MongoDB数据模型
MongoDB-Data Model
- 数据模型设计
- Embedded Data Models 内嵌数据模型
- 文档大小限制
- Normalized Data Models 规范化数据模型
- MongoDB特性与数据模型
- 原子性
- 分片
- 索引
- 大量的集合
- 数据模型的例子和范式
- 文档关系建模
- 一对一关系建模:内嵌文档
- 一对多关系建模
- 一对多关系建模: 引用模式
- 树型关系建模
- 父文档引用
- 子文档引用
- 祖先数组
- 物化路径
- Nested Sets 嵌套集合
- 具体应用建模
- 原子性事务建模
- 关键词搜索建模
- 数据库引用
- 手动引用
- DBRefs
与SQL数据库在插入数据之前必须确定并声明表的模式不同,MongoDB的集合不要求其文档具有相同的模式:
- 单个集合中的文档不需要具有相同的字段集,并且字段的数据类型可以在集合中的文档之间不同。
- 要更改集合中文档的结构(例如添加新字段,删除现有字段或将字段值更改为新类型),请将文档更新为新结构。
这种灵活性有助于将文档映射到实体或对象。即使文档与集合中的其他文档有很大差异,每个文档也可以匹配所表示实体的数据字段。
数据模型设计
设计基于MongoDB的应用程序的数据模型时的关键就是选择合适的文档结构以及确定应用程序如何描述数据之间的关系。有两种方式可以用来描述这些关系: 引用及内嵌
Embedded Data Models 内嵌数据模型
内嵌方式指的是把相关联的数据保存在同一个文档结构之内。MongoDB的文档结构允许一个字段或者一个数组内的值为一个嵌套的文档。这种 冗余 的数据模型可以让应用程序在一个数据库操作内完成对相关数据的读取或修改。这样一来,应用程序就可以发送较少的请求给MongoDB数据库来完成常用的查询及更新请求。

一般来说,下述情况建议使用内嵌数据:
- 数据对象之间有
contains(包含)关系。 参见一对一关系建模:内嵌文档模型。 - 数据对象之间有
一对多的关系。 这些情况下 “多个”或者子文档会经常和父文档一起被显示和查看。请参见 一对多关系建模: 内嵌文档模型。
通常情况下,内嵌数据会对读操作有比较好的性能提高,也可以使应用程序在一个单个操作就可以完成对数据的读取。 同时,内嵌数据也对更新相关数据提供了一个原子性写操作。
文档大小限制
MongoDB中的文档必须小于最大BSON文档大小。对于批量二进制数据,请考虑GridFS。
Normalized Data Models 规范化数据模型
规范化数据模型指的是通过使用引用来表达对象之间的关系。
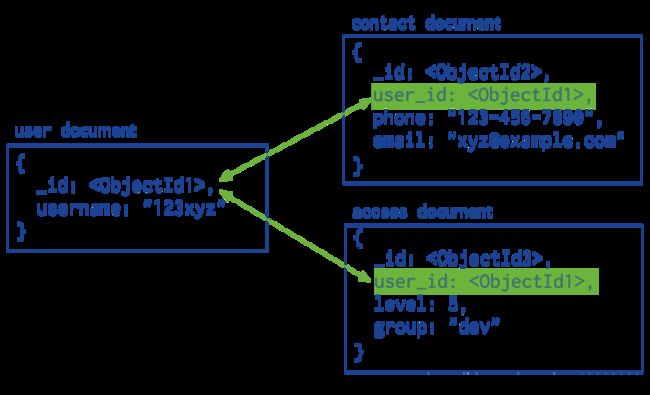
一般来说,在下述情况下可以使用规范化模型:
- 当内嵌数据会导致很多数据的
重复,并且读性能的优势又不足于盖过数据重复的弊端时候。 - 需要表达比较复杂的
多对多关系的时候。 - 大型
多层次结构数据集。
引用比内嵌要更加灵活一些。 但客户端应用必须使用二次查询来解析文档内包含的引用。换句话说,对同样的操作来说,规范化模式会导致更多的网络请求发送到数据库服务器端。
MongoDB特性与数据模型
MongoDB设计数据模型应考虑影响MongoDB性能的各种操作因素。 例如,不同的数据模型可以允许更有效的查询,增加插入和更新操作的吞吐量,或者更有效地将活动分配给分片集群。
在开发数据模型时,请结合以下注意事项分析所有应用程序的读写操作。
原子性
在MongoDB中,即使操作修改单个文档中的多个嵌入文档,写操作在单个文档的级别上也是原子操作。当单个写操作修改多个文档(例如db.collection.updateMany())时,每个文档的修改都是原子的,但整个操作不是原子操作。
把相关数据定义到同一个文档里面的内嵌方式有利于这种原子性操作。对于那些使用引用来关联相关数据的数据模型,应用程序必须再用额外的读和写的操作去取回和修改相关的数据。
- 内嵌数据模型
嵌入式数据模型将所有相关数据组合在单个文档中,而不是跨多个文档和集合进行规范化。该数据模型有助于原子操作。 - 多文档事务
对于存储相关数据片段之间的引用的数据模型,应用程序必须发出单独的读取和写入操作以检索和修改这些相关的数据片段。从版本4.0开始,对于需要原子性来更新多个文档或读取多个文档之间的一致性的情况,MongoDB为副本集提供了多文档事务。
分片
MongoDB 使用 sharding (分片)来实现水平扩展。使用分片的集群可以支持海量的数据和高并发读写。用户可以使用分片技术把一个数据库内的某一个集合的数据进行分区,从而达到把数据分布到多个 mongod 实例(或分片上)的目的。
Mongodb 依据分片键分发数据和应用程序的事务请求。选择一个合适的分片键会对性能有很大的影响,也会促进或者阻碍MongoDB的定向分片查询和增强的写性能。所以在选择分片键时候要仔细考量分片键所用的字段。
索引
对常用操作可以使用索引来提高性能。对查询条件中常见的字段,以及需要排序的字段创建索引。MongoDB会对 _id 字段自动创建唯一索引。
创建索引时,需要考虑索引的下述特征:
- 每个索引至少需要8 kB的数据空间。
- 添加索引会对写入操作产生一些负面的性能影响。 对于具有高写入读取比率的集合,索引的代价很大,因为每个插入也必须更新任何索引。
- 具有高读写比的集合通常受益于其他索引。 索引不会影响未设置索引的读取操作。
- 每个索引都会占一定的硬盘空间和内存(对于活跃的索引)。索引有可能会用到很多这样的资源,因此对这些资源要进行管理和规划,特别是在计算热点数据大小的时候。
大量的集合
在某些情况下,你可能会考虑把相关的数据保存到多个而不是一个集合里面。
一般来说,很大的集合数量对性能没有什么影响,反而在某些场景下有不错的性能。使用不同的集合在高并发批处理场景下会有很好的帮助。
当使用有大量集合的数据模型时,请注意一下几点:
- 每一个集合有几个KB的额外开销
- 每个索引至少需要8kB的数据空间
- 每一个MongoDB的 database 有一个且仅一个命名文件(namespace file)(i.e. .ns) 。这个命名文件保存了数据库的所有元数据。每个索引和集合在这个文件里都有一条记录。这个文件的大小是有限制的
For the MMAPv1 storage engine, namespace files can be no larger than
2047 megabytes. By default namespace files are 16 megabytes. You can
configure the size using the nsSize option. The WiredTiger storage
engine is not subject to this limitation.
数据模型的例子和范式
文档关系建模
一对一关系建模:内嵌文档
考虑顾客和顾客地址的关系模型,使用引用的方式建模
{
_id: "joe",
name: "Joe Bookreader"
}
{
patron_id: "joe",
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "12345"
}
而使用内嵌方式建模:
{
_id: "joe",
name: "Joe Bookreader",
address: {
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "12345"
}
}
如果地址address信息经常和顾客的name字段一起被查询,很明显使用内嵌关系更好,应用程序不需要发出额外的请求去解析并读取父文档。
一对多关系建模
针对顾客和地址的一对多的关系建模。使用引用关系建模,address 文档包含一个对父文档 patron 的引用。
{
_id: "joe",
name: "Joe Bookreader"
}
{
patron_id: "joe",
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "12345"
}
{
patron_id: "joe",
street: "1 Some Other Street",
city: "Boston",
state: "MA",
zip: "12345"
}
同样如果地址address信息经常和顾客的name字段一起被查询,使用内嵌关系建模,把 address 数据直接内嵌到 patron 文档里面
{
_id: "joe",
name: "Joe Bookreader",
addresses: [
{
street: "123 Fake Street",
city: "Faketon",
state: "MA",
zip: "12345"
},
{
street: "1 Some Other Street",
city: "Boston",
state: "MA",
zip: "12345"
}
]
}
一对多关系建模: 引用模式
针对于出版社和书籍关系建模
如果使用内嵌关系建模:
{
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher: {
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
}
{
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher: {
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
}
像这样把出版社信息内嵌到每一个书籍记录里面会导致出版社信息的很多次重复。
{
name: "O'Reilly Media",
founded: 1980,
location: "CA",
books: [123456789, 234567890, ...]
}
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English"
}
{
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English"
}
使用文档引用的方式,把出版社的信息保存在一个单独的集合里面。
当使用引用时,文档关系的数量级及增长性会决定我们要在哪里保存引用信息。如果每个出版社所出版的书的数量比较小并且不会增长太多,那么可以在出版社文档里保存所有该出版社所出版的书的引用。反之,如果每个出版社所出版的书籍数量很多或者可能增长很快那么这个书籍引用数组就会不断增长,如下所示:
{
name: "O'Reilly Media",
founded: 1980,
location: "CA",
books: [123456789, 234567890, ...]
}
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English"
}
{
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English"
}
要避免可变的增长数组,请将出版社信息引用到书籍文档中:
{
_id: "oreilly",
name: "O'Reilly Media",
founded: 1980,
location: "CA"
}
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher_id: "oreilly"
}
{
_id: 234567890,
title: "50 Tips and Tricks for MongoDB Developer",
author: "Kristina Chodorow",
published_date: ISODate("2011-05-06"),
pages: 68,
language: "English",
publisher_id: "oreilly"
}
树型关系建模
使用的树型分支结构:

父文档引用
父文档引用 模式用一个文档来表示树的一个节点。每一个文档除了存储节点的信息,同时也保存该节点父节点文档的id值。
下面是一个使用 父文档引用 的例子。在 parent 字段里保存了对上一级分类的引用
db.categories.insert( { _id: "MongoDB", parent: "Databases" } )
db.categories.insert( { _id: "dbm", parent: "Databases" } )
db.categories.insert( { _id: "Databases", parent: "Programming" } )
db.categories.insert( { _id: "Languages", parent: "Programming" } )
db.categories.insert( { _id: "Programming", parent: "Books" } )
db.categories.insert( { _id: "Books", parent: null } )
- 如果要查询父节点:
db.categories.findone({_id:"MomgoDb"}).parent
- 可以对 parent 字段建索引,这样可以快速的按父节点查找:
db.categories.createIndex( { parent: 1 } )
- 使用parent字段可以快速查询到父节点的所有直接子节点:
db.categories.find( { parent: "Databases" } )
子文档引用
子文档引用 模式用一个文档来表示树的一个节点。每一个文档除了存储节点的信息,同时也用一个数组来保存该节点所有子节点的id值。还是上面的树型结构。
使用子文档引用,在父文档的 children 字段里保存了对所有下一级分类节点的引用。
db.categories.insert( { _id: "MongoDB", children: [] } )
db.categories.insert( { _id: "dbm", children: [] } )
db.categories.insert( { _id: "Databases", children: [ "MongoDB", "dbm" ] } )
db.categories.insert( { _id: "Languages", children: [] } )
db.categories.insert( { _id: "Programming", children: [ "Databases", "Languages" ] } )
db.categories.insert( { _id: "Books", children: [ "Programming" ] } )
- 可以快速直接地查询子节点:
db.categories.findone({_id:"Database"}).children
- 对children字段建立索引,方便快速的按子节点查找:
db.categories.createIndex( { children: 1 } )
- 通过 children 字段很快的找到一个节点的父节点以及同级的节点:
db.categories.find({children:"MongoDB"})
祖先数组
祖先数组 模式用一个文档来表示树的一个节点。每一个文档除了存储节点的信息,同时也存储了对父文档及祖先文档的id值。
db.categories.insert( { _id: "MongoDB", ancestors: [ "Books", "Programming", "Databases" ], parent: "Databases" } )
db.categories.insert( { _id: "dbm", ancestors: [ "Books", "Programming", "Databases" ], parent: "Databases" } )
db.categories.insert( { _id: "Databases", ancestors: [ "Books", "Programming" ], parent: "Programming" } )
db.categories.insert( { _id: "Languages", ancestors: [ "Books", "Programming" ], parent: "Programming" } )
db.categories.insert( { _id: "Programming", ancestors: [ "Books" ], parent: "Books" } )
db.categories.insert( { _id: "Books", ancestors: [ ], parent: null } )
ancestors字段按级存储了先祖节点,parent字段则保存对父节点的引用
- 查询一个节点所有祖先节点或者从根节点到某个节点的路径的操作很快很方便:
db.categories.findOne( { _id: "MongoDB" } ).ancestors
- 对ancestors字段创建索引,方便搜索先祖节点
db.categories.createIndex( { ancestors: 1 } )
- 使用 ancestors 字段来查找某个节点所有的子代节点
db.categories.find( { ancestors: "Programming" } )
物化路径
物化路径模式将每个树节点存储在文档中; 除了树节点之外,文档还将节点的祖先或路径的id存储为字符串。 虽然物化路径模式需要使用字符串和正则表达式的其他步骤,但该模式还为处理路径提供了更大的灵活性,例如通过部分路径查找节点。
物化路径来建模的例子。在节点文档中的 path 字段保存了以逗号为分隔符的路径字符串:
db.categories.insert( { _id: "Books", path: null } )
db.categories.insert( { _id: "Programming", path: ",Books," } )
db.categories.insert( { _id: "Databases", path: ",Books,Programming," } )
db.categories.insert( { _id: "Languages", path: ",Books,Programming," } )
db.categories.insert( { _id: "MongoDB", path: ",Books,Programming,Databases," } )
db.categories.insert( { _id: "dbm", path: ",Books,Programming,Databases," } )
- 可以查询整个树的所有节点并按 path 排序:
db.categories.find().sort( { path: 1 } )
- 可以在 path 字段上使用正则表达式来查询 Programming 的所有子代节点:
db.categories.find( { path: /,Programming,/ } )
- 也可以查询到根节点 Books 的所有子代节点:
db.categories.find( { path: /^,Books,/ } )
- path字段的索引
db.categories.createIndex( { path: 1 } )
这个索引对某些查询的性能会有所提高:
如果从根节点开始查询,如( /^,Books,/ )或 (/^,Books,Programming,/) path 字段上的索引会对提高查询性能有显著的作用。
如果查询类似于 Programming 这些非根节点下面的子代节点, (/,Databases,/)或类似的子树查询,由于这些被查询的节点可能在索引字符串的中部而导致全索引扫描。
对于这些查询,如果索引明显小于整个集合,则索引可以提供一些性能改进。
Nested Sets 嵌套集合
嵌套集合 模式对整个树结构进行一次深度优先的遍历。遍历时候对每个节点的压栈和出栈作为两个不同的步骤记录下来。然后每一个节点就是一个文档,除了节点信息外,文档还保存父节点的id以及遍历的两个步骤编号。压栈时的步骤编号保存到 left 字段里, 而出栈时的步骤编号则保存到 right 字段里。
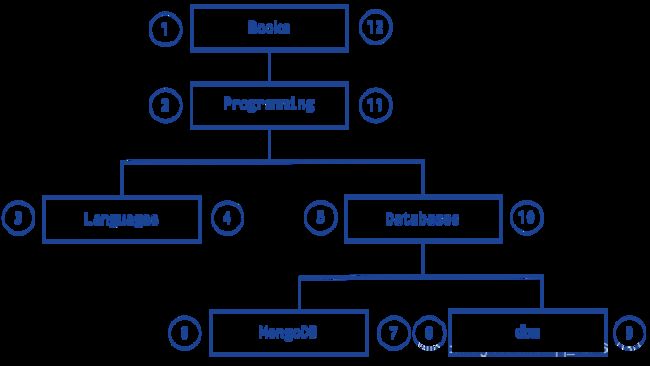
使用嵌套集合的例子:
db.categories.insert( { _id: "Books", parent: 0, left: 1, right: 12 } )
db.categories.insert( { _id: "Programming", parent: "Books", left: 2, right: 11 } )
db.categories.insert( { _id: "Languages", parent: "Programming", left: 3, right: 4 } )
db.categories.insert( { _id: "Databases", parent: "Programming", left: 5, right: 10 } )
db.categories.insert( { _id: "MongoDB", parent: "Databases", left: 6, right: 7 } )
db.categories.insert( { _id: "dbm", parent: "Databases", left: 8, right: 9 } )
查询某个节点的子代节点:
var databaseCategory = db.categories.findOne( { _id: "Databases" } );
db.categories.find( { left: { $gt: databaseCategory.left }, right: { $lt: databaseCategory.right } } );
嵌套集模式为查找子树提供了快速有效的解决方案,但对于可修改的树结构效率很低。 因此,此模式最适用于不更改的静态树。
具体应用建模
原子性事务建模
尽管MongoDB支持从4.0版本开始的多文档事务,但对于许多场景,非规范化数据模型将继续为您的数据和用例提供最佳选择。
在MongoDB中,对单个文档的写操作是原子的。 对于必须一起更新的字段,在同一文档中嵌入字段可确保可以原子方式更新字段。
举例来说,假设你在设计一个图书馆的借书系统,需要管理书的库存量以及出借记录。
一本书的可借数量加上借出数量的和必须等于总的保有量,那么对这两个字段的更新必须是原子性的。把 available 和 checkout 两个字段放到同一个文档里,就可以做到对这两个字段的原子性事务。
{
_id: 123456789,
title: "MongoDB: The Definitive Guide",
author: [ "Kristina Chodorow", "Mike Dirolf" ],
published_date: ISODate("2010-09-24"),
pages: 216,
language: "English",
publisher_id: "oreilly",
available: 3,
checkout: [ { by: "joe", date: ISODate("2012-10-15") } ]
}
在更新出借记录的时候,你可以用 db.collection.update() 的方法来对 available 和 checkout 两个字段同时更新:
db.books.updateOne (
{ _id: 123456789, available: { $gt: 0 } },
{
$inc: { available: -1 },
$push: { checkout: { by: "abc", date: new Date() } }
}
)
关键词搜索建模
如果应用需要对某个文本字段进行查询,可以用完全匹配或使用正则表达式 $regex 。但是很多情境下这些手段不能够满足应用的需求。
下面这个范式介绍了一种在同一个文档内使用数组来保存关键词再对数组建多键索引 (multi-key index)的方式来实现关键词搜索。
为实现关键词搜索,在文档内增加一个数组字段并把每一个关键词加到数组里。然后你可以对该字段建一个多键索引。这样就可以对数组里面的关键词进行查询了。
假如你希望对图书馆的藏书实现一个按主题搜索的功能。 对每一本书,你可以加一个数组字段 topics 并把这本书相关的主题都加到这个数组里。
对于 Moby-Dick 这本书你可能会有以下这样的文档:
{ title : "Moby-Dick" ,
author : "Herman Melville" ,
published : 1851 ,
ISBN : 0451526996 ,
topics : [ "whaling" , "allegory" , "revenge" , "American" ,
"novel" , "nautical" , "voyage" , "Cape Cod" ]
}
然后对 topics 数组字段建多键索引:
db.volumes.createIndex( { topics: 1 } )
多键索引会对数组里的每一个值建立一个索引项。在这个例子里 whaling 和 allegory 个各有一个索引项。
现在你可以按关键词进行搜索,如:
db.volumes.findOne( { topics : "voyage" }, { title: 1 } )
注意
如果数组较大,达到几百或者几千以上的关键词,那么文档插入操作时的索引维护开支会大大增加。
关键词索引的局限:
- 词干。 MongoDB中的关键字查询无法解析根或相关单词的关键字。
- 同义词。 基于关键字的搜索功能必须为应用层中的同义词或相关查询提供支持。
- 排行。 本文档中描述的关键字查找不提供加权结果的方法。
- 异步索引。 MongoDB同步构建索引,这意味着用于关键字索引的索引始终是最新的,并且可以实时运行。 但是,异步批量索引对于某些类型的内容和工作负载可能更有效。
数据库引用
对于MongoDB中的许多用例,相关数据存储在一个文档中的非规范化数据模型(Embedded Data Model)将是最佳的。 但是,在某些情况下,将相关信息存储在单独的文档中是有意义的,通常是在不同的集合或数据库中。
MongoDB 引用有两种:
- 手动引用(Manual References)将一个文档的
_id字段保存在另一个文档中作为参考。然后您的应用程序可以运行第二个查询以返回相关数据。对于大多数用例,这些引用很简单且足够。 - DBRefs 是使用第一个文档的
_id字段,集合名称以及(可选)其数据库名称的值从一个文档到另一个文档的引用。通过包含这些名称,DBRefs允许位于多个集合中的文档更容易与来自单个集合的文档链接。
要解析DBRefs,您的应用程序必须执行其他查询才能返回引用的文档。许多驱动程序都有辅助方法,可以自动形成DBRef的查询。驱动程序不会自动将DBRef解析为文档。
DBRefs提供了一种通用格式和类型来表示文档之间的关系。如果数据库必须与多个框架和工具交互,则DBRef格式还提供用于表示文档之间链接的通用语义。
除非一定要使用DBRefs,使用手动引用即可满足要求。
手动引用
> original_id = ObjectId()
ObjectId("5c0c74fea1533dab560fd06b")
>db.sites.insert({"_id":original_id,"name":"baidu","url":"www.baidu.com"})
WriteResult({ "nInserted" : 1 })
> db.profile.insert({"name":"Rin", "site_id":original_id, "url":"www.baidu.com/Rin"})
WriteResult({ "nInserted" : 1 })
>
对于几乎所有要在两个文档之间存储关系的情况,请使用手动引用。 引用很容易创建,您的应用程序可以根据需要解析引用。
手动链接的唯一限制是这些引用不传达数据库和集合名称。 如果单个集合中的文档与多个集合中的文档相关,则可能需要考虑使用DBRefs。
DBRefs
DBRefs是表示文档的规范,而不是特定的引用类型。它们包括集合的名称,在某些情况下还包括数据库名称,以及_id字段中的值。
格式:
$ref:$ref字段包含引用文档所在的集合的名称。$id:$id字段包含引用文档中_id字段的值。$db: 可选的,包含引用文档所在的数据库的名称。只有一些驱动程序支持$ db引用。
> use test
switched to db test
> db.student.insert({"name":'Rin', "address":{"$ref":"sites", "$id":1, "$db":"first_demo"}})
WriteResult({ "nInserted" : 1 })
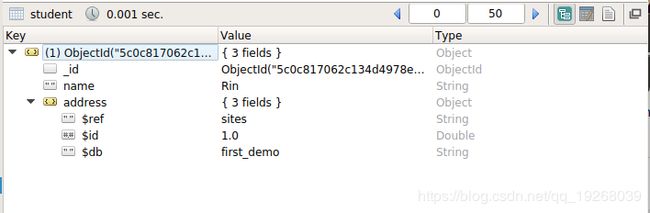
查询:
> var profile = db.profile.findOne({"name":"Tom"})
> var dbRef = profile.address
> db[dbRef.$ref].findOne({"_id":(dbRef.$id)})
{ "_id" : 2, "name" : "Tom", "num" : 1233 }