5.指针碰撞与空闲列表,CMS与其他GC对比
new对象时堆内存的分配方式有两种模式,
指针碰撞
把指针向空闲对象移动与对象占用内存大小相等的距离
空闲列表
虚拟机维护一个列表,记录可用的内存块,分配给对象列表中一块足够大的内存空间
显然,采用何种方式要基于虚拟机堆内存是否规整,这又由采用的垃圾收集器是否带有压缩整理功能决定,所以类似Serial、ParNes等收集器时采用指针碰撞,而采用CMS这种基于Mark-Sweep算法的收集器时采用空闲列表。
CMS(Concurrent Mark-Sweep)
CMS(Concurrent Mark-Sweep)是以牺牲吞吐量为代价来获得最短回收停顿时间的垃圾回收器。对于要求服务器响应速度的应用上,这种垃圾回收器非常适合。CMS是用于对tenured generation的回收,也就是年老代的回收,目标是尽量减少应用的暂停时间,减少full gc发生的几率,利用和应用程序线程并发的垃圾回收线程来标记清除年老代。在启动JVM参数加上-XX:+UseConcMarkSweepGC ,这个参数表示对于老年代的回收采用CMS。CMS采用的基础算法是:标记—清除。
CMS垃圾收集过程
- **初始标记(STW initial mark) 暂停应用
- 并发标记(Concurrent marking)
- 并发预清理(Concurrent precleaning)
- 重新标记(STW remark) 暂停 应用
- 并发清理(Concurrent sweeping)
- 并发重置(Concurrent reset)**
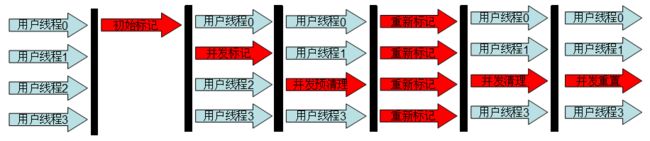
初始标记 :在这个阶段,需要虚拟机停顿正在执行的任务,官方的叫法STW(Stop The Word)。这个过程从垃圾回收的"根对象"开始,只扫描到能够和"根对象"直接关联的对象,并作标记。所以这个过程虽然暂停了整个JVM,但是很快就完成了。
并发标记 :这个阶段紧随初始标记阶段,在初始标记的基础上继续向下追溯标记。并发标记阶段,应用程序的线程和并发标记的线程并发执行,所以用户不会感受到停顿。
并发预清理 :并发预清理阶段仍然是并发的。在这个阶段,虚拟机查找在执行并发标记阶段新进入老年代的对象(可能会有一些对象从新生代晋升到老年代, 或者有一些对象被分配到老年代)。通过重新扫描,减少下一个阶段"重新标记"的工作,因为下一个阶段会Stop The World。
重新标记 :这个阶段会暂停虚拟机,收集器线程扫描在CMS堆中剩余的对象。扫描从"跟对象"开始向下追溯,并处理对象关联。
并发清理 :清理垃圾对象,这个阶段收集器线程和应用程序线程并发执行。
并发重置 :这个阶段,重置CMS收集器的数据结构,等待下一次垃圾回收。
CMS缺点
CMS回收器采用的基础算法是Mark-Sweep。所有CMS不会整理、压缩堆空间。这样就会有一个问题:经过CMS收集的堆会产生空间碎片。 CMS不对堆空间整理压缩节约了垃圾回收的停顿时间,但也带来的堆空间的浪费。为了解决堆空间浪费问题,CMS回收器不再采用简单的指针指向一块可用堆空 间来为下次对象分配使用。而是把一些未分配的空间汇总成一个列表,当JVM分配对象空间的时候,会搜索这个列表找到足够大的空间来hold住这个对象。
需要更多的CPU资源。从上面的图可以看到,为了让应用程序不停顿,CMS线程和应用程序线程并发执行,这样就需要有更多的CPU,单纯靠线程切 换是不靠谱的。并且,重新标记阶段,为空保证STW快速完成,也要用到更多的甚至所有的CPU资源。当然,多核多CPU也是未来的趋势!
CMS的另一个缺点是它需要更大的堆空间。因为CMS标记阶段应用程序的线程还是在执行的,那么就会有堆空间继续分配的情况,为了保证在CMS回 收完堆之前还有空间分配给正在运行的应用程序,必须预留一部分空间。也就是说,CMS不会在老年代满的时候才开始收集。相反,它会尝试更早的开始收集,已 避免上面提到的情况:在回收完成之前,堆没有足够空间分配!默认当老年代使用68%的时候,CMS就开始行动了。 – XX:CMSInitiatingOccupancyFraction =n 来设置这个阀值。
总得来说,CMS回收器减少了回收的停顿时间,但是降低了堆空间的利用率。
什么时候使用CMS
如果你的应用程序对停顿比较敏感,并且在应用程序运行的时候可以提供更大的内存和更多的CPU(也就是硬件牛逼),那么使用CMS来收集会给你带来好处。还有,如果在JVM中,有相对较多存活时间较长的对象(老年代比较大)会更适合使用CMS。
以上参考:https://blog.csdn.net/wfh6732/article/details/57490195?utm_source=itdadao&utm_medium=referral
各种GC比较
- 串行收集器Seiral Collector
串行收集器是最简单的,它设计为在单核的环境下工作(32位或者windows),你几乎不会使用到它。它在工作的时候会暂停整个应用的运行,因此在所有服务器环境下都不可能被使用。
使用方法:-XX:+UseSerialGC
- 并行/吞吐优先收集器Parallel/Throughput Collector
这是JVM默认的收集器,跟它名字显示的一样,它最大的优点是使用多个线程来扫描和压缩堆。缺点是在minor和full GC的时候都会暂停应用的运行。并行收集器最适合用在可以容忍程序停滞的环境使用,它占用较低的CPU因而能提高应用的吞吐(throughput)。
使用方法:-XX:+UseParallelGC
- CMS收集器CMS Collector
接下来是CMS收集器,CMS是Concurrent-Mark-Sweep的缩写,并发的标记与清除。这个算法使用多个线程并发地(concurrent)扫描堆,标记不使用的对象,然后清除它们回收内存。在两种情况下会使应用暂停(Stop the World, STW):1. 当初次开始标记根对象时initial mark。2. 当在并行收集时应用又改变了堆的状态时,需要它从头再确认一次标记了正确的对象final remark。
这个收集器最大的问题是在年轻代与老年代收集时会出现的一种竞争情况(race condition),称为提升失败promotion failure。对象从年轻代复制到老年代称为提升promotion,但有时侯老年代需要清理出足够空间来放这些对象,这需要一定的时间,它收集的速度可能赶不上不断产生的要提升的年轻代对象的速度,这时就需要做STW的收集。STW正是CMS想避免的问题。为了避免这个问题,需要增加老年代的空间大小或者增加更多的线程来做老年代的收集以赶上从年轻代复制对象的速度。
除了上文所说的内容之外,CMS最大的问题就是内存空间碎片化的问题。CMS只有在触发FullGC的情况下才会对堆空间进行compact。如果线上应用长时间运行,碎片化会非常严重,会很容易造成promotion failed。为了解决这个问题线上很多应用通过定期重启或者手工触发FullGC来触发碎片整理。
对比并行收集器它的一个坏处是需要占用比较多的CPU。对于大多数长期运行的服务器应用来说,这通常是值得的,因为它不会导致应用长时间的停滞。但是它不是JVM的默认的收集器。
使用CMS需要仔细分析自己的应用对象生命周期,尤其是在应用要求高性能,高吞吐。需要仔细分析自己应用所需要的heap大小,老年代,新生代的分配比例,以及survival区的大小。设置不合理会很容易造成性能问题。后续会有专门的文章来介绍。
使用方法:-XX:+UseConcMarkSweepGC,此时可同时使用-XX:+UseParNewGC将并行收集作用于年轻代,新的JVM自动打开这一配置
- G1收集器Garbage First Collector
如果你的堆内存大于4G的话,那么G1会是要考虑使用的收集器。它是为了更好支持大于4G堆内存在JDK 7 u4引入的。G1收集器把堆分成多个区域,大小从1MB到32MB,并使用多个后台线程来扫描这些区域,优先会扫描最多垃圾的区域,这就是它名称的由来,垃圾优先Garbage First。
如果在后台线程完成扫描之前堆空间耗光的话,才会进行STW收集。它另外一个优点是它在处理的同时会整理压缩堆空间,相比CMS只会在完全STW收集的时候才会这么做。
使用过大的堆内存在过去几年是存在争议的,很多开发者从单个JVM分解成使用多个JVM的微服务(micro-service)和基于组件的架构。其他一些因素像分离程序组件、简化部署和避免重新加载类到内存的考虑也促进了这样的分离。
除了这些因素,最大的因素当然是避免在STW收集时JVM用户线程停滞时间过长,如果你使用了很大的堆内存的话就可能出现这种情况。另外,像Docker那样的容器技术让你可以在一台物理机器上轻松部署多个应用也加速了这种趋势。
使用方法:-XX:+UseG1GC
Java 8和G1收集器
G1收集器在Java 8 u20上最漂亮的优化是String去重(String Deduplication)。String对象和它内部使用的char[]数组会占用比较多的内存,因此优化过的G1收集器会把重复的String对象指向同一个char[]数组,避免多个副本存在在堆里。可以使用-XX:+UseStringDeduplication参数来打开这一功能。