
for j = 1:cluster_n
for k = 1:num_data
sum1 = 0;
for j1 = 1:cluster_n
temp = (norm(data(k,:)-c(j,:))/norm(data(k,:)-c(j1,:))).^(2/(m-1));
sum1 = sum1 + temp;
end
U(j,k) = 1./sum1;
end
end
end
figure;
subplot(1,2,1),plot(J);
[~,label] = max(U); %找到所属的类
subplot(1,2,2);
gscatter(data(:,1),data(:,2),label)得到结果如下:
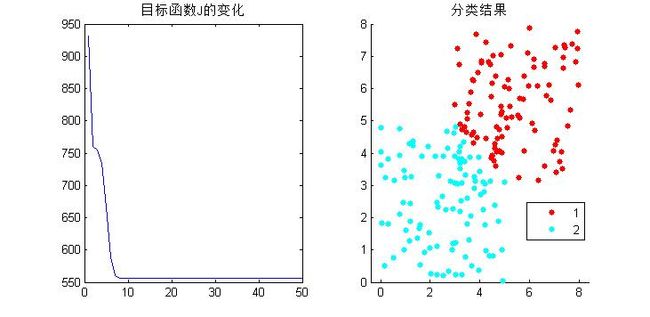
分成3类看看:
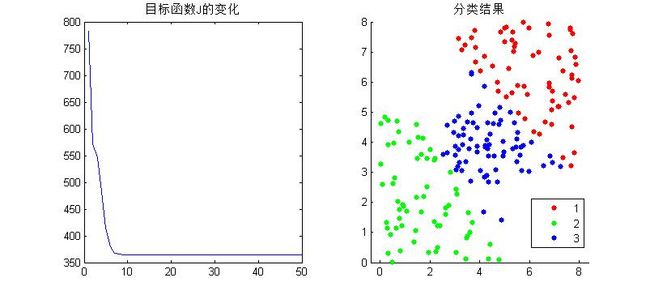
基于此,结果还算正确。但是不得不说的一个问题就是算法的效率问题。为了和公式计算方式吻合,便于理解,这个程序里面有很多的循环操作,当分类数大一点,样本多一点的时候,这么写是很慢的,matlab号称矩阵实验室,所以要尽量少的使用循环,直接矩阵操作,那么上述的操作很多地方是可以把循环改成矩阵计算的,这里来介绍下matlab自带的fcm函数,就是使用矩阵运算来的。
Matlab下help fcm既可以查阅相关用法们这里只是简单介绍,fcm函数输入需要2个或者3个参数,返回3个参数,如下:
[center, U, obj_fcn] = fcm(data, cluster_n, options)
对于输入:data数据集(注意每一行代表一个样本,列是样本个数)
cluster_n为聚类数。
options是可选参数,完整的options包括:
OPTIONS(1): U的指数 (default: 2.0)
OPTIONS(2): 最大迭代次数 (default: 100)
OPTIONS(3): 目标函数的最小误差 (default: 1e-5)
OPTIONS(4): 是否显示结果 (default: 1,显示)
options都有默认值,自带的fcm结束的条件是OPTIONS(2)与OPTIONS(3)有一个满足就结束。
对于输出:center聚类中心,U隶属度,obj_fcn目标函数值,这个迭代过程的每一代的J都在这里面存着。
为了验证我们写的算法是否正确,用它的fcm去试试我们的数据(前提是数据一样),分成3类,画出它们的obj_fcn看看如下:
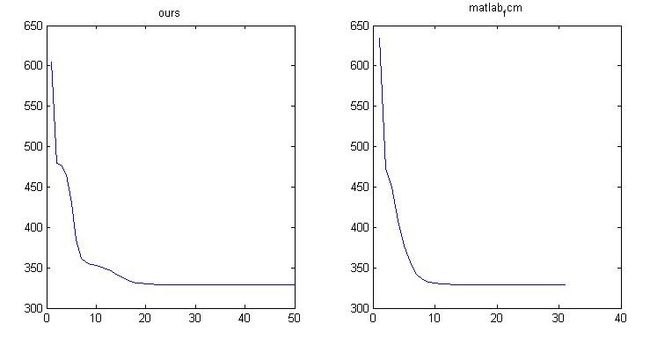
可以看到,虽然迭代的中间过程不一样,但是结果却是一样的。
(三)进阶应用
了解了fcm,再来看看它的几个应用。
3.1)基于fcm的图像分割
我们知道fcm主要用于聚类,而图像分割本身就是一个聚类的过程。所以可以用fcm去实现图像分割。
这里以matlab下的灰度图像为例。灰度图像一图像的角度看是二维的,但是我们知道,决定图像的无非是里面的灰度值。而灰度值就是一个值,所以当我们把图像变成1维,也就是拉成一行或者一列的时候,其实灰度图像就是一个一维数据(上面那个例子生成的随机点是二维的)。
那么我们就可以对这个一维数据进行聚类,待得到了分类结果后,再把这个结果返回到二维图像空间去显示就可以了。
一个例子如下:
clc
clear
close all
img = double(imread('lena.jpg'));
subplot(1,2,1),imshow(img,[]);
data = img(:);
%分成4类
[center,U,obj_fcn] = fcm(data,4);
[~,label] = max(U); %找到所属的类
%变化到图像的大小
img_new = reshape(label,size(img));
subplot(1,2,2),imshow(img_new,[]);
需要注意的是label出来的是标签类别(1-4),并非真实的灰度,这里不过是把它显示出来就行了。
3.2)实际数据的分类
这里介绍一个常用于机器学习、模式划分的数据下载网站:
http://archive.ics.uci.edu/ml/datasets.html
这里面包含众多的数据库可用分类划分等。这里我们选择其中一个数据库:
http://archive.ics.uci.edu/ml/datasets/seeds#
这个数据库看介绍好像是关于种子分类的,里面共包含3类种子,每类种子通过什么x射线技术等等采集他们的特征,反正最后每个种子共有7个特征值来表示它(也就是说在数据里面相当于7维),每类种子又有70个样本,那么整个数据集就是210*7的样本集。从上面那个地方下载完样本集存为txt文件,并放到matlab工作目录下就可以使用了(注意看看下下来的数据有没有串位的,有的话要手动调整回去)。因为matlab只能显示低于3维的数据,这里有7维,我们现在在二维下显示其中的两维以及正确的分类结果看看什么情况:
clc
clear
close all
data = importdata('data.txt');
%data中还有第8列,正确的标签列
subplot(2,2,1);
gscatter(data(:,1),data(:,6),data(:,8)),title('choose:1,6 列')
subplot(2,2,2);
gscatter(data(:,2),data(:,4),data(:,8)),title('choose:2,4 列')
subplot(2,2,3);
gscatter(data(:,3),data(:,5),data(:,8)),title('choose:3,5 列')
subplot(2,2,4);
gscatter(data(:,4),data(:,7),data(:,8)),title('choose:4,7 列')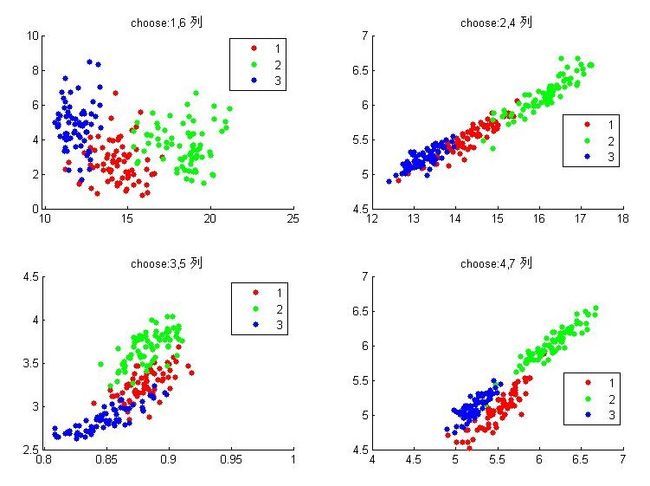
组合有限,随便组合几种看看,发现似乎任意两个特征都可以把他们分开,当然还是有一些分不开的,其中最后一个选择特征4,7似乎很好的分开了。
Ok,看过之后我们来试试fcm算法对其进行分类,并计算一下准确率,我们先把7个特征都用上看看:
clc
clear
close all
data = importdata('data.txt');
%data中还有第8列,正确的标签列
[center,U,obj_fcn] = fcm(data(:,1:7),3);
[~,label] = max(U); %找到所属的类
subplot(1,2,1);
gscatter(data(:,4),data(:,7),data(:,8)),title('choose:4,7列,理论结果')
% cal accuracy
a_1 = size(find(label(1:70)==1),2);
a_2 = size(find(label(1:70)==2),2);
a_3 = size(find(label(1:70)==3),2);
a = max([a_1,a_2,a_3]);
b_1 = size(find(label(71:140)==1),2);
b_2 = size(find(label(71:140)==2),2);
b_3 = size(find(label(71:140)==3),2);
b = max([b_1,b_2,b_3]);
c_1 = size(find(label(141:210)==1),2);
c_2 = size(find(label(141:210)==2),2);
c_3 = size(find(label(141:210)==3),2);
c = max([c_1,c_2,c_3]);
accuracy = (a+b+c)/210;
% plot answer
subplot(1,2,2);
gscatter(data(:,4),data(:,7),label),title(['实际结果,accuracy=',num2str(accuracy)])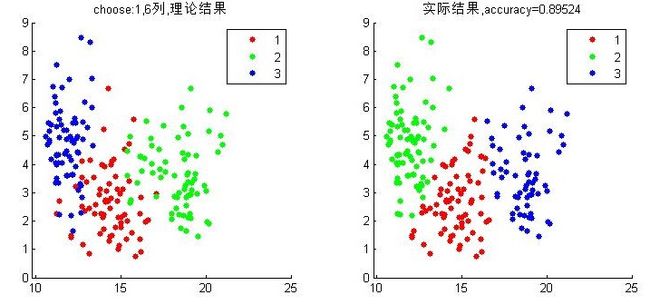
这里选择以第1与6维的数据来可视化这个结果。可以看到准确率为0.89524。
这就是用了所有特征来实验的,这与用哪个特征能到达更好的结果、怎么样吧特征进行处理下能达到更好的结果,这都是机器学习与分类领域在研究的事情。上面我们感觉特征4,7不错,那么当我们只用特征4与7去进行fcm会怎样呢?
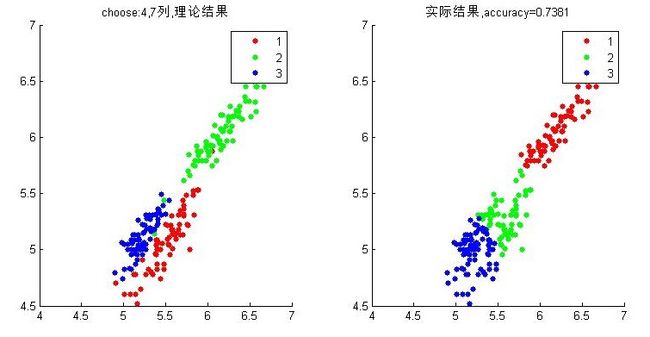
好像并不是很好,想想只用特征4与7结果本来就是这样的,不好就对了,fcm是根据数据距离划分来的,所以结果就是这样。
试了很多组特征,都没有超过0.89524的,那就所有特征都用上吧。其实这个准确率是可以提高的,我们看到这7个特征似乎有点重复有没有,如果我们把这7个特征采用pca降维到3,4个特征了再去fcm实验呢?可以去试试,有待实验……