SparkSQL实战7——综合实战完成日志分析3
需求:按地市统计主站最受欢迎的TopN课程
//按照地市进行统计TopN课程
def cityAccessTopNStat(spark:SparkSession,accessDF:DataFrame):Unit = {
//使用DataFrame方式进行统计
import spark.implicits._
val cityAccessTopNDF = accessDF.filter($"day" === "20170511" && $"cmsType" === "video")
.groupBy("day","city","cmsId").agg(count("cmsId").as("times"))
//cityAccessTopNDF.show(false)
//Window函数在SparkSQL中的使用
cityAccessTopNDF.select(cityAccessTopNDF("day"),
cityAccessTopNDF("city"),
cityAccessTopNDF("cmsId"),
cityAccessTopNDF("times"),
row_number().over(Window.partitionBy(cityAccessTopNDF("city"))
.orderBy(cityAccessTopNDF("times").desc)).as("times_rank")
).filter("times_rank <= 3").show(false) //实际上是top3
}
打印输出:
+--------+----+-----+-----+----------+
|day |city|cmsId|times|times_rank|
+--------+----+-----+-----+----------+
|20170511|北京市 |14540|22270|1 |
|20170511|北京市 |4600 |11271|2 |
|20170511|北京市 |14390|11175|3 |
|20170511|浙江省 |14540|22435|1 |
|20170511|浙江省 |14322|11151|2 |
|20170511|浙江省 |14390|11110|3 |
|20170511|广东省 |14540|22115|1 |
|20170511|广东省 |14623|11226|2 |
|20170511|广东省 |14704|11216|3 |
|20170511|上海市 |14540|22058|1 |
|20170511|上海市 |14704|11219|2 |
|20170511|上海市 |4000 |11182|3 |
|20170511|安徽省 |14540|22149|1 |
|20170511|安徽省 |14390|11229|2 |
|20170511|安徽省 |14704|11162|3 |
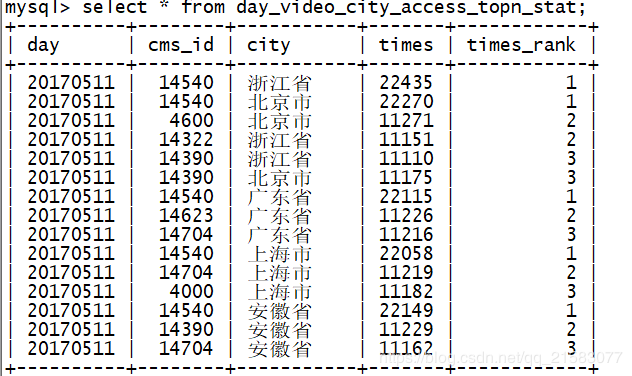
+--------+----+-----+-----+----------+将统计结果写入到MySQL中去:
创建一张表:
create table day_video_city_access_topn_stat(
day varchar(8) not null,
cms_id bigint(10) not null,
city varchar(20) not null,
times bigint(10) not null,
times_rank int not null,
primary key (day,cms_id,city)
);新建一个实体类DayCityVideoAccessStat:
case class DayCityVideoAccessStat(day:String, cmsId:Long, city:String,times:Long,timesRank:Int)在StatDAO里面添加一个方法,用来批量保存DayCityVideoAccessStat到数据库。
/**
* 批量保存DayCityVideoAccessStat到数据库
*/
def insertDayCityVideoAccessTopN(list: ListBuffer[DayCityVideoAccessStat]): Unit = {
var connection: Connection = null
var pstmt: PreparedStatement = null
try {
connection = MySQLUtils.getConnection()
connection.setAutoCommit(false) //设置手动提交
val sql = "insert into day_video_city_access_topn_stat(day,cms_id,city,times,times_rank) values (?,?,?,?,?) "
pstmt = connection.prepareStatement(sql)
for (ele <- list) {
pstmt.setString(1, ele.day)
pstmt.setLong(2, ele.cmsId)
pstmt.setString(3, ele.city)
pstmt.setLong(4, ele.times)
pstmt.setInt(5, ele.timesRank)
pstmt.addBatch()
}
pstmt.executeBatch() // 执行批量处理
connection.commit() //手工提交
} catch {
case e: Exception => e.printStackTrace()
} finally {
MySQLUtils.release(connection, pstmt)
}
}修改cityAccessTopNStat:
//Window函数在SparkSQL中的使用
val top3DF = cityAccessTopNDF.select(cityAccessTopNDF("day"),
cityAccessTopNDF("city"),
cityAccessTopNDF("cmsId"),
cityAccessTopNDF("times"),
row_number().over(Window.partitionBy(cityAccessTopNDF("city"))
.orderBy(cityAccessTopNDF("times").desc)).as("times_rank")
).filter("times_rank <= 3") //.show(false) //实际上是top3
//将统计结果写入到MySQL数据库
try{
top3DF.foreachPartition(partitionOfRecords => {
val list = new ListBuffer[DayCityVideoAccessStat]
partitionOfRecords.foreach(info => {
val day = info.getAs[String]("day")
val cmsId = info.getAs[Long]("cmsId")
val city = info.getAs[String]("city")
val times = info.getAs[Long]("times")
val timesRank = info.getAs[Int]("times_rank")
list.append(DayCityVideoAccessStat(day,cmsId,city,times,timesRank))
})
StatDAO.insertDayCityVideoAccessTopN(list)
})
}catch {
case e : Exception => e.printStackTrace()
}
}小插曲:SecureCRT连接MySQL查询的时候,有汉字,汉字显示可能会有乱码,我的一开始就是显示的是????,我的解决办法是首先 建库和建表的时候就指定字符集和编码,然后客户端连接时可以指定字符集:mysql --default-character-set=utf8 -uroot -p
验证: