Hive窗口函数的运用
1. 相关函数说明
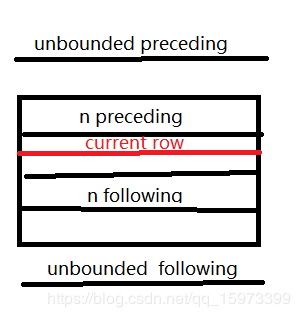
over():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化
current row:当前行
n preceding:往前n行数据
n following:往后n行数据
unbounded:起点,unbounded preceding表示从前面的起点, unbounded following表示到后面的终点
lag(col,n):往前第n行数据
lead(col,n):往后第n行数据
ntile(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,ntile返回此行所属的组的编号。
2. 数据准备
name,order_date,cost
jack,2017-01-01,10
tony,2017-01-02,15
jack,2017-02-03,23
tony,2017-01-04,29
jack,2017-01-05,46
jack,2017-04-06,42
tony,2017-01-07,50
jack,2017-01-08,55
mart,2017-04-08,62
mart,2017-04-09,68
neil,2017-05-10,12
mart,2017-04-11,75
neil,2017-06-12,80
mart,2017-04-13,943. 需求
根据以上信息建表,导入数据
hive (default)> create table orderlist(
> name string,
> order_date string,
> cost string)
> row format delimited fields terminated by ',';
OK
Time taken: 4.755 seconds
hive (default)> load data local inpath '/home/fanl/orderlist.txt' into table orderlist;
Loading data to table default.orderlist
Table default.orderlist stats: [numFiles=1, totalSize=266]
OK
Time taken: 1.153 seconds
hive (default)> select * from orderlist;
OK
orderlist.name orderlist.order_date orderlist.cost
jack 2017-01-01 10
tony 2017-01-02 15
jack 2017-02-03 23
tony 2017-01-04 29
jack 2017-01-05 46
jack 2017-04-06 42
tony 2017-01-07 50
jack 2017-01-08 55
mart 2017-04-08 62
mart 2017-04-09 68
neil 2017-05-10 12
mart 2017-04-11 75
neil 2017-06-12 80
mart 2017-04-13 94
Time taken: 0.279 seconds, Fetched: 14 row(s)
hive (default)>
(1)查询在2017年4月购买过的顾客及总人数
分析:要查询的时间是2017-04,通过截取order_date 字段来判断,用substring(order_date,0,7)截取字段值
首先先查询到2017-04的数据
hive (default)> select name from orderlist where substring(order_date,0,7)='2017-04';
OK
name
jack
mart
mart
mart
mart
在此基础上需要进行统计总人数,那么就要按照name字段分组,用count(1)来统计分组数,注意不是统计某个人的次数。
hive (default)> select name,count(1) over() from orderlist
> where substring(order_date,0,7)='2017-04' group by name;
OK
name _wcol0
mart 2
jack 2
Time taken: 43.421 seconds, Fetched: 2 row(s)
hive (default)>
(2)查询顾客的购买明细及月够买总额
分析:观察数据是2017年1月到6月的数据,按月分组,用内置函数month,并且用sum(cost)统计总额。
hive (default)> select name,order_date,cost,sum(cost)
> over(partition by month(order_date)) as total from orderlist;
OK
name order_date cost total
jack 2017-01-01 10 205.0
jack 2017-01-08 55 205.0
tony 2017-01-07 50 205.0
jack 2017-01-05 46 205.0
tony 2017-01-04 29 205.0
tony 2017-01-02 15 205.0
jack 2017-02-03 23 23.0
mart 2017-04-13 94 341.0
jack 2017-04-06 42 341.0
mart 2017-04-11 75 341.0
mart 2017-04-09 68 341.0
mart 2017-04-08 62 341.0
neil 2017-05-10 12 12.0
neil 2017-06-12 80 80.0
Time taken: 19.529 seconds, Fetched: 14 row(s)
(3)上述的场景,要将cost按照日期进行累加
分析:累加的意思是第一天是当天的cost,第二天是第一天和第二天的和,以此类推。
如何开窗:先将数据排序后,从上面介绍的函数中找可用的函数,可以用rows between xx and xx,从起点到当前行。
hive (default)> select name,order_date,cost,sum(cost)
> over(sort by order_date rows between unbounded preceding and current row)
> from orderlist;
OK
name order_date cost _wcol0
jack 2017-01-01 10 10.0
tony 2017-01-02 15 25.0
tony 2017-01-04 29 54.0
jack 2017-01-05 46 100.0
tony 2017-01-07 50 150.0
jack 2017-01-08 55 205.0
jack 2017-02-03 23 228.0
jack 2017-04-06 42 270.0
mart 2017-04-08 62 332.0
mart 2017-04-09 68 400.0
mart 2017-04-11 75 475.0
mart 2017-04-13 94 569.0
neil 2017-05-10 12 581.0
neil 2017-06-12 80 661.0
Time taken: 26.14 seconds, Fetched: 14 row(s)
hive (default)>
(4)查询顾客上次的购买时间
分析:上面提供的函数,lag()可以取到上一条,所以使用lag(order_date,1),取顾客的时间,按照姓名分组再按时间排序,所以使用over(partition by name group by order_date)
hive (default)> select name,order_date,cost,lag(order_date,1)
> over(partition by name order by order_date) from orderlist;
OK
name order_date cost _wcol0
jack 2017-01-01 10 NULL
jack 2017-01-05 46 2017-01-01
jack 2017-01-08 55 2017-01-05
jack 2017-02-03 23 2017-01-08
jack 2017-04-06 42 2017-02-03
mart 2017-04-08 62 NULL
mart 2017-04-09 68 2017-04-08
mart 2017-04-11 75 2017-04-09
mart 2017-04-13 94 2017-04-11
neil 2017-05-10 12 NULL
neil 2017-06-12 80 2017-05-10
tony 2017-01-02 15 NULL
tony 2017-01-04 29 2017-01-02
tony 2017-01-07 50 2017-01-04同理,如果查询后一跳,用lead(order_date,1)
(5)查询前20%时间的订单信息
分析:剩下最后一个ntile(),可用于分组返回它的组id,那么前20%即1/5,分5个组,取ntile(5)为1的数据
hive (default)> select * from (
> select name,order_date,cost,ntile(5)
> over(sort by order_date) as id from orderlist) t where t.id=1;
OK
t.name t.order_date t.cost t.id
jack 2017-01-01 10 1
tony 2017-01-02 15 1
tony 2017-01-04 29 1
Time taken: 20.253 seconds, Fetched: 3 row(s)
hive (default)>