Kotlin Coroutines(协程)
Kotlin Coroutines(协程)
原文链接:https://blog.dreamtobe.cn/kotlin-coroutines/
发表 2017-08-20
在前面的文章,我们提到了kotlin的基本语法、为什么选用kotlin、根据《Effective Java》Kotlin语法层面的优化、kotlin单元测试编写以及kotlin对包大小影响、kotlin与Java对比运行时性能等,今天我们谈谈在Kotlin 1.1引入的强大且实用的Coroutines,本文详细介绍了Coroutines的概念与常见的使用场景。
I. 引入Coroutines
首先,Coroutines是一个单独的包,如果你是普通Java开发者,建议使用官方的教程进行引入,如果你和我一样是Android开发者,建议直接使用Anko-Coroutines):

本文所有案例均在kotlin 1.1.4与kotlinx-coroutines-core 0.18版本进行实验(由于我引入anko时,anko引用的coroutines时0.15版本因此这里引入0.18版本进行替换(至于为什么高版本会自动替换低版本可以参考这篇文章))。
从kotlin 1.3起,coroutine已经进入了1.0并且不再是experimental了,相关引入如下, 我们直接参照kotlinx.coroutines中,进行引入:
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-core:1.0.1"
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-android:1.0.1'
简单案例
我们使用kotlin 1.0.1版本做一个简单的案例,案例中我们在主线程中异步的执行一个耗时操作,然后再在最后弹一个Toast:
首先引入上面提到的kotlinx-coroutines-core与kotlinx-coroutines-android 两个依赖,然后在MainActivity中:
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?){
super.onCreate(savedInstanceState)
...
GlobalScope.launch(Dispatchers.Main) {
async(Dispatchers.IO) { delay(5000) }.await()
Toast.makeText(this@MainActivity, "finish async job but not block main thread", Toast.LENGTH_LONG).show()
}
}
}
II. 什么是Kotlin Coroutines
Coroutines中文名”协程”,简单来说就是使用suspend来代替线程阻塞,可以理解为无阻塞的异步编写方式,基本原理是使用更轻的协程来代替繁重的阻塞操作(为什么阻塞是繁重的,可以参考这篇文章),并且复用原本阻塞的线程资源。
综合C#、Lua等中的Coroutine对于suspend的翻译,文中为了便于理解,将suspend的操作(如delay)称为”挂起”。kotlin协程的挂起是十分廉价的,相反的线程的阻塞是十分昂贵的。
协程中每个coroutine都是运行在对应的CoroutineContext中的,为了便于理解,文中将CoroutineContext称为”coroutine上下文”。而coroutine上下文可以是为coroutine提供运行线程的CoroutineDispatcher(如newSingleThreadContext创建的单线程coroutine上下文、CommonPool公共的拥有与CPU核实相当线程数的线程池等),可以是用于管理coroutine的Job、甚至可以是继承自Job的可以为异步任务带回数返回值的的Deferred等。
Kotlin协程的特征
我们知道协程的概念并不是kotlin第一个提出的,在此之前已经有很多语言有协程的概念,但是kotlin协程有自己的特征:
- koltin的协程完全是通过编译实现的(不愧是IDE公司出的^ ^),没有修改JVM或者是底层逻辑
- 相比其他语言的协程,kotlin的协程可谓非常的全面,其不仅支持C#和
ECMAScript的async/await、Go的channels与select,还支持C#和Python的build sequence/yield等
本质
本质上,协程是在在用户态直接对线程进行管理,不同于线程池,协程进一步的管理了不同协程切换的上下文,协程间通讯,协程的挂起,相对于线程而言,协程更轻;在并行逻辑的发展进阶过程中,可以理解为进程->线程->协程。
下图我根据源码理解画的kotlin协程中对挂起的基本实现:

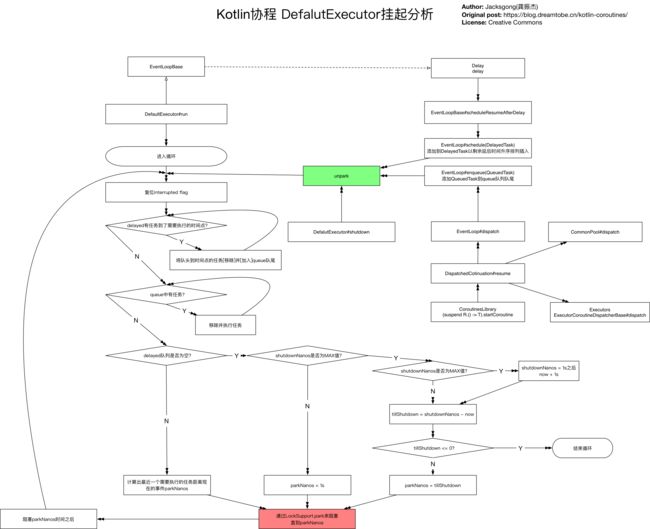
带来的好处
- 通过协程我们可以很简单的使用
async来让原本需要使用异步+回调的编写方式,可以通过看似同步的编写方式写代码 - 提供多种线程间通信的方式,如
channel,以及延伸出的producer、pipeline等 - 在多协程(原本的线程)管理方面更加灵活,如通过多个协程绑定同一
job进行全局管控 - 减少了所需要的线程数,由于使用协程的概念在用户态接管线程,完成各协程的调配,通过挂起代替阻塞,有效利用闲置的线程资源。
可能带来的问题
- 目前kotlin协程还处在试验期
- 生搬硬套会使得代码更加复杂
- 在一些场景上使用协程使得反复利用使用同一个线程,反而多核处理器的优势无法发挥
需要注意
我们可以通过目前kotlinx.coroutines所在包名(kotlin.coroutines.experimental)获知目前kotlin协程还是实验性的,并且根据官方文档,等到完全设计完成后最终API会移到kotlin.coroutines中,正因为这个原因,官方建议给基于协程API的包添加experimental后缀(如:cn.dreamtobe.experimental),等到最终发布后,再迁移到无experimental后缀的包中,并且官方表明会做兼容以最小化迁移成本。
III. 挂起是很轻的操作
我测试了如下两个代码(不过其实这块代码是一个极端情况,并且是体现挂起优势的代码):
// 使用协程
println("Coroutines: start")
val jobs = List(100_000) {
// 创建新的coroutine
launch(CommonPool) {
// 挂起当前上下文而非阻塞1000ms
delay(1000L)
println("." + Thread.currentThread().name)
}
}
jobs.forEach { it.join() }
println("Coroutines: end")
println("No Coroutines: start")
// 使用阻塞
val noCoroutinesJobs = List(100_000) {
// 创建新的线程
thread {
// 阻塞
Thread.sleep(1000L)
println("." + Thread.currentThread().name)
}
}
noCoroutinesJobs.forEach { it.join() }
println("No Coroutines: end")
在Nexus6P上:使用协程的大约在8s左右完成所有输出;而不使用协程的大约2min才完成所有输出

这里你可能会提出,这里很大程度是复用了线程?
是的,这就是协程的特性,使用挂起当前上下文替代阻塞,使得可以复用被delay的线程,大量减少了这块的资源浪费。
而使用阻塞的情况是,不断创建新的线程然后阻塞,因此哪怕是我们使用线程池,也无法复用其中的任何线程,由于这里所有的线程都被阻塞了。如果这块不明白,可以直接使用以下的代码,让阻塞的测试用例也跑在一个尽可能提供线程复用的常规线程池中,结果相同大约2min才完成所有输出:
val noCoroutinesPool: ExecutorService = Executors.newCachedThreadPool()
println("No Coroutines: start")
// 使用阻塞
val noCoroutinesJobs = List(100_000) {
Executors.callable {
Thread.sleep(1000L)
println("thread." + Thread.currentThread().name)
}
}
noCoroutinesPool.invokeAll(noCoroutinesJobs)
println("No Coroutines: end")
IV. 如何使用协程
run(CoroutineContext) { ... }: 创建一个运行在CoroutineContext制定线程中的区块,效果是运行在CoroutineContext线程中并且挂起父coroutine上下文直到区块执行完毕runBlocking(CoroutineContext) { ... }: 创建一个coroutine并且阻塞当前线程直到区块执行完毕,这个一般是用于桥接一般的阻塞试编程方式到coroutine编程方式的,不应该在已经是coroutine的地方使用launch(CoroutineContext) { ... }: 创建运行在CoroutineContext中的coroutine,返回的Job支持取消、启动等操作,不会挂起父coroutine上下文;可以在非coroutine中调用suspend fun methodName() { ... }: 申明一个suspend方法,suspend方法中能够调用如delay这些coroutine特有的非阻塞方法;需要注意的是suspend方法只能在coroutine中执行async(CoroutineContext) { ... }: 创建运行在CoroutineContext中的coroutine,并且带回返回值(返回的是Deferred,我们可以通过await等方式获得返回值)
1. fun methodName(...) = runBlocking { ... }
申明methodName方法是顶层主协程方法。一般是用于桥接一般的阻塞试编程方式到coroutine编程方式的,不应该在已经是coroutine的地方使用。
fun main(args: Array) = runBlocking {
val job = launch(CommonPool) {
// 挂起1000ms
delay(1000L)
}
// 接口含义同Thread.join只是这里是`suspension`
job.join()
}
// 编译失败案例
fun noRunBlocking(args: Array) {
val job = launch(CommonPool) {
delay(1000L)
}
// 这里会报Suspend function 'join' should be called only from a coroutine or another suspend function
job.join()
}
2. 在Coroutine中异步执行suspend方法
我们可以通过async在不同的Dispather提供的线程中运行以后,带回返回值,如下:
fun main(args: Array) = runBlocking {
// 计算总共需要执行多久,measureTimeMillis是kotlin标准库中所提供的方法
val time = measureTimeMillis {
val one = async(CommonPool) { doOne() } // 这里将doOne抛到CommonPool中的线程执行,并在结束时将结果带回来。
val two = async(CommonPool) { doTwo() } // 这里将doTwo抛到CommonPool中的线程执行,并在结束时将结果带回来。
println("The answer is ${one.await() + two.await()}") // 这里会输出6
}
println("${time}ms") // 由于doOne与doTwo在异步执行,因此这里输出大概是700ms
}
suspend fun doOne() : Int {
delay(500L)
return 1
}
suspend fun doTwo() : Int {
delay(700L)
return 5
}
如果你希望在有使用到async结果返回值的时候再执行里面的内容(有点类似lazy),只需要在构建async的时候传入CoroutineStart.LAZY作为start就可以了,比如:
val one = async(CommonPool, CoroutineStart.LAZY) { doOne() } // 这里将doOne将不会立马执行
println("${one.await()"} // 此时将会挂起当前上下文等待doOne执行完成,然后输出返回值
可以使用fun asyncXXX() = async(CommonPool) { ... } 申明一个异步的suspending方法,与launch(CommonPool)相同可以在非coroutine的区域调用。
fun asyncDoOne() = async(CommonPool) { // 创建在CommonPool这个线程池中的coroutine,并且会带回doOne的结果。
doOne()
}
fun main(args: Array) { // 普通方法
val one = asyncDoOne()
println("${one.await()}") // 输出doOne结果
}
3. 为Coroutine指定不同的线程(Dispaters)
在协程中包含了很多CoroutineDispatcher,这些Dispaters决定了Coroutine运行所在线程。比如:
Unconfined: 执行coroutine是在调用者的线程,但是当在coroutine中第一个挂起之后,后面所在的线程将完全取决于调用挂起方法的线程(如delay一般是由kotlinx.coroutines.DefaultExecutor中的线程调用)CoroutineScope#coroutineContext(旧版本这个变量名为context): 执行coroutine始终都是在coroutineContext所在线程(coroutineContext就是CoroutineScope的成员变量,因此就是CoroutineScope实例所在coroutine的线程),CommonPool: 执行coroutine始终都是在CommonPool(ForkJoinPool)线程池提供的线程中;使用CommonPool这个context可以有效使用CPU多核,CommonPool中的线程个数与CPU核数一样。newSingleThreadContext: 执行coroutine始终都是在创建的单线程中newFixedThreadPoolContext: 执行的coroutine始终都是在创建的fixed线程池中
如以下案例:
// 我们在主线程调用了main方法
fun main(args: Array) = runBlocking {
val jobs = arrayListOf()
jobs += launch(Unconfined) {
println(" 'Unconfined': I'm working in thread ${Thread.currentThread().name}") // 这里将在主线程访问
delay(500)
println(" 'Unconfined': After delay in thread ${Thread.currentThread().name}") // 这里将在DefaultExecutor中被访问
}
jobs += launch(coroutineContext) { // 父coroutine的coroutineContext, runBlocking的coroutine,因此始终在主线程
println("'coroutineContext': I'm working in thread ${Thread.currentThread().name}")
delay(1000)
println("'coroutineContext': After delay in thread ${Thread.currentThread().name}")
}
jobs.forEach { it.join() }
}
输出(我们可以很清晰的看到,使用coroutineContext的始终运行在主线程,而Unconfined的在挂起后在delay的调用线程DefaultExecutor执行):
'Unconfined': I'm working in thread main
'coroutineContext': I'm working in thread main
'Unconfined': After delay in thread kotlinx.coroutines.DefaultExecutor
'coroutineContext': After delay in thread main
在不同线程间跳跃
// 创建一个方法在输出前输出当前线程名
fun log(msg: String) = println("[${Thread.currentThread().name}] $msg")
val ctx1 = newSingleThreadContext("Ctx1")
val ctx2 = newSingleThreadContext("Ctx2")
runBlocking(ctx1) {
log("Started in ctx1")
delay(1000L)
run(ctx2) {
log("Working in ctx2")
delay(1000L)
}
log("Back to ctx1")
}
输出:
[Ctx1] Started in ctx1
[Ctx2] Working in ctx2
[Ctx1] Back to ctx1
run方法使得运行在父coroutine,但是是在Ctx2线程中执行区块,以此实现线程跳跃。
4. 对于Job的取消操作
我们知道launch返回回来的是一个Job用于控制其coroutine,并且我们也可以通过coroutineContext[Job]在在CoroutineScope中获取当前Job对象。
而对于Job的取消操作可以理解为类似线程中的Thread.interrupt(),我们可以通过Job#cancel对job进行取消。
需要特别注意的是默认的delay等都可以被取消的(delay对CancellationException默认的处理方式就是直接中断所有操作达到被取消的目的),但是如果我们自己做一些逻辑操作,或者是select等没有做取消检查,取消是无效的,最简单的方法是检查CoroutineScope#isActive,在coroutine中都可以对其进行访问。 如:
fun main(args: Array) = runBlocking {
val job = launch(CommonPool) {
...
while (isActive) { // 检查是否需要结束当前自旋
...
}
}
...
job.cancel() // 暂停该job
...
}
对父coroutine进行取消,除了取消了coroutine本身,还会影响使用其CoroutineScope#context的子job,但是不会影响使用其他CoroutineContext的job,如:
// 创建一个运行在CommonPool线程池中的Coroutine
val request = launch(CommonPool) {
// 创建一个运行在CommonPool线程池中的coroutine
val job1 = launch(CommonPool) {
println("job1: I have my own context and execute independently!")
delay(1000)
println("job1: I am not affected by cancellation of the request")
}
// 创建一个运行在父CoroutineContext上的coroutine
val job2 = launch(coroutineContext) {
println("job2: I am a child of the request coroutine")
delay(1000)
println("job2: I will not execute this line if my parent request is cancelled")
}
// 让当前coroutine只有在job1与job2完成之前都挂起
job1.join()
job2.join()
}
delay(500)
request.cancel() // 取消
delay(1000) // delay a second to see what happens
println("main: Who has survived request cancellation?")
输出(其中没有使用父coroutineContext的job1不受父coroutine取消的影响):
job1: I have my own context and execute independently!
job2: I am a child of the request coroutine
job1: I am not affected by cancellation of the request
main: Who has survived request cancellation?
4.1 对于Job取消以后的处理
比如对delay之类的suspending期间,被取消了,我们应该如何捕捉到进行相关处理呢,这块可以直接使用try{ ... } finally { ... }进行捕捉处理。
但是需要注意的是,一般来说对于已经取消的Job是无法进行suspending操作的,换句话说,你在上面提到的finnaly { ... }再做suspending相关操作会收到CancellationException的异常。
不过如果非常特殊的情景,需要在已经取消的Job中进行suspending操作,也是有办法的,那就是放到run(NonCancellable) { ... }中执行,如:
fun main(args: Array) = runBlocking {
val job = launch(CommonPool) {
try {
repeat(1000) { i ->
...
}
} finally {
run(NonCancellable) {
...// 在已经取消的Job中
delay(1000L) // 由于是在 run(NonCancellable) { ... }因此依然可以做suspending操作
}
}
}
...
job.cancel() // 取消当前job
...
}
5. 多个CoroutineContext进行+操作
这块具体可以参看CoroutineContext#plus操作实现。
coroutine中支持多个CoroutineContext进行+操作,使得一个coroutine拥有多个CoroutineContext的特性。
5.1 CoroutineContext + CoroutineDispatcher
如果使用+将CoroutineContext与CoroutineDispatcher相加,那么当前Coroutine将运行在CoroutineDispatcher分配的线程中,但是生命周期受CoroutineContext影响,如:
val request = launch(ctx1) {
val job = launch(coroutineCotext + CommonPool) {
// 当前Coroutine运行在CommonPool线程池中,但是如果ctx1被cancel了,当前Coroutine也会被cancel.
delay(1000L)
}
}
request.cancel() // job也会被cancel了。
5.2 CoroutineDispatcher + CoroutineName
当然也可以使用+将CoroutineDispatcher与CoroutineName相加,那么便可以给当前Coroutine命名。
5.3 CoroutineContext + Job
我们可以使用+将CoroutineContext与Job对象相加,使得Job对象可以直接管理其coroutine,如:
val job = Job() // 创建一个Job对象
val coroutines = List(10) {
launch(coroutineContext + job) { // 将运行的CoroutineContext与job相加,使得job对象可以直接控制创建的coroutine
...
}
}
job.cancel() // 会cancel所有与其相加的coroutine
一个比较常见的常见,我们可以为Activity创建一个job,所有需要绑定Activity生命周期的coroutine都加上这个job,在Activity销毁的时候,直接使用这个job.cancel将所有coroutine取消。
6. 对Coroutine进行超时设计
可以在协程方法内,通过withTimeout或者withTimeoutOrNull创建一个一段时间还没有完成便会自动被取消的Coroutine。
其中withTimeout在超时的时候,会抛出继承自CancellationException的TimeoutException,如果超时是被允许的,你可以通过实现try { ... } catch ( e: CancellationException ) { ... }在其中做超时之后的操作(比如释放之类的),或者是直接使用withTimeoutOrNull。
7. 线程安全
通常我们在多个线程同时共享同一个数据的时候,是存在线程安全问题的,如:
// counter 的初始值
var counter = 0
fun main(args: Array) = runBlocking {
// 在CommonPool线程池中执行coutner自增
massiveRun(CommonPool) {
// 每次我们都自增一次coutiner
counter++
}
println("Counter = $counter")
}
suspend fun massiveRun(context: CoroutineContext, action: suspend () -> Unit) {
val n = 1000 // launch的个数
val k = 1000 // 每个coroutine中执行action的次数
val time = measureTimeMillis {
val jobs = List(n) {
launch(context) {
repeat(k) { action() }
}
}
jobs.forEach { it.join() }
}
println("Completed ${n * k} actions in $time ms")
}
上面的案例我们在CommonPool线程池中对counter并行执行了100万次的自增,理论上coutiner最终值应该是1000000,但是由于多线程同时访问,使得该最终值不符合预期:
completed 1000000 actions in 1308 ms
Counter = 680574
7.1 加上volatile
假如我们给coutiner加上volatile呢?
@Volatile
var counter = 0
我们会发现 依然无法保证 这里的线程安全问题,由于volatile变量只能保证对该变量线性的一个读写操作(这块的具体原理可以参考Java Synchronized机制这篇文章)进行保证,这里的案例大量的原子操作是volatile无法保证的:
completed 1000000 actions in 1440 ms
Counter = 676243
7.2 使用同步
private val lock = Any()
fun main(args: Array) = runBlocking {
massiveRun(CommonPool) {
synchronized(lock) {
counter++
}
}
...
}
使用synchronized或是ReentrantLock显然是可以的,虽然操作很小,但是由于高并发的一个线程加锁,使得运行效率极低,全程消耗了11.687s:
completed 1000000 actions in 11687 ms
Counter = 1000000
7.3 使用Mutex进行挂起
val mutex = Mutex()
var counter = 0
fun main(args: Array) = runBlocking {
massiveRun(CommonPool) {
mutex.lock()
try { counter++ }
finally { mutex.unlock() }
}
...
}
类似于Java的ReentrantLock,Mutex不同的是不是采用阻塞,而是采用Coroutine的挂起代替阻塞,在一些场景下是非常实用的,不过在这里并没有想象中那么好,甚至比synchronized阻塞还差很多(48.894s),由于每一个操作都是很小的颗粒度,导致挂起线程资源很难有被利用的场景:
completed 1000000 actions in 48894 ms
Counter = 1000000
7.4 使用线程安全数据结构
private val counter = AtomicInteger()
fun main(args: Array) = runBlocking {
massiveRun(CommonPool) {
counter.incrementAndGet()
}
...
}
其实这个案例的 最佳方案 便是使用支持原子操作incrementAndGet的AtomicInteger来代替线程锁达到线程安全,我们发现保证了线程安全并且只需要需要1.568s左右便完成了通过线程锁需要11.687s的工作(相差了7倍之多!):
completed 1000000 actions in 1568 ms
Counter = 1000000
7.5 使用线程约束这边的并发颗粒度
// 创建一个单线程
val counterContext = newSingleThreadContext("CounterContext")
var counter = 0
fun main(args: Array) = runBlocking {
massiveRun(CommonPool) { // 依然是在CommonPool运行每一个Action
run(counterContext) { // 但是在单线程中运行递增操作
counter++
}
}
...
}
这里我们使用一个单线程的context来约束这个自增操作,这个方案也是可以的,但是 并不可取 ,原因是每一个自增都需要从CommonPool的上下文切换到单线程的上下文,这是累计起来是非常开销的操作,虽然最终的答案符合预期,但是总耗时达到了22.853s之多:
completed 1000000 actions in 22853 ms
Counter = 1000000
7.6 线程合并
val counterContext = newSingleThreadContext("CounterContext")
var counter = 0
fun main(args: Array) = runBlocking {
massiveRun(counterContext) { // 让每一个Action在单线程的Context中运行
counter++
}
...
}
这个其实是一个权衡方案,类似这个案例,本身Action中的所有操作就是存在线程安全的需求,那么考虑不要使用多线程,直接改为单线程操作,结果中规中矩:
completed 1000000 actions in 3113 ms
Counter = 1000000
7.7 使用Actor
sealed class CounterMsg // 这里我们刚好使用sealed class来定义,定义一个CounterMsg
object IncCounter : CounterMsg() // 定义一个用于自增的类型
class GetCounter(val response: CompletableDeferred) : CounterMsg() // 定义一个用户获取结果的类型(这里我们使用CompletableDeferred用于带回结果)
// 这个方法启动一个新的Counter Actor
fun counterActor() = actor(CommonPool) {
var counter = 0
for (msg in channel) { // 不断接收channel中的数据,这个channel是ActorScope的变量
when (msg) {
is IncCounter -> counter++ // 如果是IncCounter类型,我们就自增
is GetCounter -> msg.response.complete(counter) // 如果是GetCounter类型,我们就带回结果
}
}
}
fun main(args: Array) = runBlocking {
val counter = counterActor() // 创建一个Actor
massiveRun(CommonPool) {
counter.send(IncCounter) // action发送自增类型,使得不断执行action不断的触发自增
}
// 创建一个CompletableDeferred用于带回结果
val response = CompletableDeferred()
counter.send(GetCounter(response)) // 发送GetCounter类型带回结果
println("Counter = ${response.await()}") // 输出结果
counter.close() // 关闭actor
}
Actor是一个coroutine的结合,所有的参数可以定义与封装在这个coroutine中,并且通过channel与其他coroutine进行通信,由于Actor本身就是一个coroutine的结合,因此无论Actor运行在哪个CoroutineContext下面,Actor本身都是运行在自己的courtine中并且这是一个顺序执行的coroutine,因此我们可以用它来做线程安全的一些操作,因此在这个案例中这个是可行的,并且由于它始终都运行在同一个coroutine中不需要进行context切换,因此性能比前面提到的Mutex更好。
completed 1000000 actions in 14192 ms
Counter = 1000000
当然对于Actor的使用,这个案例中我们简单的通过编写方法来生成一个Actor,但是复杂的情况最好是封装为一个类。
8. 通信
8.1 Channels
协程中可以通过Channel进行通道模式的在不同coroutine中传递数据,可以发送、接收、关闭等操作,并且对于接收者来说Channel是公平的,也就是先receive的会优先收到send的推送,其余的挂主住等待,而Channel又分有缓冲区的与无缓冲区的。
8.1.1 公平的Channel
对于接收者来说Channel是公平的,也就是先receive的会优先收到send的推送,下面是一个很经典的打乒乓球的例子:
// 申明一个球的类
data class Ball(var hits: Int)
fun main(args: Array) = runBlocking {
val table = Channel() // 创建一个channel作为桌子
launch(coroutineContext) { player("ping", table) } // 选手一,先接球中
launch(coroutineContext) { player("pong", table) } // 选手二,也开始接球
table.send(Ball(0)) // 开球,发出第一个球
delay(1000) // 打一秒钟
table.receive() // 接球,终止在player中的循环发球
}
suspend fun player(name: String, table: Channel) {
for (ball in table) { // 不断接球
ball.hits++
println("$name $ball")
delay(300) // 等待300ms
table.send(ball) // 发球
}
}
输出:
ping Ball(hits=1)
pong Ball(hits=2)
ping Ball(hits=3)
pong Ball(hits=4)
ping Ball(hits=5)
这个案例利用了公平的Channel机制:
| receive队列 | 发送触发者 |
|---|---|
| 选手一 | 桌子 |
| 选手二 | 选手一 |
| 选手一 | 选手二 |
| 选手二 | 选手一 |
| … | … |
| 桌子 | 选手x |
8.1.2 无缓冲区Channel
如果send先执行,会挂起直到有地方receive,如果receive先执行会先挂起直到有地方send,如:
fun main(args: Array) = runBlocking {
// 创建发送Int值的无缓存Channel。
val channel = Channel()
launch(CommonPool) {
// 通过channel发送,将会挂起直到当前值有人接收或者当前Coroutine被cancel
for (x in 1..5) channel.send(x * x)
// 不一定需要关闭,但是使用关闭可以结束当前channel
channel.close()
}
// 接收3个值
repeat(3) { println(channel.receive()) }
// 不断接收剩余的信息
for (y in channel) println(y)
println("Done!")
}
8.1.3 有缓冲区Channel
如果receive先执行并且缓冲区中没有任何数据会先挂起,如果send先执行了,会一直send直到缓冲区满了才挂起(类似BlockingQueue),如:
fun main(args: Array) = runBlocking {
// 创建缓冲区大小为4的Channel
val channel = Channel(4)
launch(coroutineContext) {
repeat(10) {
// 输出正在发送的Int
println("Sending $it")
// 将会执行send直到缓冲区满
channel.send(it)
}
}
// 这里我们不进行接收,只是等待,来验证最多可以缓冲多少个
delay(1000)
}
输出(缓冲了4个,并且尝试发第5个):
Sending 0
Sending 1
Sending 2
Sending 3
Sending 4
8.2 Producer
生产消费者模式,可以创建生产者,以及进行消费调用,如:
// 创建一个生产者方法
fun produceSquares() = produce(CommonPool) {
for (x in 1..5) send(x * x)
}
fun main(args: Array) = runBlocking {
// 得到生产者
val squares = produceSquares()
// 对生产者生产的每一个结果进行消费
squares.consumeEach { println(it) }
}
8.3 Pipeline
管道模式,可以先创造一个生产者,然后对生产结果进行加工,最后对加工结果进行消费调用,如:
// 创建一个生产者,返回的是一个ProducerJob
fun produceNumbers() = produce(CommonPool) {
var x = 1
while (true) send(x++) // infinite stream of integers starting from 1
}
// 创建一个用于加工生产者的生产者(ProducerJob是继承自ReceiveChannel)
fun square(numbers: ReceiveChannel) = produce(CommonPool) {
for (x in numbers) send(x * x)
}
fun main(args: Array) = runBlocking {
val numbers = produceNumbers() // 生产者
val squares = square(numbers) // 加工
for (i in 1..5) println(squares.receive()) // 消费前5个结果
squares.cancel() // cancel加工的coroutine(一般来说是不用主动cancel的,因为协程就好像一个常驻线程,挂起也会被其他任务使用闲置资源,不过大型应用推荐cancel不使用的coroutine)
numbers.cancel() // cancel生产者的coroutine
}
下面是利用pipeline计算前6位素数的案例:
// 创建一个生产者,这里是无限输出递增整数的生产者,并且使用外界传入的context,与初始值
fun numbersFrom(context: CoroutineContext, start: Int) = produce(context) {
var x = start
while (true) send(x++)
}
// 创建方法对生产结果进行加工,这里是计算除数不为零,我们都知道素数是大于1的自然数中除了1和本身无法被其他自然数整除
fun filter(context: CoroutineContext, numbers: ReceiveChannel, prime: Int) = produce(context) {
for (x in numbers) if(x % prime != 0) send(x * x)
}
fun main(args: Array) = runBlocking {
// 创建一个从2开始的自增的生产者
var cur = numbersfrom(context, 2)
for (i in 1..6) {
// 取得当前素数
val prime = cur.receive()
// 输出
println(prime)
// 添加一层过滤
cur = filter(context, cur, prime)
}}
整个计算素数的过程是一直在增加过滤器,抽象的流程如下:
// numbersFrom(2) -> filter(2)
// 2 3%2 != 0 send 3
// -> filter(3)
// 3 4%2 == 0, 5%2 != 0; 5%3 != 0; send 5
// -> filter(5)
// 5 6%2 == 0, 7%2 != 0; 7%3 != 0; 7%5 != 0; send 7
// -> filter(7)
// 7 8%2 == 0, 9%2 != 0; 9%3 == 0;
// 10%2 == 0, 11%2 != 0; 11%3 != 0; 11%5 != 0; 11%7 != 0; send 11
// -> filter(11)
// 11 12%2 == 0, 13%2 != 0; 13%3 != 0; 13%5 != 0; 13%7 != 0; 13%11 != 0; send 13
// 13
上面都是pipeline的一些案例,实际使用过程中,我们通常会用于一些异步的事务处理等。
9. Select
Select可以从多个正在挂起的suspension方法中选择最先结束挂起的。
9.1 对channel消息的接收进行选择其一
我们可以使用select来同时接收多个channel,并且每次只选择第一个到达的channel:
// 每300ms发送一个channel1
fun channel1(context: CoroutineContext) = produce(context) {
while (true) {
delay(300)
send("channel1")
}
}
// 每100ms发送一个channel2
fun channel2(context: CoroutineContext) = produce(context) {
while (true) {
delay(100)
send("channel2")
}
}
// 每次选择先到达的一个
suspend fun selectFirstChannel(channel1: ReceiveChannel, channel2: ReceiveChannel) {
select { // 这里的说明这个select没有产生任何返回值
channel1.onReceive { value ->
println(value)
}
channel2.onReceive { value ->
println(value)
}
}
}
fun main(args: Array) = runBlocking {
val channel1 = channel1(coroutineContext)
val channel2 = channel2(coroutineContext)
repeat(5) {
selectFirstChannel(channel1, channel2)
}
}
输出:
channel2
channel2
channel1
channel2
channel2
可以看到结果是符合预期的,由于receive操作本身如果没有数据到达就会挂起等待,因此通过这种方式,我们可以有效每次只选择先到达的一个,而无需每次都等待所有的channel被send。
上面的案例当channel被close的时候,select会抛异常,我们可以通过onReceiveOrNull让channel被close时,立马接收到null的值来取代抛异常:
suspend fun selectAorB(a: ReceiveChannel, b: ReceiveChannel): String =
select {
a.onReceiveOrNull { value ->
if (value == null)
"Channel 'a' is closed"
else
"a -> '$value'"
}
b.onReceiveOrNull { value ->
if (value == null)
"Channel 'b' is closed"
else
"b -> '$value'"
}
}
fun main(args: Array) = runBlocking {
val a = produce(coroutineContext) {
repeat(4) { send("Hello $it") }
}
val b = produce(coroutineContext) {
repeat(4) { send("World $it") }
}
repeat(8) { // print first eight results
println(selectAorB(a, b))
}
}
输出:
a -> 'Hello 0'
a -> 'Hello 1'
b -> 'World 0'
a -> 'Hello 2'
a -> 'Hello 3'
b -> 'World 1'
Channel 'a' is closed
Channel 'a' is closed
从中可以看到两条结论:
- 当同时有消息过来的时候,优先处理在
select区块中上面的onReceive - 当判断到channl已经close时,会里面返回
null而不会继续进行下一个onReceive处理,如案例中输出了两个Channel 'a' is closed,就是第7次与第8次循环时判读到a.onReceiveOrNull发现a已经close了,因此哪怕b还有消息可以接收也立即在a.onReceiveOrNull中立即返回了null而不继续b的接收处理
下面的案例在同一个select中通过onReceiveOrNull与在onAwait中的receiveOrNull来对async返回的Deferred进行选择:
// 创建一个选择Deferred的生产者
fun switchMapDeferreds(input: ReceiveChannel>) = produce(CommonPool) {
var current = input.receive() // 从获取第一个Deferred开始
while (isActive) { // 循环直到被关闭或者被取消
val next = select?> { // 选择下一个Deferred如果已经关闭便返回null
input.onReceiveOrNull { update ->
update // 如果input中有新的Deferred(这个案例中是通过async返回的Deferred)发送过来便更新为当前的Deferred
}
// 如果在Deferred已经执行完成还没有新的Deferred过来,便会进行下面的操作
current.onAwait { value ->
send(value) // 发送这个Deferred携带的值给当前channel
input.receiveOrNull() // 等待并且从input中接收下一个Deferred,作为返回值
}
}
if (next == null) {
println("Channel was closed")
break // 结束循环
} else {
current = next
}
}
}
// 创建一个async的方法,其返回的是一个Deferred
fun asyncString(str: String, time: Long) = async(CommonPool) {
delay(time)
str
}
fun main(args: Array) = runBlocking {
val chan = Channel>() // 创建一个传递Deferred的channel
launch(coroutineContext) { // 启动一个coroutine用于输出每次的选择结果
for (s in switchMapDeferreds(chan))
println(s)
}
chan.send(asyncString("BEGIN", 100))
delay(200) // 挂起200ms,让在switchMapDeferreds中有足够的时间让BEGIN这个Deferred完成挂起与异步操作
chan.send(asyncString("Slow", 500))
delay(100) // 挂起100ms,让在switchMapDeferreds中没有足够时间让Slow这个Defferred完成挂起与异步操作
chan.send(asyncString("Replace", 100)) // 在上面挂起 100ms毫秒以后,立马发送这个Replace的
delay(500) // 挂起500ms 让上面的async有足够时间
chan.send(asyncString("END", 500))
delay(1000) // 挂起500ms 让上面的async有足够时间
chan.close() // 关闭channel
delay(500) // 延缓500ms让switchMapDeferreds有足够的时间输出'Channel was closed'
}
输出:
BEGIN
Replace
END
Channel was closed
9.2 对channel消息的发送进行选择其一
我们可以使用select来同时管理多个channel的发送,并且每次只选择第一个有人在接收的channel:
fun produceNumbers(side: SendChannel) = produce(CommonPool) {
for (num in 1..10) { // 产生从1到10 10个数字
delay(100) // 每100ms选择一个发送
select {
// 哪个channel先有人接收,哪个将会被发送出去,另一个会被丢弃
onSend(num) {} // 发送给当前channel
side.onSend(num) {} // 或者发送给side channel
}
}
}
fun main(args: Array) = runBlocking {
val side = Channel() // 创建一个side channel,用于发送Int数据
launch(coroutineContext) { // 创建一个快速接收side数据的消费者coroutine
side.consumeEach { println("Side channel has $it") }
}
// 主channel每250ms接收一个数据
produceNumbers(side).consumeEach {
println("Consuming $it")
delay(250)
}
println("Done consuming")
}
输出:
Consuming 1
Side channel has 2
Side channel has 3
Consuming 4
Side channel has 5
Side channel has 6
Consuming 7
Side channel has 8
Side channel has 9
Consuming 10
Done consuming
总的来说,Kotlin的协程可以应用的场景非常的宽泛,也非常的实用,从对线程阻塞这块资源利用的出发点,衍生出各种各样的实用场景,如果能够灵活使用,将能编写出更优质,更高效的代码,本文只是通过Kotlinx.coroutines的教程进行了解读,更多的细节需要通过实践来挖掘,欢迎大家多实践,多拍砖。
为了方便理解笔者准备了一个App
| 扫码下载 | 示例图 |
 |
 |
源码地址
https://download.csdn.net/download/qq_20330595/11266597
下载分数无法设置免费,要源码的可以私聊。