以 iwslt2016 为例说明transformer的encode和decodeer计算细节
文章目录
- transformer感性认识
- encode的代码解读
- multihead_attention的实现细节
- scaled_dot_product_attention是个什么玩意?
- transformer 中的mask
- padding mask
- key mask
- query mask
- Sequence mask
- 核心代码
- tf.reduce_sum()
- 参考文章
transformer感性认识
看这篇博客之前可以把这个 图解transformer看一遍
问题:transformer的encode和decode怎么计算的?
这个问题答案在下文
下文统一设
encode层数为6
multihead的头的个数为8
embedding的维度为512
encode的代码解读
看完图解transformer,就会有一个感性的认识。首先我们看encode代码。下面的代码来源都是来自代码。
def encode(self, xs, training=True):
'''
Returns
memory: encoder outputs. (N, T1, d_model)
'''
with tf.variable_scope("encoder", reuse=tf.AUTO_REUSE):
x, seqlens, sents1 = xs
# embedding
enc = tf.nn.embedding_lookup(self.embeddings, x) # (N, T1, d_model)
enc *= self.hp.d_model**0.5 # scale
enc += positional_encoding(enc, self.hp.maxlen1)
enc = tf.layers.dropout(enc, self.hp.dropout_rate, training=training)
## Blocks
for i in range(self.hp.num_blocks):
with tf.variable_scope("num_blocks_{}".format(i), reuse=tf.AUTO_REUSE):
# self-attention
enc = multihead_attention(queries=enc,
keys=enc,
values=enc,
num_heads=self.hp.num_heads,
dropout_rate=self.hp.dropout_rate,
training=training,
causality=False)
# feed forward
enc = ff(enc, num_units=[self.hp.d_ff, self.hp.d_model])
memory = enc
return memory, sents1
加入num_blocks 等于6的话
上面的代码实现了一个有6个encode堆积的encoder。出了第一个encode输入是embedding + position embedding 外,其他5个的输入都是前一个encode的输出。
每个encode的输入输出的维度不变。也就是说加入输入是[batch_size, length, embedding维度]输出也是这个。
好的,在往上面代码的细节里看。看一下 multihead_attention干了啥
multihead_attention的实现细节
def multihead_attention(queries, keys, values,
num_heads=8,
dropout_rate=0,
training=True,
causality=False,
scope="multihead_attention"):
'''Applies multihead attention. See 3.2.2
queries: A 3d tensor with shape of [N, T_q, d_model].
keys: A 3d tensor with shape of [N, T_k, d_model].
values: A 3d tensor with shape of [N, T_k, d_model].
num_heads: An int. Number of heads.
dropout_rate: A floating point number.
training: Boolean. Controller of mechanism for dropout.
causality: Boolean. If true, units that reference the future are masked.
scope: Optional scope for `variable_scope`.
Returns
A 3d tensor with shape of (N, T_q, C)
'''
d_model = queries.get_shape().as_list()[-1]
with tf.variable_scope(scope, reuse=tf.AUTO_REUSE):
# Linear projections
# 分别对应论文中QW1、KW2、V1W3,只是把8个头同时计算了
Q = tf.layers.dense(queries, d_model, use_bias=False) # (N, T_q, d_model)
K = tf.layers.dense(keys, d_model, use_bias=False) # (N, T_k, d_model)
V = tf.layers.dense(values, d_model, use_bias=False) # (N, T_k, d_model)
# Split and concat
# 分裂成8个头
Q_ = tf.concat(tf.split(Q, num_heads, axis=2), axis=0) # (h*N, T_q, d_model/h)
K_ = tf.concat(tf.split(K, num_heads, axis=2), axis=0) # (h*N, T_k, d_model/h)
V_ = tf.concat(tf.split(V, num_heads, axis=2), axis=0) # (h*N, T_k, d_model/h)
# Attention
# 这个下面会说,为理解transformer的难点
outputs = scaled_dot_product_attention(Q_, K_, V_, causality, dropout_rate, training)
# Restore shape
# 将8个头的结构拼接,每个头的输出刚好是64维,拼接后又是512维
outputs = tf.concat(tf.split(outputs, num_heads, axis=0), axis=2 ) # (N, T_q, d_model)
# Residual connection
outputs += queries
# Normalize
outputs = ln(outputs)
return outputs
scaled_dot_product_attention是个什么玩意?
在论文中长这样:
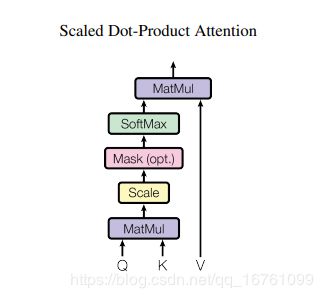
代码如下:
def scaled_dot_product_attention(Q, K, V,
causality=False, dropout_rate=0.,
training=True,
scope="scaled_dot_product_attention"):
'''See 3.2.1.
Q: Packed queries. 3d tensor. [N, T_q, d_k].
K: Packed keys. 3d tensor. [N, T_k, d_k].
V: Packed values. 3d tensor. [N, T_k, d_v].
causality: If True, applies masking for future blinding
dropout_rate: A floating point number of [0, 1].
training: boolean for controlling droput
scope: Optional scope for `variable_scope`.
'''
with tf.variable_scope(scope, reuse=tf.AUTO_REUSE):
d_k = Q.get_shape().as_list()[-1]
# dot product
# 对应 Q X K的转置
outputs = tf.matmul(Q, tf.transpose(K, [0, 2, 1])) # (N, T_q, T_k)
# scale
outputs /= d_k ** 0.5
# key masking
# 后面分析
outputs = mask(outputs, Q, K, type="key")
# causality or future blinding masking
# encode阶段这个值为False,先不管
if causality:
outputs = mask(outputs, type="future")
# softmax
outputs = tf.nn.softmax(outputs)
attention = tf.transpose(outputs, [0, 2, 1])
tf.summary.image("attention", tf.expand_dims(attention[:1], -1))
# query masking
# 后面分析
outputs = mask(outputs, Q, K, type="query")
# dropout
outputs = tf.layers.dropout(outputs, rate=dropout_rate, training=training)
# weighted sum (context vectors)
# 这个就是softmax后和value相乘
outputs = tf.matmul(outputs, V) # (N, T_q, d_v)
return outputs
transformer 中的mask
transformer的计算过程看了两个上午才看懂,还是跟以前的套路不一样。总结一下。
搜了很多资料说mask有两种,一种是padding mask 一种是sequence mask。
都是这么说
padding mask
什么是 padding mask 呢?因为每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充 0。但是如果输入的序列太长,则是截取左边的内容,把多余的直接舍弃。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!
而我们的 padding mask 实际上是一个张量,每个值都是一个Boolean,值为 false 的地方就是我们要进行处理的地方。
这个还是没说清楚。
比如输入是 2 * 3 的向量,如 [[1, 2, 3], [0, 0, 0]],其中2为句子长度,3为embedding长。
度。
transformer中有两个padding mask。一个是根据key,一个是根据query。
加入输出为
key mask
作用:
将output中值根据key的情况,把是0的行,都填充为 -2 ** 32 + 1.
这样在softmax就是0了。
可以自己仔细看代码,带入一个具体的值好好体会。
def mask(inputs, queries=None, keys=None, type=None):
"""Masks paddings on keys or queries to inputs
inputs: 3d tensor. (N, T_q, T_k)
queries: 3d tensor. (N, T_q, d)
keys: 3d tensor. (N, T_k, d)
e.g.,
>> queries = tf.constant([[[1.],
[2.],
[0.]]], tf.float32) # (1, 3, 1)
>> keys = tf.constant([[[4.],
[0.]]], tf.float32) # (1, 2, 1)
>> inputs = tf.constant([[[4., 0.],
[8., 0.],
[0., 0.]]], tf.float32)
>> mask(inputs, queries, keys, "key")
array([[[ 4.0000000e+00, -4.2949673e+09],
[ 8.0000000e+00, -4.2949673e+09],
[ 0.0000000e+00, -4.2949673e+09]]], dtype=float32)
>> inputs = tf.constant([[[1., 0.],
[1., 0.],
[1., 0.]]], tf.float32)
>> mask(inputs, queries, keys, "query")
array([[[1., 0.],
[1., 0.],
[0., 0.]]], dtype=float32)
"""
padding_num = -2 ** 32 + 1
if type in ("k", "key", "keys"):
# Generate masks
masks = tf.sign(tf.reduce_sum(tf.abs(keys), axis=-1)) # (N, T_k)
masks = tf.expand_dims(masks, 1) # (N, 1, T_k)
masks = tf.tile(masks, [1, tf.shape(queries)[1], 1]) # (N, T_q, T_k)
# Apply masks to inputs
paddings = tf.ones_like(inputs) * padding_num
outputs = tf.where(tf.equal(masks, 0), paddings, inputs) # (N, T_q, T_k)
query mask
跟key mask相似。只是将padding的值变为0
比如query为[[1, 2, 3], [0, 0, 0]] , 则masks = [[1, 1, 1], [0, 0, 0]]
elif type in ("q", "query", "queries"):
# Generate masks
masks = tf.sign(tf.reduce_sum(tf.abs(queries), axis=-1)) # (N, T_q)
masks = tf.expand_dims(masks, -1) # (N, T_q, 1)
masks = tf.tile(masks, [1, 1, tf.shape(keys)[1]]) # (N, T_q, T_k)
# Apply masks to inputs
outputs = inputs*masks
Sequence mask
文章前面也提到,sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为0。把这个矩阵作用在每一个序列上,就可以达到我们的目的。
对于 decoder 的 self-attention,里面使用到的 scaled dot-product attention,同时需要padding mask 和 sequence mask 作为 attn_mask,具体实现就是两个mask相加作为attn_mask。
其他情况,attn_mask 一律等于 padding mask。
核心代码
代码
tf.reduce_sum()
inputs = tf.convert_to_tensor([[[0, 0, 1],
[0, 1, 0],
[1, 0, 0]],
[[1, 0, 0],
[1, 0, 0],
[0, 1, 0]]], tf.float32)
a = tf.reduce_sum(inputs, axis=-1)
print(a)
# output
a = tf.Tensor(
[[1. 1. 1.]
[1. 1. 1.]], shape=(2, 3), dtype=float32)
def multihead_attention(queries,
keys,
num_units = None,
num_heads = 8,
dropout_rate = 0,
is_training = True,
causality = False,
scope = "multihead_attention",
reuse = None):
'''
Implement multihead attention
Args:
queries: [Tensor], A 3-dimensions tensor with shape of [N, T_q, S_q]
keys: [Tensor], A 3-dimensions tensor with shape of [N, T_k, S_k]
num_units: [Int], Attention size
num_heads: [Int], Number of heads
dropout_rate: [Float], A ratio of dropout
is_training: [Boolean], If true, controller of mechanism for dropout
causality: [Boolean], If true, units that reference the future are masked
scope: [String], Optional scope for "variable_scope"
reuse: [Boolean], If to reuse the weights of a previous layer by the same name
Returns:
A 3-dimensions tensor with shape of [N, T_q, S]
'''
""" queries = self.enc (batch_size, 10 ,512)==[N, T_q, S] keys也是self.enc
num_units =512, num_heads =10
"""
with tf.variable_scope(scope, reuse = reuse):
if num_units is None:
# length of sentence
num_units = queries.get_shape().as_list()[-1]
""" Linear layers in Figure 2(right) 就是Q、K、V进入scaled Dot-product Attention前的Linear的操作
# 首先是进行了全连接的线性变换
shape = [N, T_q, S] (batch_size, 10 ,512), S可以理解为512"""
Q = tf.layers.dense(queries, num_units, activation = tf.nn.relu)
# shape = [N, T_k, S]
K = tf.layers.dense(keys, num_units, activation = tf.nn.relu)
# shape = [N, T_k, S]
V = tf.layers.dense(keys, num_units, activation = tf.nn.relu)
'''
Q_、K_、V_就是权重WQ、WK、WV。
shape (batch_size*8, 10, 512/8=64)
'''
# Split and concat
# shape = [N*h, T_q, S/h]
Q_ = tf.concat(tf.split(Q, num_heads, axis = 2), axis = 0)
# shape = [N*h, T_k, S/h]
K_ = tf.concat(tf.split(K, num_heads, axis = 2), axis = 0)
# shape = [N*h, T_k, S/h]
V_ = tf.concat(tf.split(V, num_heads, axis = 2), axis = 0)
# [N, T_q, S] * [N*h, T_k, S/h] 这一步的张量乘法是怎么做的?
# shape = [N*h, T_q, T_k] Q
outputs = tf.matmul(Q_, tf.transpose(K_, [0, 2, 1]))
# Scale
outputs = outputs / (K_.get_shape().as_list()[-1] ** 0.5)
# Masking
# shape = [N, T_k]
# 这里的tf.reduce_sum进行了降维,由三维降低到了2维度,然后是取绝对值,转成0-1之间的值
'''[N, T_k, 512]------> [N, T_k] -----》[N*h, T_k] -----》[N*h, T_q, T_k] '''
key_masks = tf.sign(tf.abs(tf.reduce_sum(keys, axis = -1)))
# shape = [N*h, T_k]
key_masks = tf.tile(key_masks, [num_heads, 1])
# shape = [N*h, T_q, T_k] tf.expand_dims就是扩维度
key_masks = tf.tile(tf.expand_dims(key_masks, 1), [1, tf.shape(queries)[1], 1])
# If key_masks == 0 outputs = [1]*length(outputs)
paddings = tf.ones_like(outputs) * (-math.pow(2, 32) + 1)
# shape = [N*h, T_q, T_k]
outputs = tf.where(tf.equal(key_masks, 0), paddings, outputs)
if causality: #如果为true的话,那么就是将这个东西未来的units给屏蔽了
# reduce dims : shape = [T_q, T_k]
diag_vals = tf.ones_like(outputs[0, :, :])
# shape = [T_q, T_k]
# use triangular matrix to ignore the affect from future words
# like : [[1,0,0]
# [1,2,0]
# [1,2,3]]
tril = tf.contrib.linalg.LinearOperatorTriL(diag_vals).to_dense()
# shape = [N*h, T_q, T_k]
masks = tf.tile(tf.expand_dims(tril, 0), [tf.shape(outputs)[0], 1, 1])
paddings = tf.ones_like(masks) * (-math.pow(2, 32) + 1)
# shape = [N*h, T_q, T_k]
outputs = tf.where(tf.equal(masks, 0), paddings, outputs)
# Output Activation
outputs = tf.nn.softmax(outputs)
# Query Masking
# shape = [N, T_q]
query_masks = tf.sign(tf.abs(tf.reduce_sum(queries, axis = -1)))
# shape = [N*h, T_q]
query_masks = tf.tile(query_masks, [num_heads, 1])
# shape = [N*h, T_q, T_k]
query_masks = tf.tile(tf.expand_dims(query_masks, -1), [1, 1, tf.shape(keys)[1]])
outputs *= query_masks
# Dropouts
outputs = tf.layers.dropout(outputs, rate = dropout_rate, training = tf.convert_to_tensor(is_training))
# Weighted sum
# shape = [N*h, T_q, S/h]
outputs = tf.matmul(outputs, V_)
# Restore shape
# shape = [N, T_q, S]
outputs = tf.concat(tf.split(outputs, num_heads, axis = 0), axis = 2)
# Residual connection
outputs += queries
# Normalize
# shape = [N, T_q, S]
outputs = normalize(outputs)
return outputs
参考文章
1、哈佛nlp组pytorch实现的transformer
http://nlp.seas.harvard.edu/2018/04/03/attention.html
2、github上高星的实现代码
https://github.com/Kyubyong/transformer
3、简书中代码注释
https://www.jianshu.com/p/923c8b489604
4、关于transformer中attention种类的说明
https://www.jianshu.com/p/c18f1b0b35fb