Spark SQL介绍和DataFrame概念以及其API的应用示范(详细全面)
Spark SQL介绍:
Spark SOL是用于结构化数据、半结构化数据处理的Spark高级模块,可用于从各种结构化数据源,例如JISON (半结构化)
文件、CSV文件、ORC文件(ORC文件格式是一种Hive的文件存储格式,可以提高Hive表的读、写以及处理数据的性能)、
Hive表、Parquest文件(新型列式存储格式,具有降低查询成本、高效压缩等优点,广泛用于大数据存储、分析领域)中读取
数据,然后在Spark程序内通过SQL语句对数据进行交互式查询,进而实现数据分析需求,也可通过标准数据库连接器
(JDBC/ODBC)连接传统关系型数据库,取出并转化关系数据库表,利用Spark SQL进行数据分析。
这里解释一下结构化数据:
结构化数据是指记录内容具有明确的结构信息且数据集内的每一条记录都符合结构规范的数据集合,是由二维表结构
来逻辑表达和实现的数据集合。可以类比传统数据库表来现解该定义,所谓的“明确结构”即是由预定义的表头(Schema)
表示的每一条记录由哪些字段组成以及各个字段的名称、类型、属性等信息。
Spark SQL的实现:
若需处理的数据集是典型结构化数据源,可在Spank程序中引入Spark SQL模块,首先读取待处理数据并将其转化为
Spark SQL的核心数据抽象---DataFrame,进而调用DataFrame API来对数据进有分析处理,也可以将DataFrame注册成表,
直接使用SQL语句在数据表上进行交互式查询。
DataFrame:
DataFrame的定义与RDD类似,即都是Spark 平台用以分布式并行计算的不可变分布式数据集合。与RDD最大的不同在于,
RDD仅仅是一条条数据的集合,并不了解每条数据的内容是怎样的,而DataFrame明确的了解何条数据有几个 命名字段组成,
即可以形象地理解为RDD是条条数据组成的一维表,面DataFrame 是何行数据 都有共同清晰的列划分的维表,每一行的内容
的Row对象组成DF。
概念上来说,它和关系型数据库的表或者R和Python中data frame 等价,只不过DataFrame在底层实现了更多优化。
从编程角度来说,DataFrame 尼Spark SQL模块所需处理的结构化数据的核心抽象,即在Spark程序中若想要使用简易的SQL
接口对数据进行分析,首先需型将所处理数据源转化为DataFrame对象,进而在DataFrame对象上调用各神API来实现需求,
DataFrame 可以从许乡结构化数据源加载并构造得到,如结构化数据文件,Hive中的表,外部数据库,已有的DataFrame API
支持多种高级程序讲言Scala、Java、 Python 和R,
DataFrame与RDD的区别:
RDD和DalaFrame均为Spark平台对数据的一种抽象,一 种组织方式,但是两者的地位或者说设计目的却截然不同。
RDD是整个Spark平台的存储、计算以及任务调度的逻辑基础,更具有通用性,适用于各类数据源,而DataFrame是只针对
结构化数据源的高层数据抽象,其中在DataFrame对象的创建过程中必须指定数据集的结构信息(Schema),所以DataFrame
生来便具有专用性的数据抽象,只能读取具有鲜明结构的数据集。
下图直观地体现了DataFrame 和RDD的区别。左侧的RDDIPerson]虽然以Person类为类型参数,但Spark平台本身并不了解
Person 类的内部结构。而右侧的DataFrame却提供了详细的结构信息,使得Spark SQL可以清楚地知道该数据集中包含哪些列,
每列的名称和类型各是什么。DataFrame 多了数据的结构信息,即schema. RDD是分布式的Java 对象的集合,DalaFrame
则是分布式的Row对象的集合。DataFrame除了提供了比RDD更丰富的算子操作以外,更重要的特点是利用已知的结构信息
来提升执行效率、减少数据读取以及执行计划的优化,比如filter下推、裁剪等。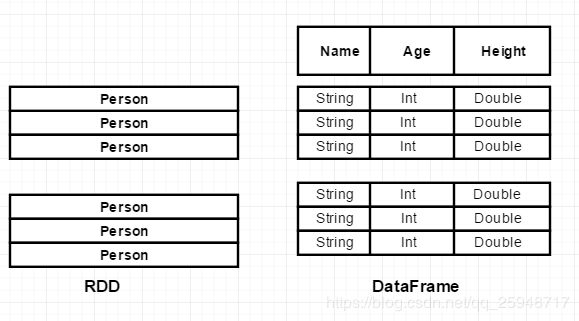
Spark SQL模块的编程主入口点是SparkSession, SparkSession 对象不仅为用户提供了创建DataFrame对象、读取外部
数据源并转化为DataFrame对象以及执行sql查询的API,还负责记录着用户希望Spark应用如何在Spark集群运行的控制、
调优参数,是Spark SQL的上下文环境,是运行的基础。
DataFrame提供了一套丰富的API,让Spark变得更加平易近人,使得大数据分析的开发越来越容易。DataFrame API 将
关系型的处理与过程型处理结合起来,可以对外部数据源(Hive、JSON 等)和Spark内建的分布式集合(RDD)进行关系型操作。
DataFrame能处理的外部数据源,除了内置的Hive、JSON、 Parquet、JDBC以外,还包括CSV、Avro、HBase等多种数据
源,Spark SQL多元一体的结构化数据处理能力正在逐渐释放。DataFrame 数据采用压缩的列式存储,对DataFrame的操作采用
Catalyst一种关系操作优化器(也称为查询优化器),因此效率更高。
======================================================================================
本节读取电影票房收人的数据文件,生成名为film的DataFrame,对读DataFrame应用各种Spark算子进行计算。
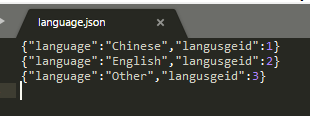
首先准备数据。模拟生成电影票房收人的数据文件film. json、newFilm. json,从本地上传到Hdfs文件系统中,电影票房收人
文件的格式包括6列:票房收人、制片地区、影片ID、语言代码、影片名、上映年份。电影票房收人的数据文件内容如下:
生成数据的程序见:https://blog.csdn.net/qq_25948717/article/details/83113861

加载数据:

导入数据文件:
将film对象赋值给df(DataFrame)
1.collect():返回一个数组,包含DataFrame中全部数据记录
collectAsList():返回一个java list,包含DataFrame中全部数据记录
因为这两个方法是将集群中的目标变量的所有数据取回到一个结点当中,所以当你的单台结点的内存不足以放下DataFrame
中包含的数据时就会出错。因此,collec()、 collectAsList()不适用于特别大规模的数据集。

2. count:返回DataFrame的记录条数

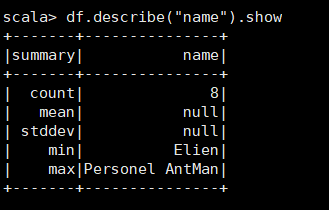
3.describe:描述性统计:计数,平均值,标准差,max,min
4.first head

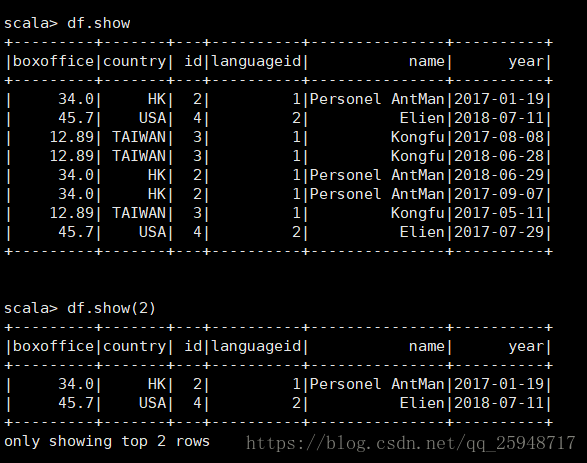
5.show
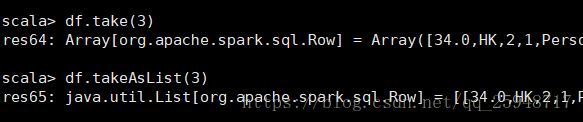
6.take
7.cache 将DataFrame缓存到内存中

8.cloumns、dtypes

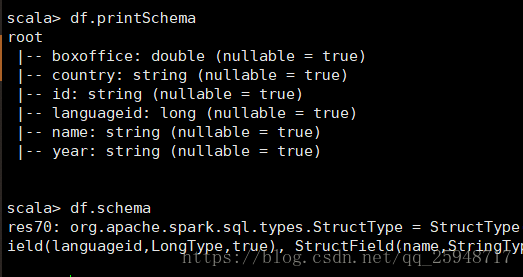
9.printSchma、schema
10.registerTempTable:将DataFrame注册为临时的表,注册成表后可用sql方法查询

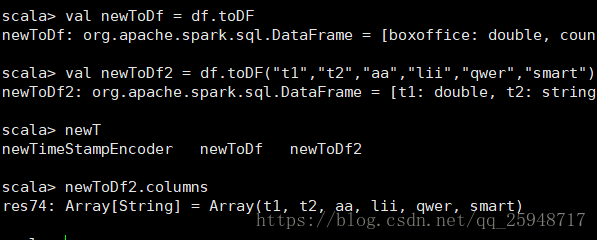
11.toDF 不带参返回它本身,带参的时候重命名了列名
12.persist()、unpersist() :将DataFrame以指定等级持久化内存和磁盘中。
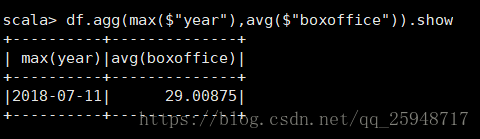
13.agg:聚合操作
DataFrame不需要经过group就可以执行统计操作
统计最大年份的平均票房收入

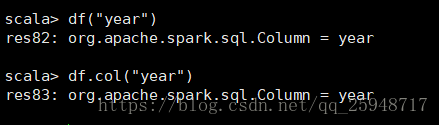
14.apply:根据指定列名返回列
15.dinstinct:去掉重复的记录
dropDuplicates:根据指定字段(可多个字段组合)去重


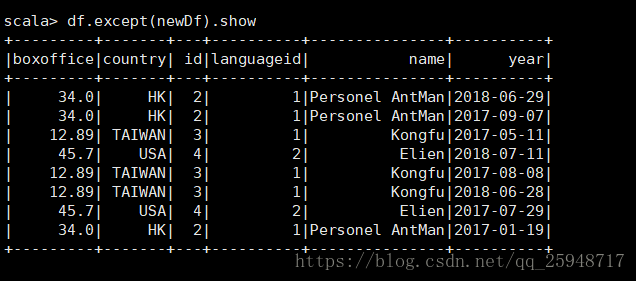
16.except:两个DF做减法
17.filter:过滤

18.groupBy:使用一个或者多个列对DataFrame进行分组
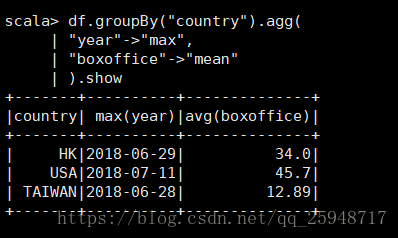
19.intersect(将两个DF同时存在的数据返回),join
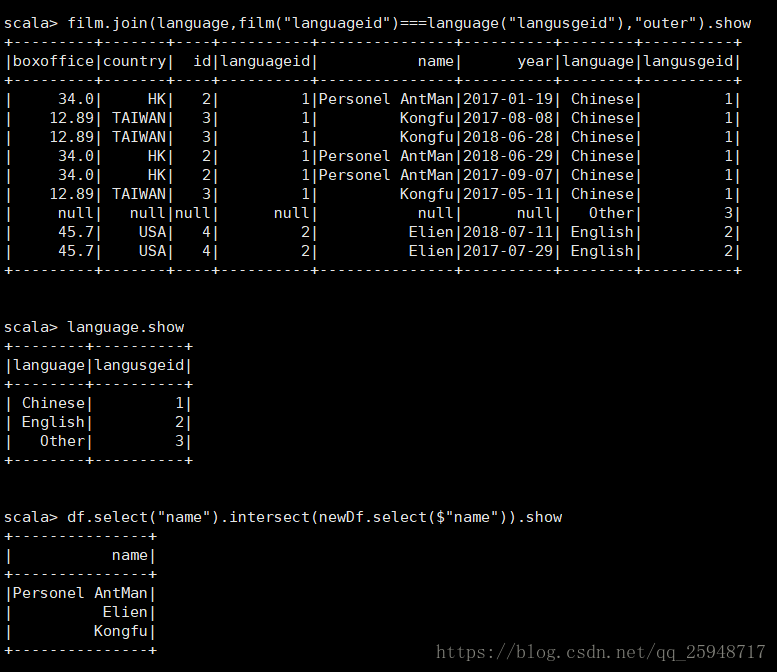
20.limit

20.sort,orderBy(sort的别名):

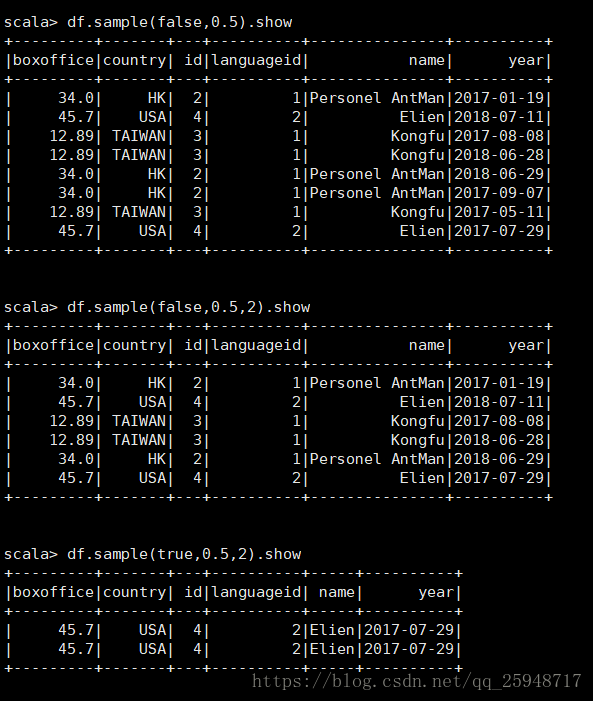
21.sample取样
sanple(withReplacement:Boolean,fraction:Double,seed:Long)
withReplacement=true表示重复抽样,fraction表示比例,seed指定因子抽样
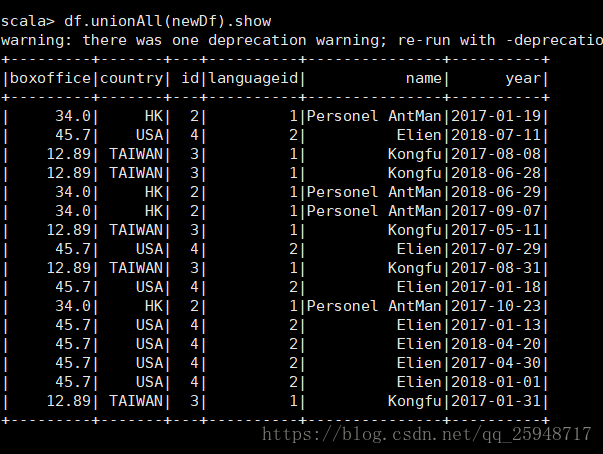
22.select、unionAll

23.withColumn和withColumnRenamed

24.foreach:对DF中的数据记录进行遍历处理
map:将DF按照指定函数生成一个新的RDD

25.注册表,然后用sql查询
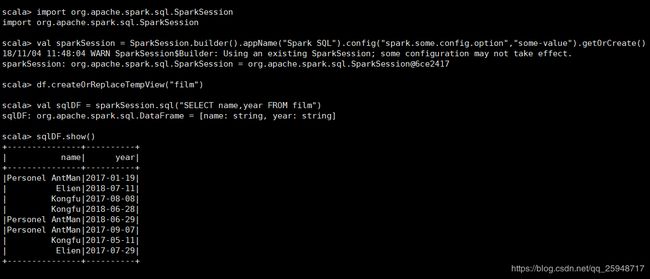
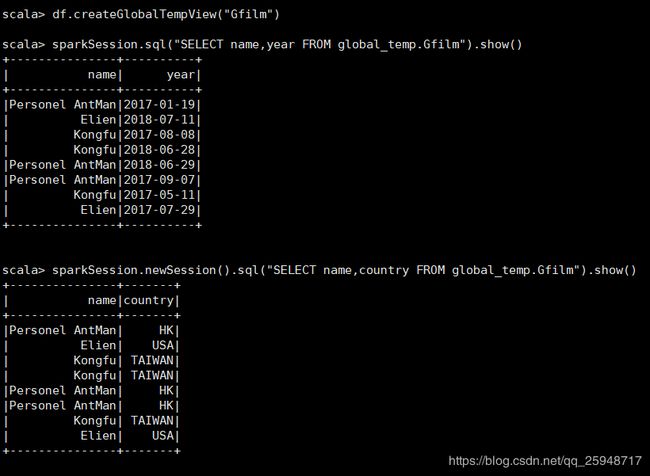
26.全局临时表
全局临时表(global temporary view)于临时表(temporay view)是相对的,全局临时表的作用范围是某个Spark应用程序内所有
会话(SparkSession),它会持续存在,在所有会话中共享,直到该Spark应用程序终止
因此,若在同一个应用中不同的session中需重用一个临时表, 不妨将其注册为全局临时表,可避免多余IO,提高系统执行
效率,当然如果某个临时表只在整个应用中的某个session中需使用,仅需注册为局部临时表,避免不必要的在内存中存储
全局临时表
另外,全局临时表与系统保留的数据库global temp相关联,引用时需用global temp标识,
例如: SELECT * FROM global temp.viewl。
下案列中可见new的session依然可以访问全局临时表:
27.where

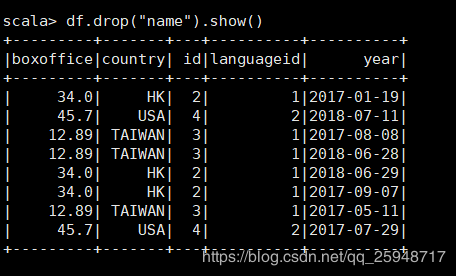
28.drop
29.groubBy

30.jion操作:
单字段:df1.join(df2,"name").show()
多字段:df1.join(df2,Seq("id","name"))
指定join的类型:df1.join(df2,Seq("id","name"),“right_outer”)
使用Column类型来join:df1.join(df2,df1("xxx")===df2("yyy")).show()
使用Column类型来join时指定类型:df1.join(df2,df1("xxx")===df2("yyy"),"cross").show()
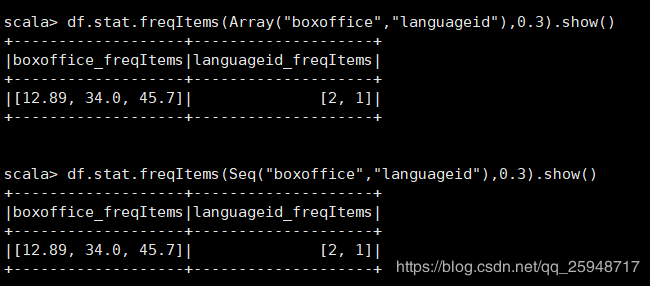
31.stat:计算指定字段或者指定字段之间的统计信息
统计该字段值出现频率在30%以上的内容
corr求两列的相关性,cov求两列的协方差

32.df.na.drop().show(5):具有空值列的行数据都会被删除
df.na.drop(Array("xxx")).show():指定某列的行数据被删除