反编译编译后的AndroidManifest
反编译AndroidManifest.xml是反编译APK的核心工作之一。
而且往往很多应用为了防御apktool的反编译,会采取一些防御性的手段,比如修改AndroidManifest.xml的
文件头,导致反编译出错。
结合AXMLPrinte的源码以及http://blog.csdn.net/jiangwei0910410003/article/details/50568487
自己写了针对编译后的AndroidManifest.xml的反编译代码
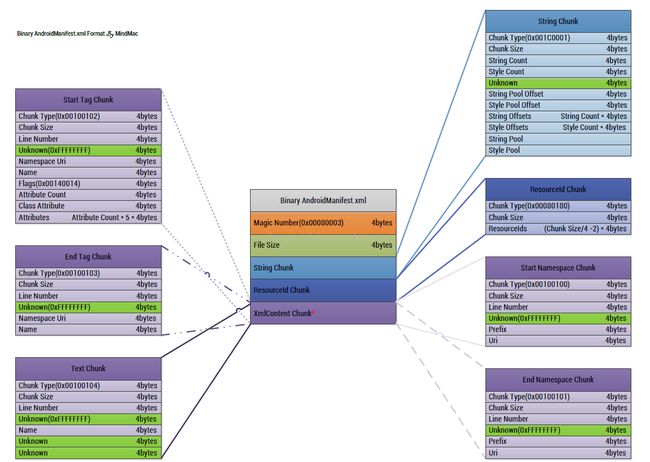
图片来自http://blog.csdn.net/jiangwei0910410003/article/details/50568487
class AroidManifest:
def __init__(self, fileInfo):
self.__fileInfo = fileInfo
self.strTable = []
self.namespaceMap = {}先自定义AndroidManifest的处理类
准备一个list保存字符串池,一个dict保存namespace的映射
fileInfo则是保存的文件信息
下面是主要的处理逻辑
rawChunk = self.__fileInfo.getRawBinary()
switcher = {
0x001c0001: self.readStringChunk,
0x00080180: self.readResourceIdChunk,
0x00100100: self.readStartNamespaceChunk,
0x00100101: self.readEndNamespaceChunk,
0x00100102: self.readStratTagChunk,
0x00100103: self.readEndTagChunk,
0x00100104: self.readTextChunk
}
self.readHead(rawChunk)
rawChunk = rawChunk[8:]
while 1:
if not rawChunk:
break
start2End = toLong(rawChunk[4:8])
headTag = rawChunk[0:4]
switcher.get(toLong(headTag), self.readBreak)(rawChunk)
rawChunk = rawChunk[start2End:]rawChunk保存文件的二进制字符串
toLong函数是自定义的将二进制字符串转long,printHex则将二进制字符串按 “0x12 0x34 0x56 0x78” 的形式输出
根据每个chunk的头四位判断是什么chunk,4到8位计算大小
然后调用相应的函数
def readHead(self, rawBinary):
head = [rawBinary[:4], rawBinary[4:8]]
print("Magic num: " + printHex(head[0]))
print("File Size: " + str(toLong(head[1])))
def readStringChunk(self, rawBinary):
chunkSize = rawBinary[4:8]
chunkSize = toLong(chunkSize)
strCount = toLong(rawBinary[8:12])
offset = toLong(rawBinary[20:24]) + 8
offOfEachStr = []
print("String Chunk Type: " + printHex(rawBinary[0:4]))
print("String Chunk Size: " + str(chunkSize))
print("String Count: " + str(strCount))
print("Style Count: " + printHex(rawBinary[12:16]))
print("Unknow: " + printHex(rawBinary[16:20]))
print("String Start: " + str(hex(offset)))
for i in range(0, strCount):
offOfEachStr.append(rawBinary[28+4*i:32+4*i])
for i in range(0, strCount):
string = ''
startOffset = offset + toLong(offOfEachStr[i]) - 8
chrOffset = startOffset + 2
while rawBinary[chrOffset] != 0:
string += chr(rawBinary[chrOffset])
chrOffset += 2
print("Str: " + string)
self.strTable.append(string)字符串chunk结构
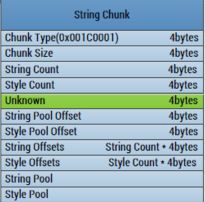
解析出来的每个字符串放到准备的list当中,便于以后使用
def readResourceIdChunk(self, rawBinary):
chunkSize = rawBinary[4:8]
chunkSize = toLong(chunkSize)
print("ResourceId Chunk Type: " + printHex(rawBinary[0:4]))
print("ResourceId Chunk Size: " + str(chunkSize))
count = (chunkSize - 8) // 4
for i in range(0, count):
id = toLong(rawBinary[8+i*4:12+i*4])
strHex = hex(id)
if len(strHex) != 10:
strHex = '0x' + (10-len(strHex)) * '0' + strHex[2:]
print("id: " + str(id) + " hex: " + strHex)
def readStartNamespaceChunk(self, rawBinary):
chunkSize = rawBinary[4:8]
chunkSize = toLong(chunkSize)
print("Start Namespace Chunk Type: " + printHex(rawBinary[0:4]))
print("Start Namespace Chunk Size: " + str(chunkSize))
count = (chunkSize - 8) // 16
for i in range(0, count):
table = rawBinary[8+i*16:24+i*16]
lineNum = toLong(table[0:4])
prefix = toLong(table[8:12])
Uri = toLong(table[12:16])
print("Line Number: " + str(lineNum))
print("Prefix: " + str(prefix))
print("Prefix Str: " + self.strTable[prefix])
print("Uri: " + str(Uri))
print("Uri Str: " + self.strTable[Uri])
if not self.strTable[prefix] in self.namespaceMap:
self.namespaceMap[self.strTable[prefix]] = self.strTable[Uri]
if not self.strTable[Uri] in self.namespaceMap:
self.namespaceMap[self.strTable[Uri]] = self.strTable[prefix]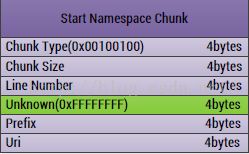
用之前准备好的map保存prefix和Uri的对应关系,在之后的解析会用到
最关键的内容是readStartTagChunk和readEndTagChunk,这两个分别解析Start Tag Chunk 和 End Tag Chunk。
专业术语不太直观,举个例子
在解析时会变成这样
Start Tag Chunk Type: 0x2 0x1 0x10 0x0
Start Tag Chunk Size: 56
line number: 12
prefix null
Uri null
tag name index: 36
tag name str: uses-permission
attr count1
nameSpaceUri: 25
nameSpaceUri str: http://schemas.android.com/apk/res/android
name: 4
name: name
valueString: 37
valueString str: android.permission.INTERNET
type: 3
data: 37
End Tag Chunk Type: 0x3 0x1 0x10 0x0
End Tag Chunk Size: 24
line number: 12
prefix null
Uri null
tag name index: 36
tag name str: uses-permission
index都是在字符串池中的下标,翻译为具体的str
可以看到Start Tag (红色部分),tag name为uses-permission,namespaceUri的值根据我们保存的namespaceMap
映射可以变成android,name的值为name。然后是value,值为android.permission.INTERNET
组合起来看uses-permission android:name=android.permission.INTERNET
那End Tag(蓝色)呢,其实就是结束标志。那么按照语法规则处理一下就变成
<uses-permission android:name="android.permission.INTERNET" />
下面是代码
StartTagChunk
def readStratTagChunk(self, rawChunk):
chunkSize = rawChunk[4:8]
chunkSize = toLong(chunkSize)
rawBinary = rawChunk[:chunkSize]
print("Start Tag Chunk Type: " + printHex(rawBinary[0:4]))
print("Start Tag Chunk Size: " + str(chunkSize))
table = rawBinary[8:]
while table != b'':
lineNum = table[0:4]
print("line number: " + str(toLong(lineNum)))
prefix = table[4:8]
prefixIndex = toLong(prefix)
if prefixIndex == -1:
print("prefix null")
else:
print("prefix: " + str(prefixIndex))
print("prefix str: " + self.strTable[prefixIndex])
namespaceUri = table[8:12]
uriIndex = toLong(namespaceUri)
if uriIndex == -1:
print("Uri null")
else:
print("uri: " + str(uriIndex))
print("uri str: " + self.strTable[uriIndex])
name = table[12:16]
nameIndex = toLong(name)
if nameIndex == -1:
print("tag name null")
else:
print("tag name index: " + str(nameIndex))
print("tag name str: " + self.strTable[nameIndex])
flags= table[16:20]
AttributeCount = table[20:24]
attrCount = toLong(AttributeCount)
print("attr count" + str(attrCount))
ClassAtrribute = table[24:28]
Atrributes = []
for i in range(0, attrCount):
entry = {}
for j in range(5):
value = toLong(table[28+i*20+j*4:32+i*20+j*4])
if j == 0:
entry["nameSpaceUri"] = value
if value == -1:
print("nameSpaceUri null")
else:
print("nameSpaceUri: " + str(value))
print("nameSpaceUri str: " + self.strTable[value])
elif j == 1:
entry["name"] = value
if value == -1:
print("name null")
else:
print("name: " + str(value))
print("name: " + self.strTable[value])
elif j == 2:
entry["valueString"] = value
if value == -1:
print("valueString null")
else:
print("valueString: " + str(value))
print("valueString str: " + self.strTable[value])
elif j == 3:
entry["type"] = (value >> 24)
if value == -1:
print("type null")
else:
print("type: " + str(value>>24))
elif j == 4:
entry["data"] = value
if value == -1:
print("data null")
else:
print("data: " + str(value))
Atrributes.append(entry)
splitSize = 28
splitSize += attrCount * 5 * 4
table = table[splitSize:]
def readEndTagChunk(self, rawBinary):
chunkSize = rawBinary[4:8]
chunkSize = toLong(chunkSize)
print("End Tag Chunk Type: " + printHex(rawBinary[0:4]))
print("End Tag Chunk Size: " + str(chunkSize))
lineNum = rawBinary[8:12]
print("line number: " + str(toLong(lineNum)))
prefix = rawBinary[12:16]
prefixIndex = toLong(prefix)
if prefixIndex == -1:
print("prefix null")
else:
print("prefix: " + str(prefixIndex))
print("prefix str: " + self.strTable[prefixIndex])
namespaceUri = rawBinary[16:20]
uriIndex = toLong(namespaceUri)
if uriIndex == -1:
print("Uri null")
else:
print("uri: " + str(uriIndex))
print("uri str: " + self.strTable[uriIndex])
name = rawBinary[20:24]
nameIndex = toLong(name)
if nameIndex == -1:
print("tag name null")
else:
print("tag name index: " + str(nameIndex))
print("tag name str: " + self.strTable[nameIndex])
Magic num: 0x3 0x0 0x8 0x0
File Size: 35264
String Chunk Type: 0x1 0x0 0x1c 0x0
String Chunk Size: 15024
String Count: 207
Style Count: 0x0 0x0 0x0 0x0
Unknow: 0x0 0x0 0x0 0x0
String Start: 0x360
Str: versionCode
Str: versionName
Str: minSdkVersion
Str: targetSdkVersion
...
...
ResourceId Chunk Type: 0x80 0x1 0x8 0x0
ResourceId Chunk Size: 104
id: 16843291 hex: 0x0101021b
id: 16843292 hex: 0x0101021c
id: 16843276 hex: 0x0101020c
id: 16843376 hex: 0x01010270
...
...
Start Namespace Chunk Type: 0x0 0x1 0x10 0x0
Start Namespace Chunk Size: 24
Line Number: 2
Prefix: 24
Prefix Str: android
Uri: 25
Uri Str: http://schemas.android.com/apk/res/android
Start Tag Chunk Type: 0x2 0x1 0x10 0x0
Start Tag Chunk Size: 136
line number: 2
prefix null
Uri null
tag name index: 30
tag name str: manifest
attr count5
nameSpaceUri: 25
nameSpaceUri str: http://schemas.android.com/apk/res/android
name: 0
name: versionCode
valueString null
type: 16
data: 10100096
nameSpaceUri: 25
nameSpaceUri str: http://schemas.android.com/apk/res/android
name: 1
name: versionName
valueString: 32
valueString str: 2.4.156
type: 3
data: 32
nameSpaceUri null
name: 27
name: package
valueString: 31
valueString str: com.xiaochen.android.fate_it
type: 3
data: 31
nameSpaceUri null
...
...