Video Colorization 文献综述(不定期更新)
1. 2012 《A learning-based approach for automatic image and video colorizaiton》
关键词:自动图像着色,视频着色,随机森林,图像空间投票
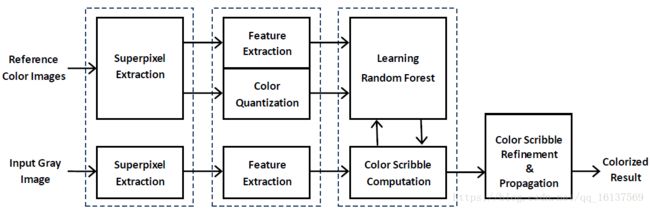
论文方法的框架如上图所示,大致可以分为4个步骤:
(1)超像素提取
(2)特征提取
(3)特征学习
(4)颜色笔画精炼和传播
(1)超像素提取
超像素(superpixels)指的是一组具有相似图像性质的连通像素点的压缩表示。这里使用Levinshtein等人提出的基于几何流的方法《TurboPixels: Fast Superpixels Using Applications》来计算超像素,算法使用源码的默认参数。
(2)特征提取
- 灰度特征
一个二维向量:第一维是超像素包含的所有像素的灰度平均值,第二维是领域超像素的灰度平均值 - 标准差特征
一个二维向量:计算5x5像素内的标准差作为每个点的特征值,然后按照灰度特征的计算方法得到二维特征向量 - Gabor特征
一个40维向量: 0∼7π/8 0 ∼ 7 π / 8 八个方向, I=0,1,2,3,4 I = 0 , 1 , 2 , 3 , 4 五个指数尺度的Gabor特征向量,每个超像素的特征使用超像素内包含点的Gabor特征的平均值 - 密集SIFT特征
一个128维向量:将邻域划分为4x4的单元数组,每个单元计算8个方向的特征,得到4x4x8=128维特征向量
(3)特征学习
- 颜色量化
对参考彩色图片在CIELab颜色空间进行量化。
使用超像素内a、b通道的平均像素值计算颜色标签。计算所有超像素的平均a、b通道值,再用K-means进行聚类。 - 随机决策森林
学习一个决策森林用于解决该多分类问题。
(4)颜色笔画精炼和传播
随机森林推理出来的在边界附近的颜色通常不是很可靠,论文使用了一种基于投票的方法来减少这样的超像素。
为了进行投标,首先使用论文《Mean shift: A robust approach toward feature space analysis》的方法对灰度图进行分割(源码地址:http://coewww.rutgers.edu/riul/research/code/EDISON/),然后检查每个分割区域的预测颜色标签情况。假设每个分割内拥有相同的颜色标签,分割区域内占多数颜色标签作为该区域的颜色标签。
对所有超像素的颜色标签进行更新之后,使用色度值(a、b通道的值)作为超像素的中心的笔画,然后使用论文《Colorization using optimization》的方法对中心点进行颜色传播。

论文说的看起来很有条理也有道理,但是这实验结果……emmm,我觉得没啥说服力,参考图像和测试图像不大体就是一样的吗?!如果换一张风格不一样的参考图像,会变成什么样?

视频的上色并没有多做其余的处理,只是把视频一帧一帧提取出来单独上色,所以出现了后两张图像马路颜色和前两张马路颜色不一致的问题。单看图片可能不怎么明显,如果放到视频中播放,就会出现闪烁的问题。
这篇论文的思路还是比较简单清晰的,将彩色图上色视为一个多分类问题,使用超像素的特征向量作为输入,用随机森林进行多分类,并通过投票的方式优化了边界着色的问题。
2. 2017 《Characterizing and improving stability in neural style transfer》
论文作者发现,像素的稳定性和图像风格的Gram矩阵的迹有关。Gram矩阵匹配目标方程的解集是一个球体,该球体的半径有风格图像的Gram矩阵的迹决定。如果Gram矩阵的迹很小,那么解集中包含的解将会生成比较相似的风格图像。相反地,如果Gram矩阵的迹很大,即球体半径很大,那么不同解之间将相距甚远,这样则会导致差别很大的风格图像。
这篇文章虽然讲的是视频的风格化,但它提到的视频连续帧的一致性有借鉴意义。
风格迁移的稳定性
先简单回顾一下风格迁移,给定一张内容图像 c c 和一张风格图像 s s ,输出图像 p p 要最小化下面的目标方程
首先用VGG-19在ImageNet上进行预训练,记 ϕj(x) ϕ j ( x ) 为神经网络的第 j j 层激活输出, Lc L c 和 Ls L s 定义为:
Lc L c 和 Ls L s 鼓励生成的图像在图像内容和图像风格的高级特征上相似,而不是鼓励单个像素上的一一对应。
然后在COCO数据集上训练12种风格的风格转换模型,然后用这12个模型分别对视频帧(our stable video dataset??看来是他们自己的视频)进行风格化,使用相邻两帧的风格均方差作为衡量指标,发现Gram矩阵的迹和风格稳定性呈负相关:

模型
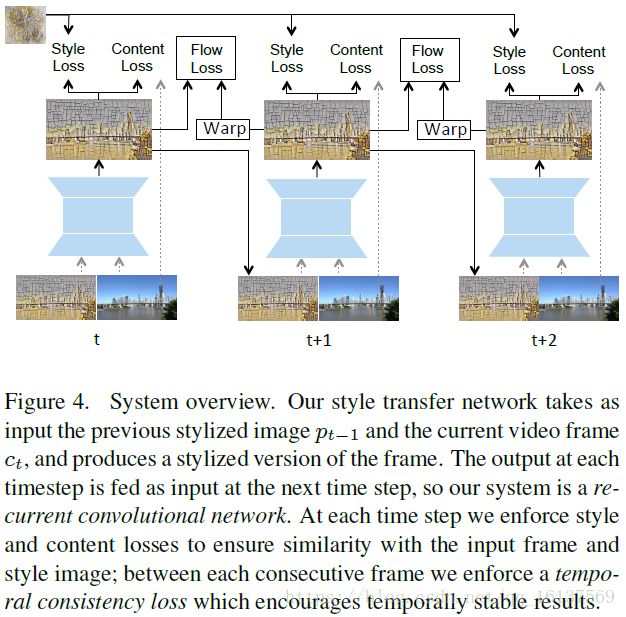
模型以内容图像的一个序列 c1,c2,...,cT c 1 , c 2 , . . . , c T 和一个风格 s s 作为输入,输出相应的风格图像序列 p1,p2,...,pT p 1 , p 2 , . . . , p T 。每一帧的输出图像 pt p t 应和 ct c t 内容一致,和风格 s s 保持一致,而且和前一帧 pt−1 p t − 1 应该相似。对于每个时间步,输出图像 pt p t 是由t-1时刻的输出图像和当前内容图像合成得到: pt=fW(pt−1,ct) p t = f W ( p t − 1 , c t ) ,于是训练网络 fW f W 的loss函数为:
看完这篇论文,发现视频上色的流程和单独训练彩色图上色还是挺大差别的,心塞。。。