
目录:
- Python网络爬虫(一)- 入门基础
- Python网络爬虫(二)- urllib爬虫案例
- Python网络爬虫(三)- 爬虫进阶
- Python网络爬虫(四)- XPath
- Python网络爬虫(五)- Requests和Beautiful Soup
- Python网络爬虫(六)- Scrapy框架
- Python网络爬虫(七)- 深度爬虫CrawlSpider
- Python网络爬虫(八) - 利用有道词典实现一个简单翻译程序
- 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
- Python学习网络爬虫主要分3个大的版块:明确目标,抓取,分析,存储
- 明确目标 (要知道你准备在哪个范围或者网站去搜索)
- 爬 (将所有的网站的内容全部爬下来)
- 取 (去掉对我们没用处的数据)
- 处理数据(按照我们想要的方式存储和使用)
网络爬虫要做的,简单来说,就是实现浏览器的功能。通过指定url,直接返回给用户所需要的数据,而不需要一步步人工去操纵浏览器获取。
推荐一篇文章:关于反爬虫,看这一篇就够了
1.通用爬虫 VS 聚焦爬虫
1.通用爬虫:搜索引擎使用的爬虫系统
- 目标:尽可能把互联网上所有网页下载来,才能在本地服务器上,形成备份
- 实施:将网页以快照的形式保存在服务器上,进行关键字提取和垃圾数据剔除,提供用户一个访问的方式
3.操作:爬取网页->存储数据->内容处理->提供检索
4.搜索引擎排名——PageRank值——根据网站的流量进行顺序排名
1.1. 爬取流程
1.选择已有的url地址,将url地址添加到爬取队列
2.从提取url,DNS解析主机IP,将目标主机IP添加到爬取队列
3.分析网页内容,提取链接,继续执行上一步操作
1.2.搜索引擎获取新网站URL地址
1.主动推送URL地址->提交URL地址给搜索引擎->百度站长平台
2.其他网站的外链
3.搜索引擎和DNS服务商共同处理,收录新的网站信息
1.3.通用爬虫限制:Robots协议【约定协议robots.txt】
- robots协议:协议指明通用爬虫可以爬取网页的权限
- robots协议是一种约定,一般是大型公司的程序或者搜索引擎等遵守
1.4. 缺陷:
- 只能爬取和文本相关的数据,不能提供多媒体(图片、音乐、视频)以及其他二进制文件(代码、脚本等)的数据爬取
- 提供的结果千篇一律,提供给所有人通用的一个结果,不能根据具体的人的类型进行区分
2. 聚焦爬虫:
为了解决通用爬虫的缺陷,开发人员针对特定用户而开发的数据采集程序
特点:面向需求,需求驱动开发
2.HTTP & HTTPS
HTTP:超文本传输协议:Hyper Text Transfer Protocal
HTTPS: Secure Hypertext Transfer Protocol 安全的超文本传输协议
HTTP请求:网络上的网页访问,一般使用的都是超文本传输协议,用于传输各种数据进行数据访问,从浏览器发起的每次URL地址的访问都称为请求,获取数据的过程称为响应数据
-
抓包工具:在访问过程中,获取网络上传输的数据包的工具称为抓包工具,抓包:网络编程中专业术语名词,指代的是对网络上传输的数据进行抓取解析的过程。我之前用的是Wireshark,其他专业抓包工具如Sniffer,wireshark,WinNetCap.WinSock ,现在用的是Fiddler 抓包,Fiddler 下载地址。
- Fiddler 抓包简介
1). 字段说明
2). Statistics 请求的性能数据分析
3). Inspectors 查看数据内容
4). AutoResponder 允许拦截制定规则的请求
5). Filters 请求过滤规则
6). Timeline 请求响应时间 - Fiddler 设置解密HTTPS的网络数据
- Fiddler 抓取Iphone / Android数据包
- Fiddler 内置命令与断点
- Fiddler 抓包简介
浏览器设置代理进行数据抓包——建议使用谷歌的插件快捷设置不同的代理——Falcon Proxy
3.urllib2
- urllib2是python中进行网页数据抓取的一个操作模块,urllib2可以当作urllib的扩增,比较明显的优势是urllib2.urlopen可以接受Request对象作为参数,从而可以控制HTTP Request的headers,进而实现模拟浏览器、模拟登录等操作。
- 在python3中,对urllib2进行了优化和完善,封装成了urllib.request进行处理。
- Python 标准库 urllib2 的使用细节
- urllib:
编码函数:
urlencode()
远程数据取回:urlretrieve()
- urllib2:
urlopen()
Request()
urllib2第一弹——urlopen()
-urlopen()->response
->response->read()抓取网页数据
->response->info() 抓取网页请求报头信息
->response->geturl()抓取访问地址
->response->getcode()抓取访问错误码
注解:
-
urllib2库里面的urlopen方法,传入一个URL,协议是HTTP协议,urlopen一般接受三个参数,
urlopen(url, data, timeout)- 第一个参数url即为链接,
- 第二个参数data是访问url时要传送的数据,
- 第三个timeout是设置超时时间。
response对象有一个read方法,可以返回获取到的网页内容,即
response.read()urlopen参数可以传入一个request请求,它其实就是一个Request类的实例,构造时需要传入Url,Data等等的内容
代码操作一
# -*- coding:utf-8 -*-
#引入
import urllib2
response=urllib2.urlopen('https://www.baidu.com')
content=response.read()
print(content)

1.headers的属性介绍
User-Agent : 有些服务器或 Proxy 会通过该值来判断是否是浏览器发出的请求
Content-Type : 在使用 REST 接口时,服务器会检查该值,用来确定 HTTP Body 中的内容该怎样解析。
application/xml : 在 XML RPC,如 RESTful/SOAP 调用时使用
application/json : 在 JSON RPC 调用时使用
application/x-www-form-urlencoded : 浏览器提交 Web 表单时使用
在使用服务器提供的 RESTful 或 SOAP 服务时, Content-Type 设置错误会导致服务器拒绝服务
注意:Sublime使用正则匹配替换^(.*):(.*)$ --> "\1":"\2",
在pycharm中则是^(.*):(.*)$ --> "$1":"$2",
- 随机添加/修改User-Agent
可以通过调用
Request.add_header()添加/修改一个特定的header 也可以通过调用Request.get_header()来查看已有的header。
# urllib2_add_headers.py
import urllib2
import random
url = "http://www.itcast.cn"
ua_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36 OPR/26.0.1656.60",
"Opera/8.0 (Windows NT 5.1; U; en)",
"Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1) Gecko/20061208 Firefox/2.0.0 Opera 9.50",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; en) Opera 9.50",
"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:34.0) Gecko/20100101 Firefox/34.0",
"Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.57.2 (KHTML, like Gecko) Version/5.1.7 Safari/534.57.2 ",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.16 (KHTML, like Gecko) Chrome/10.0.648.133 Safari/534.16",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.101 Safari/537.36",
"Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.11 TaoBrowser/2.0 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)",
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; .NET4.0C; .NET4.0E; QQBrowser/7.0.3698.400)",
"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.84 Safari/535.11 SE 2.X MetaSr 1.0",
"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)",
]
user_agent = random.choice(ua_list)
request = urllib2.Request(url)
#也可以通过调用Request.add_header() 添加/修改一个特定的header
request.add_header("User-Agent", user_agent)
# 第一个字母大写,后面的全部小写
request.get_header("User-agent")
response = urllib2.urlopen(req)
html = response.read()
print html
代码操作二,伪装浏览器访问
# -*- coding:utf-8 -*-
#引入
import urllib2
from urllib2 import Request
#伪装浏览器访问
my_header={'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.108 Safari/537.36 2345Explorer/8.7.0.16013'}
request=Request('https://www.baidu.com',headers=my_header)
response=urllib2.urlopen(request)
content=response.read()
print(content)

2.Referer (页面跳转处)
Referer:表明产生请求的网页来自于哪个URL,用户是从该 Referer页面访问到当前请求的页面。这个属性可以用来跟踪Web请求来自哪个页面,是从什么网站来的等。
有时候遇到下载某网站图片,需要对应的referer,否则无法下载图片,那是因为人家做了防盗链,原理就是根据referer去判断是否是本网站的地址,如果不是,则拒绝,如果是,就可以下载;
3.Accept-Encoding(文件编解码格式)
Accept-Encoding:指出浏览器可以接受的编码方式。编码方式不同于文件格式,它是为了压缩文件并加速文件传递速度。浏览器在接收到Web响应之后先解码,然后再检查文件格式,许多情形下这可以减少大量的下载时间。
举例:Accept-Encoding:gzip;q=1.0, identity; q=0.5, ;q=0
如果有多个Encoding同时匹配, 按照q值顺序排列,本例中按顺序支持 gzip, identity压缩编码,支持gzip的浏览器会返回经过gzip编码的HTML页面。 如果请求消息中没有设置这个域服务器假定客户端对各种内容编码都可以接受。
4.Accept-Language(语言种类)
Accept-Langeuage:指出浏览器可以接受的语言种类,如en或en-us指英语,zh或者zh-cn指中文,当服务器能够提供一种以上的语言版本时要用到。
5. Accept-Charset(字符编码)
Accept-Charset:指出浏览器可以接受的字符编码。
举例:Accept-Charset:iso-8859-1,gb2312,utf-8
- ISO8859-1:通常叫做Latin-1。Latin-1包括了书写所有西方欧洲语言不可缺少的附加字符,英文浏览器的默认值是ISO-8859-1.
- gb2312:标准简体中文字符集;
- utf-8:UNICODE 的一种变长字符编码,可以解决多种语言文本显示问题,从而实现应用国际化和本地化。
如果在请求消息中没有设置这个域,缺省是任何字符集都可以接受。
6. Cookie (Cookie)
Cookie:浏览器用这个属性向服务器发送Cookie。Cookie是在浏览器中寄存的小型数据体,它可以记载和服务器相关的用户信息,也可以用来实现会话功能,以后会详细讲。
7. Content-Type (POST数据类型)
Content-Type:POST请求里用来表示的内容类型。
举例:Content-Type = Text/XML; charset=gb2312:
指明该请求的消息体中包含的是纯文本的XML类型的数据,字符编码采用“gb2312”。
7.服务端HTTP响应
HTTP响应也由四个部分组成,分别是: 状态行、消息报头、空行、响应正文
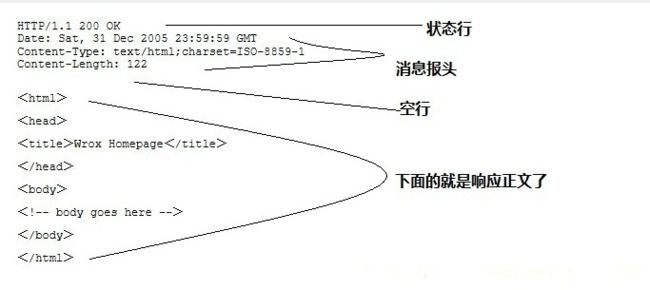
4.常用的响应报头(了解)
理论上所有的响应头信息都应该是回应请求头的。但是服务端为了效率,安全,还有其他方面的考虑,会添加相对应的响应头信息,从上图可以看到:
1. Cache-Control:must-revalidate, no-cache, private。
这个值告诉客户端,服务端不希望客户端缓存资源,在下次请求资源时,必须要从新请求服务器,不能从缓存副本中获取资源。
Cache-Control是响应头中很重要的信息,当客户端请求头中包含Cache-Control:max-age=0请求,明确表示不会缓存服务器资源时,Cache-Control作为作为回应信息,通常会返回no-cache,意思就是说,"那就不缓存呗"。
当客户端在请求头中没有包含Cache-Control时,服务端往往会定,不同的资源不同的缓存策略,比如说oschina在缓存图片资源的策略就是Cache-Control:max-age=86400,这个意思是,从当前时间开始,在86400秒的时间内,客户端可以直接从缓存副本中读取资源,而不需要向服务器请求。
2. Connection:keep-alive
这个字段作为回应客户端的Connection:keep-alive,告诉客户端服务器的tcp连接也是一个长连接,客户端可以继续使用这个tcp连接发送http请求。
3. Content-Encoding:gzip
告诉客户端,服务端发送的资源是采用gzip编码的,客户端看到这个信息后,应该采用gzip对资源进行解码。
4. Content-Type:text/html;charset=UTF-8
告诉客户端,资源文件的类型,还有字符编码,客户端通过utf-8对资源进行解码,然后对资源进行html解析。通常我们会看到有些网站是乱码的,往往就是服务器端没有返回正确的编码。
5. Date:Sun, 21 Sep 2016 06:18:21 GMT
这个是服务端发送资源时的服务器时间,GMT是格林尼治所在地的标准时间。http协议中发送的时间都是GMT的,这主要是解决在互联网上,不同时区在相互请求资源的时候,时间混乱问题。
6. Expires:Sun, 1 Jan 2000 01:00:00 GMT
这个响应头也是跟缓存有关的,告诉客户端在这个时间前,可以直接访问缓存副本,很显然这个值会存在问题,因为客户端和服务器的时间不一定会都是相同的,如果时间不同就会导致问题。所以这个响应头是没有Cache-Control:max-age=*这个响应头准确的,因为max-age=date中的date是个相对时间,不仅更好理解,也更准确。
7. Pragma:no-cache
这个含义与Cache-Control等同。
8.Server:Tengine/1.4.6
这个是服务器和相对应的版本,只是告诉客户端服务器的信息。
9. Transfer-Encoding:chunked
这个响应头告诉客户端,服务器发送的资源的方式是分块发送的。一般分块发送的资源都是服务器动态生成的,在发送时还不知道发送资源的大小,所以采用分块发送,每一块都是独立的,独立的块都能标示自己的长度,最后一块是0长度的,当客户端读到这个0长度的块时,就可以确定资源已经传输完了。
10. Vary: Accept-Encoding
告诉缓存服务器,缓存压缩文件和非压缩文件两个版本,现在这个字段用处并不大,因为现在的浏览器都是支持压缩的。
响应状态码
响应状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值。
常见状态码:
100~199:表示服务器成功接收部分请求,要求客户端继续提交其余请求才能完成整个处理过程。200~299:表示服务器成功接收请求并已完成整个处理过程。常用200(OK 请求成功)。300~399:为完成请求,客户需进一步细化请求。例如:请求的资源已经移动一个新地址、常用302(所请求的页面已经临时转移至新的url)、307和304(使用缓存资源)。400~499:客户端的请求有错误,常用404(服务器无法找到被请求的页面)、403(服务器拒绝访问,权限不够)。500~599:服务器端出现错误,常用500(请求未完成。服务器遇到不可预知的情况)。
Cookie 和 Session:
服务器和客户端的交互仅限于请求/响应过程,结束之后便断开,在下一次请求时,服务器会认为新的客户端。
为了维护他们之间的链接,让服务器知道这是前一个用户发送的请求,必须在一个地方保存客户端的信息。
Cookie:通过在 客户端 记录的信息确定用户的身份。
Session:通过在 服务器端 记录的信息确定用户的身份。
如果你觉得我的文章还可以,可以关注我的微信公众号:Python攻城狮
