图像分类:数据驱动方法-CS231N笔记
图像分类:数据驱动方法
图像分类任务是计算机视觉中的主要任务,当你做图像分类的时候分类系统接收了一些输入图像,比如可爱的猫,并且系统已经清楚了一些确定了分类或者标签的集合,这些标签可能是一只狗狗或者一只猫咪,也有可能是一辆卡车,还有一些固定类别的标签集合,那么计算机的工作就是看图片,但是它肯定没有人对猫的那样一种概念,电脑看到的只是一些像素,所以对于计算机来说这是一个巨大的数字矩阵,很难从中提取出猫的特性,我们把这个称为语义鸿沟。对于猫咪的概念或者它的标签是我们赋予特性的一个语义标签,一个猫的语义标签和计算机实际上看到的像素值之间有着巨大的差距。一旦图片发生了微妙的变化,这将导致像素网路整个发生变化,虽然两个矩阵中的数据完全不同,但是它们仍然都是代表猫,因此我们的算法需要对这些变化鲁棒。还不仅仅是视角的问题,还有光照条件不同的问题,目标对象还有变形的问题,还有遮挡的问题以及类内差异的问题,我们的算法应该是在这些条件下都是鲁棒的。
我们可以用Python写一个图像分类器,输入是图像,输出为图像的标签。
比如:
def classify_image(image):
return class_label
目前我们并没有直截了当的图像识别算法。
目前有一些硬编码的规则来识别不同的动物,我们都知道猫有耳朵、眼睛、嘴巴、鼻子,根据Hubel &Wiesel的研究,我们了解到边缘对于视觉识别是非常重要的,所以我们可以尝试计算图像的边缘,然后把边、角等各种形状分类好,比如有三条线是这样相交的,那这就可能是一个角点,比如猫耳朵有这样那样的角因此我们可以写一些规则来识别这些猫。但是实际上这些算法是不好的,容易出错。其次,如果我们相对另外一种对象进行分类,比如除了猫,我们需要识别其他的动物,就需要从头开始。

我们需要一种可以推演的方法,那就是数据驱动的方法。
我们不写具体的分类规则来识别一只猫或者鱼,我们从网上抓取大量猫的图片的数据集,一旦我们有了数据集,我们训练机器来分类这些图片,机器会去收集所有的数据,用某种方式总结,然后生成一个模型,总结出识别出这些不同类的对象的核心知识要素,然后我们用这些模型来是识别新的图片。因此我们的借口变成了这样:
写一个函数,不仅仅是输入图片,然后识别他是一只猫,我们会有两个函数,一个是训练函数,这函数接收图片和标签,然后输出模型;
另外一个函数输入新图片,然后输出标签。前一个模型为训练模型,后一个为预测模型。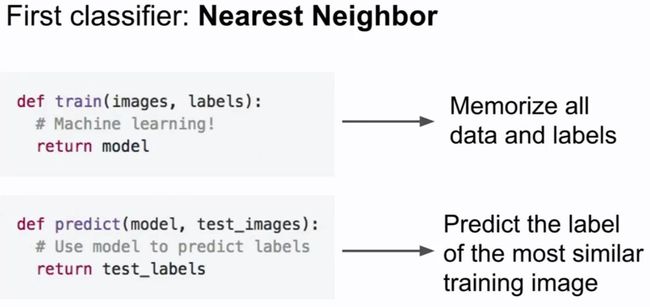
我们用一定的规则来比对一组图片,
比如L1 distance ,将两幅图片的像素相减,求这些差的绝对值之和。
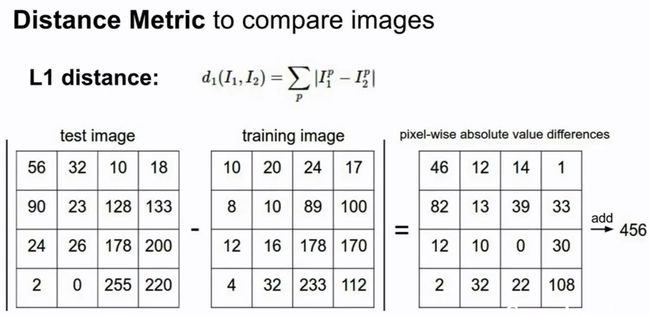
完整的Nearest NeighborPython 代码:
import numpy as np #进行向量运算
class NearestNeighbor:
def __init__(self):
pass
def train(self,x,y):
""" X is N * D where each row is an example . Y is 1-dimension of size N """
#近邻算法在训练阶段只是简单得记住训练数据
def predit(self,x):
""" X is N * D where each row is an example we wish to predict label for """
num_test = x,shape[0]
#保存输入输出的格式一致
Ypred = np.zeros(num_test,dtype=self.ytr.dtype)
for i in xrange(num_test):
#循环遍历每一个测试数据
distance = np.sum(np.abs(self.xtr-x[i,:}),asix=1)
min_index = np.argmin(diatances)
Ypred[i] = self.ytr[min_index]
return Ypred
注意:因为近邻算法在训练阶段只是简单地记住了训练图片,所以它的时间复杂度是0(1),但是测试阶段就是有一个将训练数据与测试数据对比的过程,其时间复杂度就是O(N)。与卷积神经网络不同,卷积神经网络在训练阶段花费的时间很长,在测试阶段就很快。
K最近邻(k-Nearest Neighbour,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一。该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。
用官方的话来说,所谓K近邻算法,即是给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例(也就是上面所说的K个邻居), 这K个实例的多数属于某个类,就把该输入实例分类到这个类中。 K值越大,边界越平滑。