场景文字检测之CTPN
论文:Detecting Text in Natural Image with Connectionist Text Proposal Network
Github(caffe版本):https://github.com/tianzhi0549/CTPN
Github(tensorflow版本):https://github.com/eragonruan/text-detection-ctpn
整体框架:
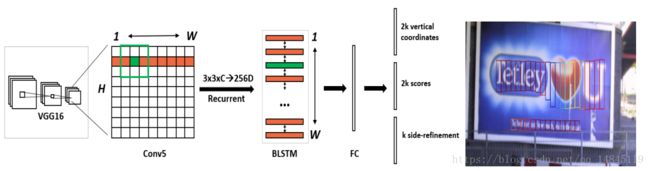
(1)首先一张图片经过VGG16基础网络,在conv5_3层引出,一共经过4个pooling操作,所以此时的conv5的大小为原图的1/16,维度为b*h*w*c(c=512)。
(2)在featuremap conv5上,由一个3*3的滑动窗口进行width方向的滑动。每一个3*3*c的向量会经过BLSTM转化为256维的向量。然后一共w个这样的向量,维度为b*h*w*c(c=256)。
(3)经过一个512维度的全连接层,维度变化为b*h*w*c(c=512)。
(4)这里k为anchor的个数,一共包含10个anchor,即k=10,从11-273像素,每次乘以1.4。该阶段分别输出垂直回归的中心点垂直方向的偏移和高度的偏移(vertical coordinates),维度为b*h*w*c*k(c=2,k=10),每个anchor回归的框的得分(score),前景得分和背景得分,维度为b*h*w*c*k(c=2),边框边缘的左右偏移值(side-refinement),维度为b*h*w*c*k(c=1)。
CTPN核心思想:

如上图所示,左面为传统RPN预测的框,右面为CTPN的框。由于RPN中anchor感受野的问题,不可能有一个anchor可以像传统的人车物检测那样覆盖了整行的文本。因此CTPN提出了宽度固定为16个像素的anchor策略。然后再将所有anchor预测结果进行NMS合并。
整体的思想还是非常novel的。
LOSS:
CTPN整体包含了3个loss,分类的Ls,边框回归的Lv,边框左右的回归的偏移Lo。
Ls为传统的softmax_cross_entropy_loss,其中,i表示所有预测的anchor中的第i个,Si_hat={0,1},Ns为归一化参数,表示所有的anchor的总和。
Lv使用的smooth_L1_loss,其中,j表示所有IOU>0.5的anchor中的第j个,Nv为归一化参数,表示所有的anchor和groudtruth的IOU>0.5的anchor数总和。λ1为多任务的平衡参数,λ1=1.0。

参数v的解释如上面的式子。实际需要预测的数值就是vc和vh,groundtruth为vc_hat和vh_hat。vc表示了实际的中心坐标和anchor中心的偏移,然后和anchor高度的比值,一句话说,就是,相对于anchor的中心坐标的归一化偏移量。同理,vh表示了归一化后的高度的伸缩量。
在实际预测的时候,只需要将式子反过来算,就可以算出cy和h,也就是最终的边框的中心坐标和高度。
Lo也是使用的smooth_L1_loss,其中,k表示边界anchor中的第k个,即预测和groundtruth相距32个像素的边界anchor的集合。Nv为归一化参数,表示所有边界anchor数总和。λ1为多任务的平衡参数,λ1=2.0。
![]()
o表示在x方向的归一化的偏移量。cx表示anchor的中心,Xside表示预测的中心。

如上图,红色的表示有side-refinement的结果,黄色为没有side-refinement的结果。可以看出经过side-refinement操作,可以使得边界更准确。
双向LSTM:

上图第一行表示没有使用BLSTM,第二行表示使用了BLSTM,可以看出,BLSTM可以起到将断开的区域连接起来的效果。并且使得边界更加准确。
测试和训练的输入图片大小:
测试:
测试的时候和faster的机制一样,也是短边大于600,长边小于1200,这样的按比例缩放的机制。
def resize_im(im, scale, max_scale=None):
f=float(scale)/min(im.shape[0], im.shape[1])
if max_scale!=None and f*max(im.shape[0], im.shape[1])>max_scale:
f=float(max_scale)/max(im.shape[0], im.shape[1])
return cv2.resize(im, None,None, fx=f, fy=f,interpolation=cv2.INTER_LINEAR), f训练:
训练的时候,为了可以走batch,所以是对一个batch内的图片,取最大的宽,高,其余小于该宽高的图片的其他位置补0,这样进行操作的。
def im_list_to_blob(ims):
"""Convert a list of images into a network input.
Assumes images are already prepared (means subtracted, BGR order, ...).
"""
max_shape = np.array([im.shape for im in ims]).max(axis=0)
num_images = len(ims)
blob = np.zeros((num_images, max_shape[0], max_shape[1], 3),
dtype=np.float32)
for i in range(num_images):
im = ims[i]
blob[i, 0:im.shape[0], 0:im.shape[1], :] = im
return blob
Anchor合并机制:
ctpn需要将每一个anchor回归的框进行合并,从而生成最终的文本框。
合并的主要原则,
(1)水平的最大连接距离为MAX_HORIZONTAL_GAP=50个像素
(2)垂直方向的一维IOU是否满足大于MIN_V_OVERLAPS=0.7比例
(3)两个相邻的anchor的高度是否满足小于MIN_SIZE_SIM=0.7比例
然后基于上述的原则,首先从左往右扫描一遍,将满足条件的anchor合并,然后从右往左扫描一遍,将满足条件的anchor合并。
其中,从左往右扫描的代码,
def get_successions(self, index):
box = self.text_proposals[index]
results = []
for left in range(int(box[0]) + 1, min(int(box[0]) + TextLineCfg.MAX_HORIZONTAL_GAP + 1, self.im_size[1])):
adj_box_indices = self.boxes_table[left]
for adj_box_index in adj_box_indices:
if self.meet_v_iou(adj_box_index, index):
results.append(adj_box_index)
if len(results) != 0:
return results
return results从右往左扫描的代码,
def get_precursors(self, index):
box = self.text_proposals[index]
results = []
for left in range(int(box[0]) - 1, max(int(box[0] - TextLineCfg.MAX_HORIZONTAL_GAP), 0) - 1, -1):
adj_box_indices = self.boxes_table[left]
for adj_box_index in adj_box_indices:
if self.meet_v_iou(adj_box_index, index):
results.append(adj_box_index)
if len(results) != 0:
return results
return results
一维高度IOU的代码,和高度差距小于0.7的代码,
def meet_v_iou(self, index1, index2):
def overlaps_v(index1, index2):
h1 = self.heights[index1]
h2 = self.heights[index2]
y0 = max(self.text_proposals[index2][1], self.text_proposals[index1][1])
y1 = min(self.text_proposals[index2][3], self.text_proposals[index1][3])
return max(0, y1 - y0 + 1) / min(h1, h2)
def size_similarity(index1, index2):
h1 = self.heights[index1]
h2 = self.heights[index2]
return min(h1, h2) / max(h1, h2)
return overlaps_v(index1, index2) >= TextLineCfg.MIN_V_OVERLAPS and \
size_similarity(index1, index2) >= TextLineCfg.MIN_SIZE_SIM
总结:
优点:
CTPN对于检测的边框在上下左右4个点上都比较准确,这点比EAST要好。
缺点:
(1)CTPN只可以检测水平方向的文本,竖直方向的话就会出现一个字一个字断开的想象。倾斜角度的话需要修改后处理anchor的连接方式,但是应该会引入新的问题。
(2)CTPN由于涉及到anchor合并的问题,何时合并,何时断开,这是一个问题。程序使用的是水平50个像素内合并,垂直IOU>0.7合并。或许由于BLSTM的引入,导致断开这个环节变差。所以对于双栏,三栏的这种文本,ctpn会都当做一个框处理,有时也会分开处理,总之不像EAST效果好。