python进阶(爬虫 BeautifulSoup用法)
操作演示文件: 文件名: webhtml.html
漏斗图
1111
logo
taobao
hahaha3333
taobao2
last... ...
11111111111111111111111
22222222222222222222222
- 注意:
- 操作响应内容:
- 不论是Beautiful Soup还是 lxml,获得 响应对象 时将其以 utf- 8 / gbk 的格式转化为 响应文本:代码:
- ① responce1 = requests.get('https://www.baidu.com').content.decode('utf-8')根据编码格式改变。
- 然后用这个响应内容来操作。
一、 Beautiful Soup的基本知识:
获取网页响应内容的方法:

1、Beautiful Soup用来处理导航、搜索、修改分析树,处理树状结构。比如说处理 爬虫requests得到的response(响应)对象。
2、Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。因此windows系统 open(‘文件名’,‘读写方式’,encoding = ‘utf- 8’),不写编码格式默认为GBK。
3、Beautiful Soup已成为和lxml、html5lib一样出色的python解析器。
二、Beautiful Soup 创建:
Beautiful Soup 是 模块bs4 中的一个方法。
(1)通过网页requests:
1 通过 requests 的response对像获得响应内容 单词: parser 解析 ,prettify 美化
from bs4 import BeautifulSoup
import requests
响应内容
responce1 = requests.get('https://www.baidu.com').content.decode('utf-8')
print(responce1)
soup = BeautifulSoup(responce1,'html.parser') # 创建Beautiful Soup 对象 soup
print(soup)
print(type(soup)) #
print(soup.prettify()) # 美化对象
print(soup.div) # 获得对象soup的 一个 div标签。
print(type(soup.div)) # Beautiful Soup对象soup的 tag(标签)对象。
print(soup.div.prettify()) # 美化 div 标签
Beautiful Soup 对象 soup 是一个树状结构 的 网页标签所有信息。
(2)通过打开文件创建:
from bs4 import BeautifulSoup
import requests
import re
soup = BeautifulSoup(open('webhtml.html',encoding='utf-8'),'html.parser') 这里区别于 lxml ,只需要 文件句柄,而
不需要 read()方法。
print(soup) 打印文件的所有内容,lxml方法处理后是一个对象。三、Beautiful Soup 访问节点和节点属性:
1、跳转指定标签和获得标签属性:通过 . 的方式
类似 面向对象 获取属性的方法,将soup对象看成多层嵌套的 字典 ,用 . 的方式来多层索引value:对象soup. 标签名获得一个标签。获得的结果都是 str。

from bs4 import BeautifulSoup
import requests
import re
soup = BeautifulSoup(open('webhtml.html',encoding='utf-8'),'html.parser')
print(soup.div) # 只能获得 一个且第一个 div 标签。
print(soup.div.name) # 当前标签名
print(type(soup.div)) # 标签对象
print(soup.div.attrs) # 获得当前 标签 div 的属性 , 输出是字典的方式(可以通过key索引)
print(soup.div.attrs['style']) 获得标签属性,是 str
#结果:
# 1111
# div
#
# {'id': 'main', 'style': 'width: 800px;height: 600px'}
# width: 800px;height: 600px
2、获取标签的内容:
- ①用 .string 只能获取第一层标签的内容。用时里面不能有子标签。结果是 str
- ②用 .strings可以获得所有子标签的内容的一个对象,需要for循环。结果是 str
- ③ .text 获得所有子标签的内容。结果是 str

import requests
from bs4 import BeautifulSoup
html_soup = BeautifulSoup(open('webhtml.html','r',encoding='utf-8'),'html.parser')
print(html_soup.article.span.a) 只能获得 第一个 a 标签。 获取所有用 findall 方法。
# 结果 : taobao
print(html_soup.article.span.a.string)
# 结果 : taobao
print(html_soup.article.span.strings) 所有 子标签 对象,需要for 循环。
for i in html_soup.article.span.strings:
print(i)
print(html_soup.article.span.text) text 与 strings 结果相同,不要for循环
print(html_soup.article.span.string) 结果: None(其本层有节点,想要获得内容可以通过兄弟节点方法获取)四、遍历文档节点:
- 特点:如果有注释,它也会保存在结果中

获取 子节点
print(html_soup.article.contents) -------- 都有的多层次子节点,是一个列表
print(html_soup.article.children) -------- 与.contents 结果相同,是一个迭代对象
for i in html_soup.article.children:
print(i)
获取 子孙节点
print(html_soup.article.descendants) -------- 使用较少,会大量重复
for i in html_soup.article.descendants:
print(i)


print(html_soup.article.next_sibling) -----------结果:空格(空格也算一个占用空间)
print(html_soup.article.next_sibling.next_sibling) ---------- 获取下一个节点通常需要两个.next_sibling五、Beautiful soup 中方法 find_all与find:
1、find与find_all用法:
- 特点:① find 只查找 满足条件的第一个值
- ② 传入属性时通常传入一个字典:
-

- ③

2、find_all具体用法:
- 特点:① find_all得到的结果是一个list。
- ② 传入属性时通常传入一个字典:
-
- ③ find_all( ) 有一个limit 选项,限制输出列表的元素个数

结果是 list
需找标签
寻找所有的a标签
print(html_soup.find_all('a')) 字符串表示标签名 为 a,与name=‘a’ 一样
print(html_soup.find_all(name='a'))
寻找所有的a标签和span标签
print(html_soup.find_all(['a','span']))
- 注意:①如果属性是class时,为了避免以关键字冲突,应当 写成 class_:
-
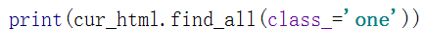
------------------------------------ find_all 和 find 用法:
find_all 返回列表形式
print(soup.find_all("div")) #查找所有标签名 div元素
print(soup.find_all("div",attrs={"class":"total_movies"})) # 查找 class 为 total_movies 的div
print(soup.find_all(['p','span'])) # 同时查找 p 和 span 标签
print(soup.find_all(re.compile("h\d"))) # 查找满足正则表达式的标签
print(soup.find_all(text="电影一")[0].parent) #查找标签内容等于 电影一 的文本内容
print(soup.find_all(text=re.compile("电影."),limit=2)) # limit 限定条数
============================================================================================
find 、find_all 在传入标签的属性时的三种情况:
all_div=soup.find_all("div",attrs={"class":'article'}) ----------- 找到 class 里包含 'article' 的所有标签
all_div=soup.find_all("div",attrs={"class":'article block untagged'}) ----------- 如果是两个或两个以上的属性时表示 class 等于 'article block untagged' 的所有标签
all_div=soup.find_all("div",attrs={"class":['article','block']} ------------ 表示class 包含 'article'和'block' 的所有标签
3、实际案例:
- (1)基本用法

- (2) limit 限制次数:
-
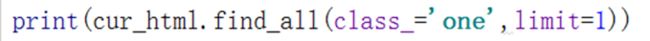
- (3)混合用法:由于find_all 结果是list,因此可以用列表的用法(区别 lxml与re模块分组的下标,它们下标是从1开始)。
-

六、通过CSS选择器获取
- 特点:结果是一个列表,通常用于find_all() 查找后的结果中
