【小目标检测】Group Sampling for Scale Invariant Face Detection
了解一些基础内容:
FPN(Feature Pyramid network)?
参考:https://blog.csdn.net/weixin_40683960/article/details/79055537
RPN(Region Proposal Network)?
论文解析参考:https://blog.csdn.net/u014380165/article/details/101418816
论文链接:http://openaccess.thecvf.com/content_CVPR_2019/papers/Ming_Group_Sampling_for_Scale_Invariant_Face_Detection_CVPR_2019_paper.pdf
《Group Sampling for Scale Invariant Face Detection》
(对于人脸检测的不同尺度的分组采样)
出处:西安交通大学 微软亚洲研究院
作者的主要思想
之前的网络结构FPN和SSD,通常使用多个layer的不同空间精度预测不同规模的目标,简言之,高精度图预测小目标;作者发现没有必要使用多个layer来预测不同规模的人脸,关键是要均衡不同规模的正样例和负样例的数量,作者就提出了分组采样方法(a group sampling method),该方法基于不同规模(scale)将所有anchor分为若干组,确保在训练过程中每组的采样数量都是相同的。在使用过程中使用最后一层的FPN作为feature。(常见方法多关心类别间的不均衡,没有留意过样例的均衡性,因而该想法比较新颖)
Motivation:Scale Imbalance Distribution(动机:不均衡的规模(scale)分布)
以Resnet50的网络结构为例,图三简单的分析了网络结构:
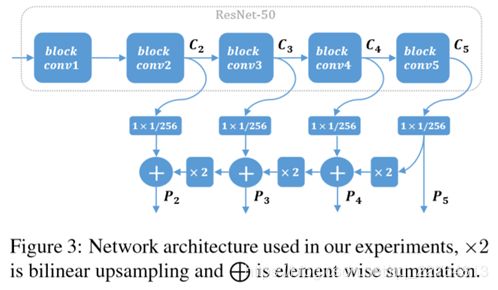
图3中网络结构包含5个卷积块,其中conv2(C2),conv3(C3),conv4(C4),conv5(C5)分别进行1*1的卷积进行变通道数后,和上采样操作后,对不同特征层进行特征融合;anchor scale为{16,32,64,128},aspect ratio = 1,最终的输出特征图分别为{P2,P3,P4,P5}。
使用图3比较了5种不同类型的检测器:
- RPN:C4作为预测层,所有anchor除以尺度16(titled with stride 16 pixels)
- FPN:{P2,P3,P4,P5}作为检测层,anchor scale为{16,32,64,128},特征步长为{4,8,16,32};
- FPN-finest-stride:所有的anchor都是出自P2,特征步长为{4,8,16,32},anchor scale为{16,32,64,128};
- FPN-finest:所有的anchor都是出自P2,每个anchor的步长为4;
- FPN-finest-sample:和FPN-finest参数设定相同,另外使用了分组采样方法均衡不同规模的训练样例。
具体参数细节查看图1
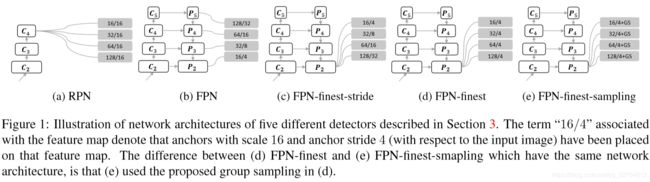
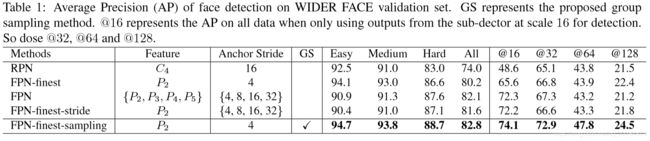

通过以上5个不同检测器的对比实验得出结论如下:
1.使用多个layer的feature(对于预测小目标)作用不大:查看图1中的(b)和(c),二者的区别在于FPN使用多层layer,而FPN-finest-stride使用单层layer。查看表1,发现二者AP值几乎相同。这里实验证明FPN之所以有效,并不是预测的特征层数量增加导致的,而是深层和浅层的特征融合。其实这点也体现在SSD上,SSD也是基于多个特征层进行预测,但是没有做高层和浅层的特征融合,所以SSD对小尺寸目标检测效果不怎么好,结合Figure2,FPN和FPN-finest-stride在样例分布上几乎相同。
2.规模(scale)不均衡分布影响较大:通过比较FPN-finest-stride和FPN-finest,FPN-finest设定的步长都是4。(Table 1)FPN-finest在Easy和medium上面的ap值是优于FPN-finest-stride;(Figure 2)FPN-finest中拥有更多大anchor,当步长是16时,FPN-finest的样本量少于FPN-finest-stride的样本量,可以明显发现在Hard目标预测时,FPN-finest-stride在Hard目标预测结果ap值明显更好;
通过以上的实验分析,作者提出使用分组采样进行样本量规模均衡,实验结果中样本均衡后如Figure2中的图e一样,当样本均衡后,相应模型表现与其他四种方法相比较,效果最好(Table1中的FPN-finest-sampling)。
Group Sampling Method
1.anchor matching strategy
两步走策略(two-pass policy):
首先使用anchor去匹配所有ground truth box,并赋予正负样本标签。但是有些ground-truth可能找不到匹配的anchor,此时进行第二步,为没有找到可以匹配anchor的ground-truth进行anchor匹配。
具体操作如下:
所有参数:Anchor集合为![]() ,是anchor的索引i,n是anchor的总量。Ground truth box集合
,是anchor的索引i,n是anchor的总量。Ground truth box集合![]() ,j是ground truth的索引,m是ground truth的总量。在匹配过程中,匹配矩阵为:
,j是ground truth的索引,m是ground truth的总量。在匹配过程中,匹配矩阵为:![]() ;
;
第一步:为每一个anchor 匹配所有的ground-truth,找到最大的IoU.记作: ,基于以下公式赋予标签:
,基于以下公式赋予标签:
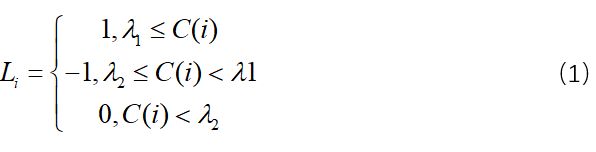
![]() 是预设的阈值(实验中:
是预设的阈值(实验中:![]() ),1:正样本标签;0:负样本标签;-1:此标签在训练中,忽略相应的anchor;
),1:正样本标签;0:负样本标签;-1:此标签在训练中,忽略相应的anchor;
第二步:在第一步操作中有一些ground truth box没有找到匹配的anchor。假设没有被匹配的ground truth box ,寻找出的anchor满足以下三点条件:
1)anchor没有和任何ground truth box进行过匹配;
2)![]() ;
;
3) ;
;
2.Group Sampling(分组采样)
通常在训练样本中有两种不均衡情况:
- 正负样本不均衡
- 不同规模(scale)中样例不均衡,给予匹配策略,小目标的ground truth box很难找到匹配的anchor。
之前的关注点都在第一种情况,通常将正负样本比例设定为1:3。但是忽略了第二种不均衡情况。作者提出了分组采样,将所有样本基于scale大小来分组,所以每组中的样本sacle是一样的。然后再进行训练采样时,保持每组取出的数据量是一样的,同时保证每组的正负样本比例为1:3。当某组中无法按照1:3的比例取出特定量的样例时,就使用负样本进行补充。
使用数学公式表示如下
正样本:![]() ;负样本:
;负样本:![]() ;
;![]() ,总量N是一个常量,且
,总量N是一个常量,且![]()
Training Process
Loss function:分类依然使用softmax loss,回归使用Iou least loss:
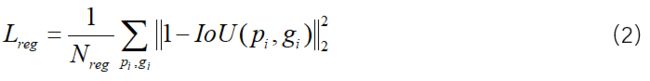
Experiments
The effect of the number of training samples
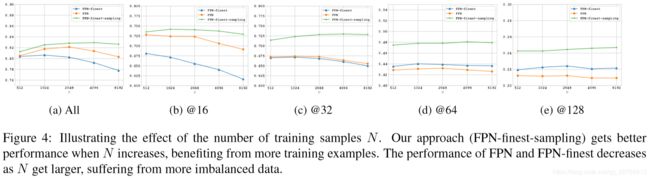
结论:1)随着训练样本N的数量增加,性能也得到提升。2)当N=2048时,性能提升得到饱和。
The effect of the proposed loss
实验结果如表3:
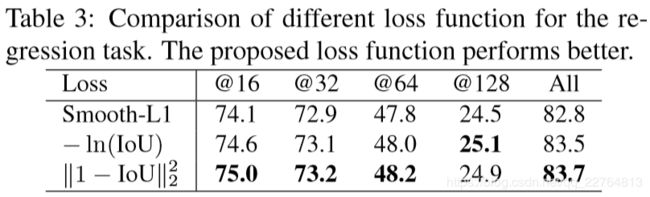
实验结果表明作者提出的loss函数可以有效提升预模型性能。
Comparison with OHEM and Focal Loss

通过实验发现作者的方法在ROC曲线上性能最好。
结论:作者从独特的视角进行观察,找到小目标检测不到的根本原因,以及相应的解决方法,最终得到分组采样算法和lease square IoU loss函数;