OpenCV3+Python实现人脸检测与识别项目
一:环境
OpenCV3、Python3.6;IDE:pycharm5.0.3
依赖的库与模块:PIL(Python imaging library)、cv2、numpy、os、speech等
二:项目文件列表
1、cascades文件夹;在安装OpenCV时OpenCV3源代码副本中会存在一个文件夹data\haarcascades
(默认文件路径在:(本地路径)
C:\Users\John\AppData\Local\Programs\Python\Python36-32\Lib\site-packages\opencv\sources\data\haarcascades);
2、data文件夹(用于存储人脸数据信息,用来训练模型)
3、生成人脸图像数据的脚本:generate_image_data.py
4、人脸数据图像训练模型,使模型有学习功能:imagedata_train.py
5、人脸识别脚本:face_recognition.py
三、代码
1、生成人脸图像数据
generate_image_data.py
# -*- coding : utf-8 -*-
# Author: Tom Yu
import cv2
import os
#创建camera对象,获取默认视频帧
camera = cv2.VideoCapture(0)
#生成图像数据
def generate():
name = input("请输入你的名字:")#输入需要录入人脸图像数据的名称
isExists = os.path.exists(r"./data/%s/"%name)#os.path.exists()检测路径是否存在,如存在返回True
if isExists:
new_name = input("你输入的名字已存在,请重新输入:")
os.makedirs(r"./data/%s/"%new_name)
else:
os.makedirs(r"./data/%s/"%name)#os.makedirs(path)创建目录,os.mkdir()在当前目录下创建目录文件
cascade_path = r"./cascades"
#创建级联分类器,加载cascades文件夹内的xml特征数据
face_cascade = cv2.CascadeClassifier(cascade_path+"/haarcascade_frontalface_default.xml")
count = 0
while True:
ret,frame = camera.read()
gray = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray,1.1,3)#参数1:需为灰度图像;参数2:图像检测放大比例一般为1.1;参数3:被检测到的次数
if len(faces)>1:#判断被检测到的人脸数目,如果窗口中出现两个人脸数据,会提示只能输入一个人脸数据
cv2.putText(frame,"Only One Face In The Windows!",
(20,20),cv2.FONT_HERSHEY_COMPLEX,1,(0,0,255),1)
else:
for (x,y,w,h) in faces:
#在检测到的人脸周边画出边框
cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),3)
#此处获取图像人脸数据ROI,区域为[y:y+h,x:x+w],不知为何是反过来的,frame[x:x+w,y:y+h]获取不到人脸图像,可能是因为镜像原因
f_color = frame[y:y+h,x:x+w]
#将获取到的人脸图像数据保存为200*200的数据图像
f = cv2.resize(cv2.cvtColor(f_color,cv2.COLOR_BGR2GRAY),(200,200))
#cv2.imwrite(r"./data/%s/%s.pgm"%(name,str(count)),f)
#因为cv2.imwrite()无法写入含有中文路径的图片文件,可用cv2.imencode()函数,cv2.imencode()会返回两个值,ret、图像数组
cv2.imencode(".pgm",f)[1].tofile(r"./data/%s/%s.pgm"%(name,str(count)))
count += 1
cv2.imshow("camera",frame)
k = cv2.waitKey(int(1000/12))&0xff
if k == 27 or count == 50:#获取图像数据只有50张图片,可自行设置更多
break
camera.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
generate()小案例:
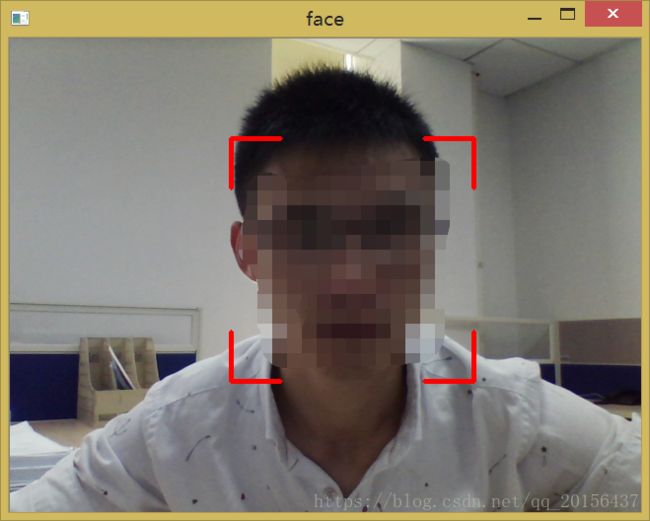
人脸检测出来画出的边框是宽度一致的边框,想画出更专业一点的四个角点边框线更粗一些的边框,可通过下面代码实现:
# -*- coding : utf-8 -*-
# Author: Tom Yu
import cv2
cap = cv2.VideoCapture(0)
def face_detect():
face_cascade = cv2.CascadeClassifier(r"G:\Python_work\FaceRecognizition\cascades\haarcascade_frontalface_default.xml")
while True:
ret,frame = cap.read()
gray_frame = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray_frame,1.1,5)
for (x,y,w,h) in faces:
#cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),1)
cv2.line(frame,(x,y),(x+50,y),(0,0,255),4)
cv2.line(frame,(x,y),(x,y+50),(0,0,255),4)
cv2.line(frame,(x+w,y),(x+w,y+50),(0,0,255),4)
cv2.line(frame,(x+w,y),(x+w-50,y),(0,0,255),4)
cv2.line(frame,(x,y+h),(x+50,y+h),(0,0,255),4)
cv2.line(frame,(x,y+h),(x,y+h-50),(0,0,255),4)
cv2.line(frame,(x+w,y+h),(x+w,y+h-50),(0,0,255),4)
cv2.line(frame,(x+w,y+h),(x+w-50,y+h),(0,0,255),4)
cv2.imshow("face",frame)
k = cv2.waitKey(int(1000/12))&0xff
if k == 27:
break
cap.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
face_detect()实现效果如下图:
2.建立图像数组与标签数组
建立可以训练模型的图像数组数据和标签数据;实现类似于“JACK”图像数据文件夹对应标签“0”。如图:

imagedata_train.py
# -*- coding : utf-8 -*-
# Author: Tom Yu
import cv2
import os
import numpy as np
def image_read(path):
count = 0
X,y = [],[]#创建两个空列表,一个存储图像数据,一个存储与之相对应的标签数组
for dirname, dirnames, filenames in os.walk(path):#os.walk()遍历所在目录下的所有目录及文件,可百度学习
for subdirname in dirnames:
subdirname_path = os.path.join(path,subdirname)
for filename in os.listdir(subdirname_path):#os.listdir()列出所在目录下的所有文件夹名和文件名
try:
if not filename.endswith(".pgm"):#判断文件是否以.pgm结尾
continue
filepath = os.path.join(subdirname_path,filename)
#im = cv2.imread(filepath,cv2.IMREAD_GRAYSCALE)
#因为cv2.imread()无法读取含有中文路径的图片文件,可用cv2.imdecode()函数
im = cv2.imdecode(np.fromfile(filepath,dtype=np.uint8),-1)
X.append(np.asarray(im,np.uint8))
y.append(count)
except:
pass
count += 1
return [X,y]
"""
if __name__ == "__main__":
image_read(r".\data")
"""
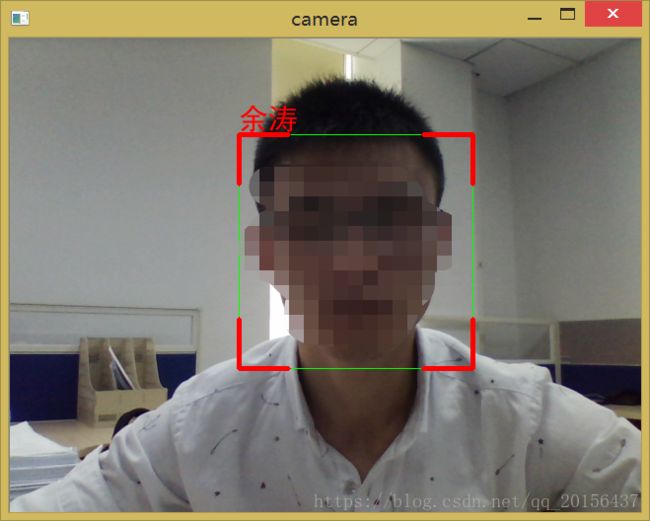
3、检测出现在视频中的人脸并识别,在识别的窗口上方显示文字
face_recognition.py
# -*- coding : utf-8 -*-
# Author: Tom Yu
import cv2
import os
import numpy as np
import speech#导入speech模块,将文本转为语音输出
from PIL import Image,ImageFont,ImageDraw
import imagedata_train
def face_rec(data_path):
names = []
for name in os.listdir(data_path):
names.append(name)
[X,y] = imagedata_train.image_read(data_path)
y = np.asarray(y,np.int32)
model = cv2.face.LBPHFaceRecognizer_create()#创建人脸识别模型,有三种分别为:eigenfaces、fisherfaces、LBPH(检测效果最好)
model.train(np.asarray(X),np.asarray(y))
camera = cv2.VideoCapture(0)
face_cascade = cv2.CascadeClassifier(r"./cascades/haarcascade_frontalface_default.xml")
sc = 0
while True:
ret,frame = camera.read()
faces = face_cascade.detectMultiScale(cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY),1.1,5)
for (x,y,w,h) in faces:
rect = cv2.rectangle(frame,(x,y),(x+w,y+h),(0,255,0),3)
gray = cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
roi = gray[x:x+w,y:y+h]
try:
roi = cv2.resize(roi,(200,200))
params = model.predict(roi)
print("Label:%s,Confidence:%.2f"%(params[0],params[1]))
#追加代码2018/9/28 起始位置
pil_frame = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB)
pilframe = Image.fromarray(pil_frame)
draw = ImageDraw.Draw(pilframe)
font = ImageFont.truetype("simhei.ttf",30,encoding="utf-8")
draw.text((x,y-30),names[params[0]],(255,0,0),font=font)
frame = cv2.cvtColor(np.array(pilframe),cv2.COLOR_RGB2BGR)
#结束为止
#cv2.putText(frame,names[params[0]],(x,y-20),cv2.FONT_HERSHEY_COMPLEX,1,(0,0,255),3)
#因cv.putText()不支持显示中文汉字,PIL图像处理库可实现
if (sc%10) == 0:#每循环10次就输出一次语音
speech.say("你好!%s,欢迎你!"%(names[params[0]]))#将识别出的人脸语音输出
sc += 1
except:
continue
cv2.imshow("camera",frame)
k=cv2.waitKey(int(1000/12))&0xff
if k == 27:
break
camera.release()
cv2.destroyAllWindows()
"""
cv2.imshow("camera",frame)
k = cv2.waitKey(int(1000/12))&0xff
if k == 27:
break
camera.release()#碰到的一个坑,耗费3个多小时,camera.release()缩进要在while循环之外
cv2.destroyAllWindows()
"""
if __name__ == "__main__":
face_rec(r"G:\Python_work\face_detectandrecognization_programe\data")
四、实现效果